版本
3.0.11
SELECT
DATE_FORMAT( Time, '%Y年 %m月 %d日 %H:%i' ) AS '发生日期',
Query_time AS '执行语句花费的时间(秒)',
DB AS 'DB',
`Query` AS 'SQL语句',
Mem_max / 1024 / 1024 AS 'sql 使用的内存(MB)',
Request_count AS 'Request_count [语句发送的 Coprocessor 请求的数量]',
Process_keys AS 'Process Keys [Coprocessor 处理的 key 的数量, 数量越多越占用TiKV资源]',
Process_time AS 'Process_time [SQL在TiKV的 处理时间之和(秒)]',
Wait_time AS 'Wait_time [SQL在TiKV中, Coprocessor 请求排队等待时间之和(秒), ]',
Backoff_time AS 'Backoff_time [语句遇到错误, 在重试前等待的时间(秒)]',
CONCAT( `User`, '@', `HOST` ) AS '谁执行的',
( CASE succ WHEN '1' THEN '成功' ELSE '失败' END ) AS '是否执行成功',
Stats AS '统计信息时间戳, 是否显示为 pseudo'
FROM
information_schema.`slow_query`
WHERE
`is_internal` = FALSE
AND time > DATE_SUB( NOW( ), INTERVAL 1 HOUR ) -- 查询最近一小时的
ORDER BY
Process_keys DESC,
`Mem_max` DESC
LIMIT 1000;
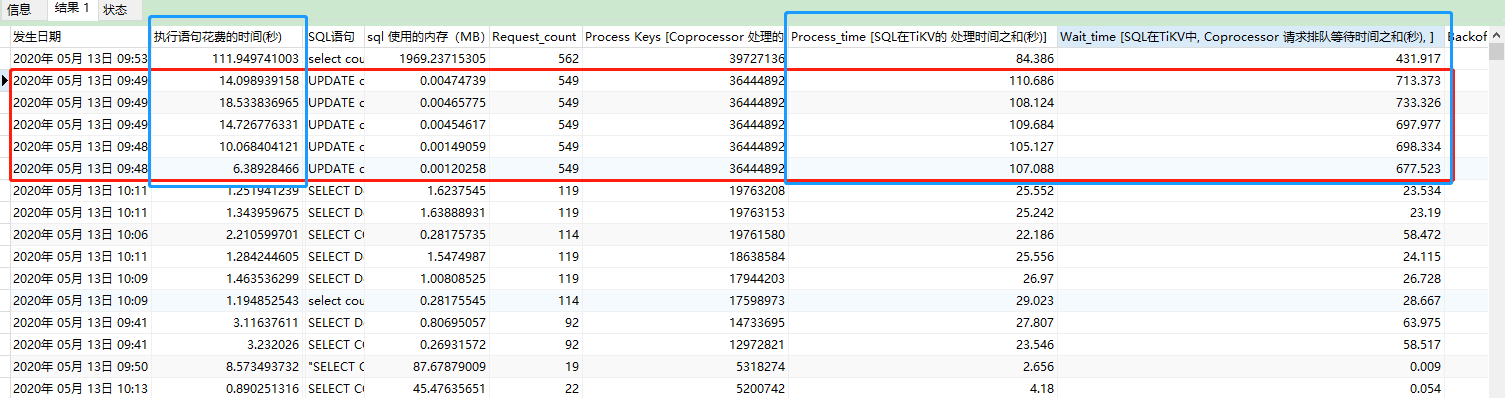
可以看下解释, Process_time :执行 SQL 在 TiKV 的处理时间之和,因为数据会并行的发到 TiKV 执行,这个值可能会超过 Query_time
https://pingcap.com/docs-cn/v3.0/how-to/maintain/identify-abnormal-queries/identify-slow-queries/#查询-slow_query-示例
1 即使超过是正确的,但是 执行时间 10秒, 处理之和100秒, 这也超太多了,为什么超这么多?没想明白
2 还有后面的等待之和,等待的时间,是不是也应该算这条SQL执行的总耗时时间?
3 Query_time 指的是什么时间,发送请求,到响应成功以后的时间吗? 并不是实际的处理时间对吗?
如果我想通过 这sql 完成执行完以后在进行操作,我应该怎么办?
那这个 的query time 不应该是 30秒吗? 为啥会是 10 秒呢
也就是说 这个等待时间之和,是指 这里面的 每个线程的等待时间 之和对吧
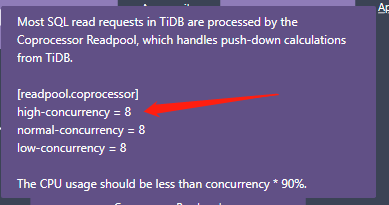
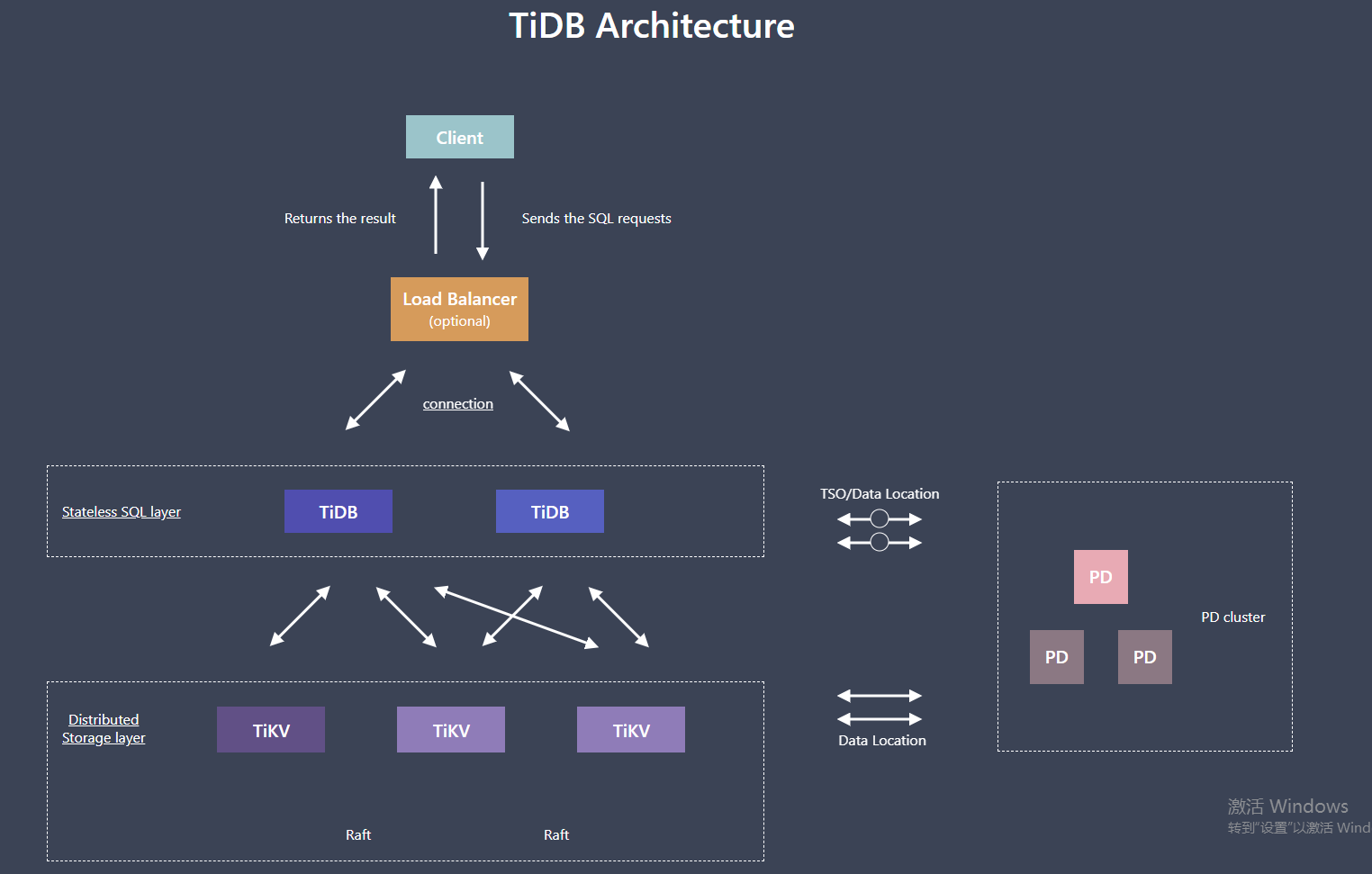
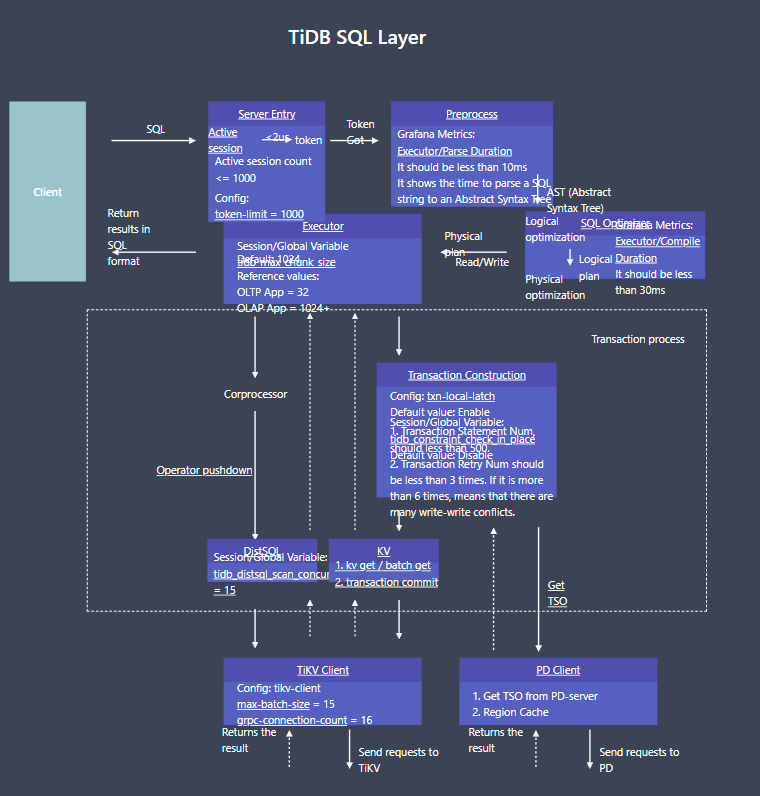
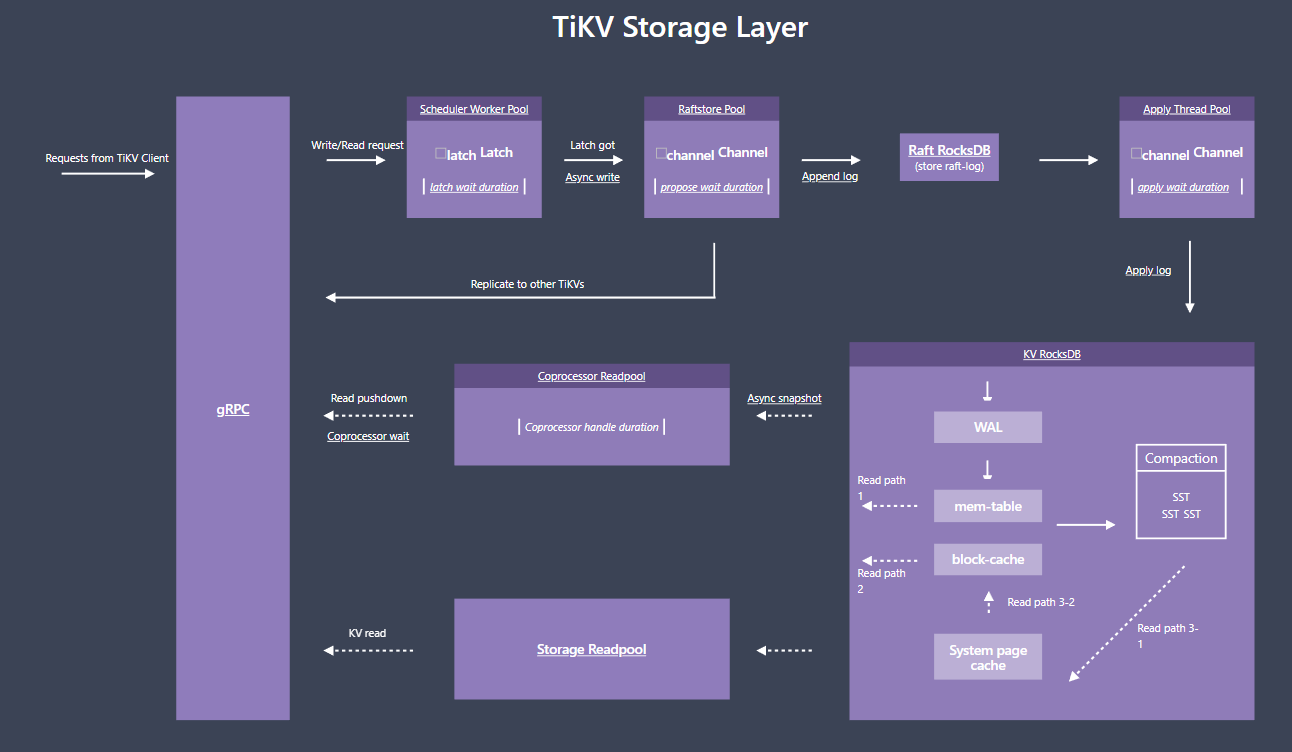
不是,tikv 这里coprocessor ,每个tikv都有,你的一个sql 可能要走多个tikv,所以理论上是分发的消息统一返回的时间。
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。