【**系统版本 **】CentOS Linux release 7.5.1804 (Core)
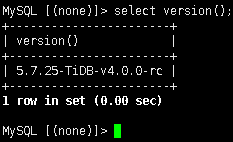
【 TiDB 版本 】
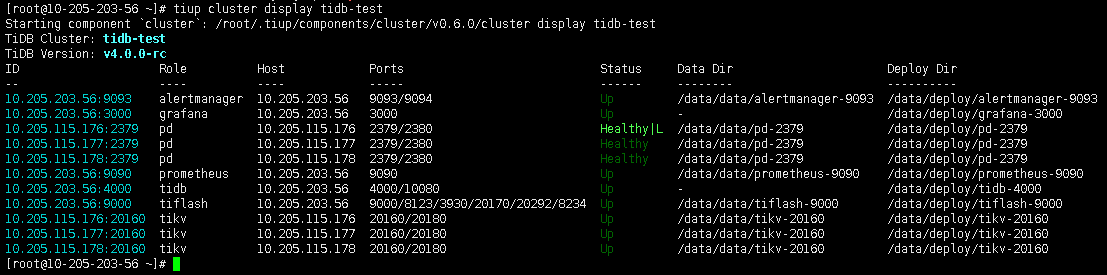
【 集群节点分布 】
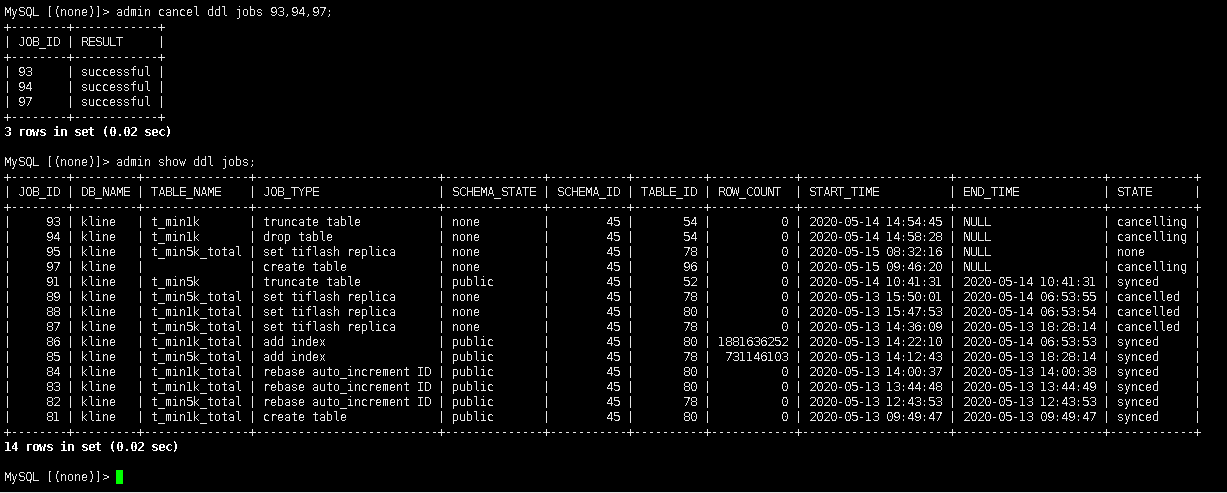
【 问题描述 】
在tidb命令中执行ddl命令,使用了ctrl+c终止,然后使用kill tidb id操作。最后使用 admin cancel ddl jobs
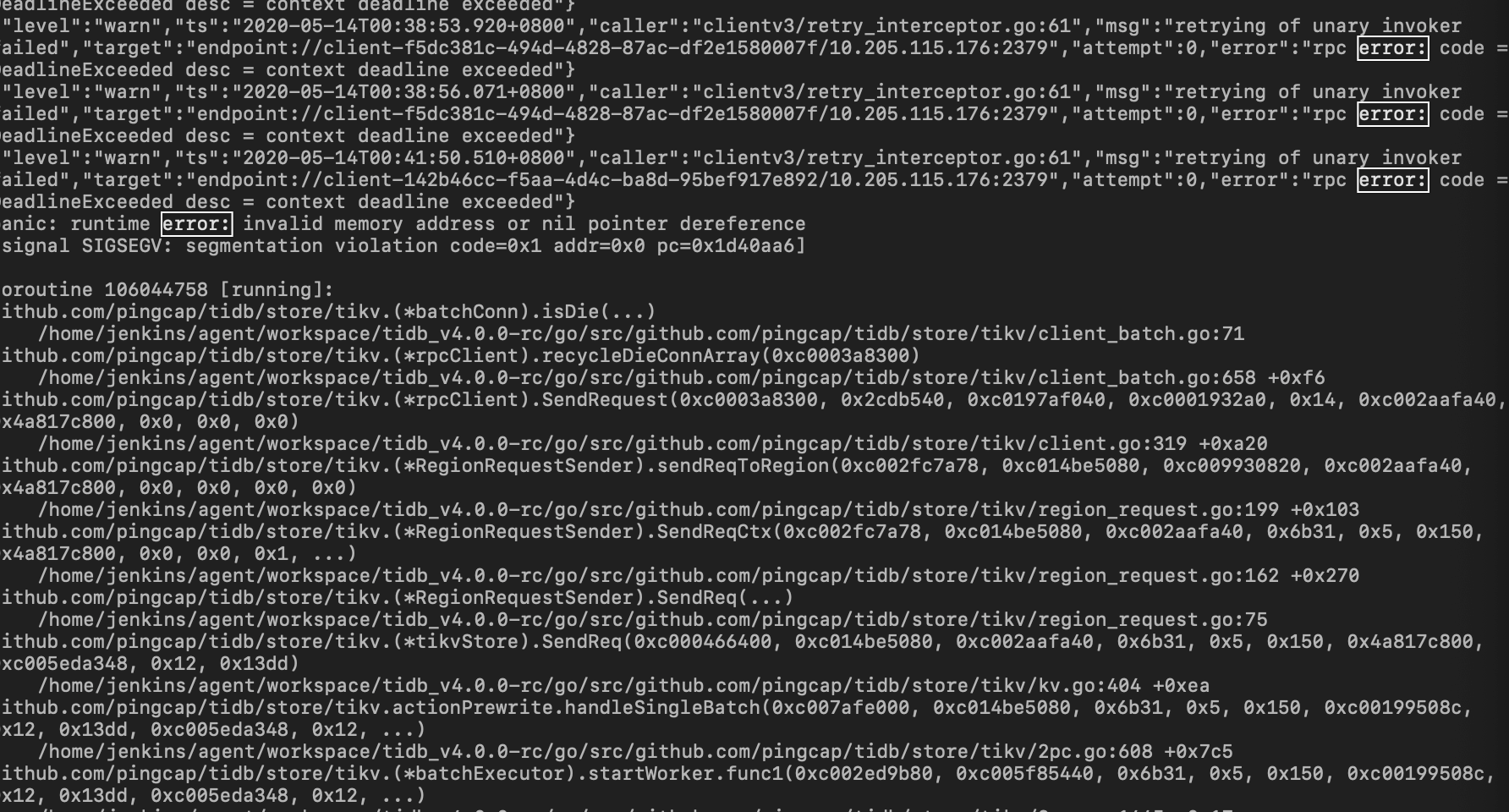
tidb errlog截图如下:

有知道怎么强制删除某个ddl的操作吗?
【 关键词 】DDL, TIDB, cancelling
【**系统版本 **】CentOS Linux release 7.5.1804 (Core)
【 TiDB 版本 】
【 集群节点分布 】
您好,取消 DDL 操作只能用 cancel 来操作,详细内容可查看官网,https://pingcap.com/docs-cn/stable/sql-statements/sql-statement-admin/
cancel ddl jobs执行时间这个可控吗?从截图来看,cancel ddl jobs,有的执行时间挺短的。有的执行时间特别长。像目前这种后续ddl执行不了情况,就只能一直等着?
分 DDL 类型,如果是 add index 会比较慢。还有 DDL 也是放在队列里,后面的要等前面的执行完才能跑,所以后面的等待时间会久一些。可以详细看下 DDL 源码解析这块内容。
https://pingcap.com/blog-cn/tidb-source-code-reading-17/
curl http://{TiDBIP}:10080/info
curl http://{TiDBIP}:10080/info/all
能否看看这个的返回结果呢
kill -9 tidb 之后,可能导致 TiDB 没有及时从 PD 清理注册数据,在同步 schema 状态的时候,会等待 lease 超时才会认为 ddl 执行成功。lease 等待是 ddl 慢的原因。
该下线的 tidb 在 pd 侧的注册信息会在一段 timeout 之后被 pd 自动清理,届时,ddl 同步会正常
可以拿下上述的消息,看下 owner 的状态
curl http://{TiDBIP}:10080/info
curl http://{TiDBIP}:10080/info/all
跟这个可能是同一个问题
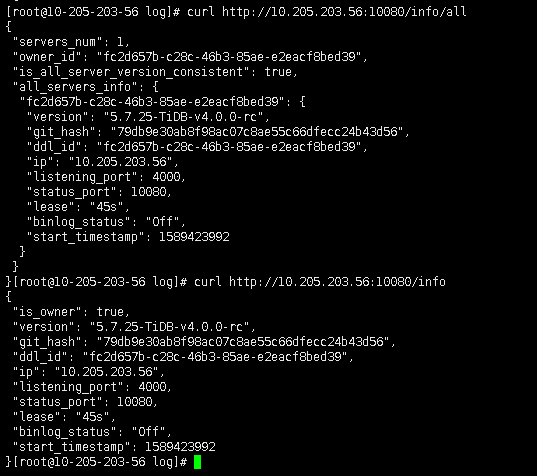
多谢反馈,看起来 tidb owner 是正常的,抱歉能够辛苦再提供下 pd 和 tidb 两端的日志,这个问题看起来和上述那个问题不太像,谢谢
您好,看了 tidb error log 发现
这边方便的可以做下升级,或者将 superBatch 关掉
#Max batch size in gRPC.
max-batch-size = 128
可以将该参数设置成 0。。。但性能会有下降,最好升级
好的,谢谢 后面尝试升级
感谢反馈,如果您有其他的问题,麻烦创建新的问题帖子。 ![]()
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。