
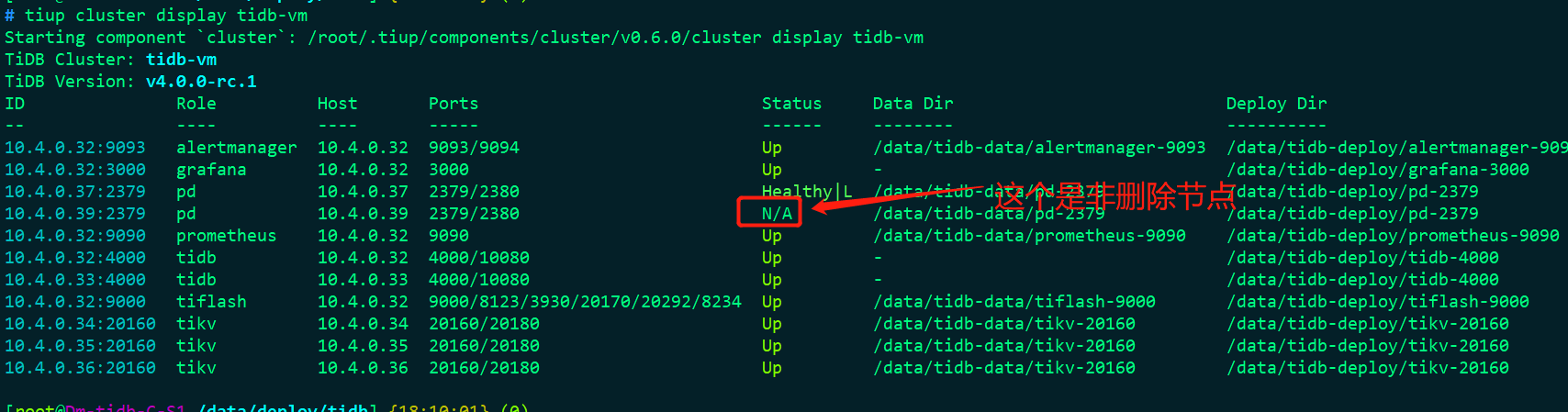
10.4.0.39的节点上error日志报:
{“level”:“warn”,“ts”:“2020-05-08T18:20:38.795+0800”,“caller”:“clientv3/retry_interceptor.go:61”,“msg”:“retrying of unary invoker failed”,“target”:“endpoint://client-352bc993-29ec-4a2d-8e91-1a9216492b67/10.4.0.39:2379”,“attempt”:41,“error”:“rpc error: code = Unavailable desc = etcdserver: server stopped”}
1 个赞
稍等,我们测试下,多谢
你好,
这边没有复现你的问题,
请反馈一下信息,帮助排查
- pd-ctl -i -u http://10.4.0.39:2379 执行下 member 和 health 贴下反馈结果
- 可以在 grafana - overview 看下节点数是否符合预期。
- 上传下 scale-in 附近的 pd.log
未复现.txt (9.9 KB)
手工把故障的pd删除后,重新部署。 上述操作三次后,终于恢复了。
![]() ,可以分享下操作步骤吗,方便其他小伙伴学习。
,可以分享下操作步骤吗,方便其他小伙伴学习。
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。