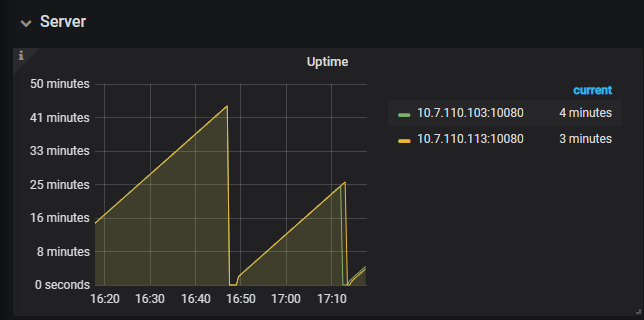
现在改为8g后,又进入自动重启模式了,每隔25分钟,会重启一下
-
麻烦采集一下内存profile,当前重启以后,在内存不断上涨过程中, 执行 curl -G “ip:port/debug/pprof/heap?seconds=30” > heap.profile
ip地址为tidb服务器的ip,端口为tidb_status_port的端口,生产的文件在执行的目录下 -
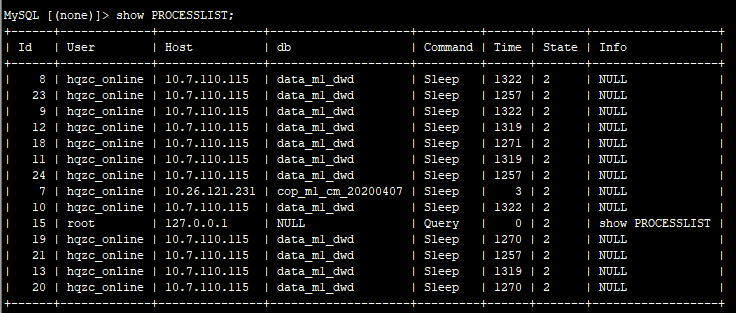
麻烦在重启后,内存不断上涨过程中,执行下 show full processlists ,多谢。
heap_2020-05-09-10-16-07.profile (62.4 KB) heap_2020-05-09-10-19-13.profile (67.3 KB) heap_2020-05-09-10-19-29.profile (67.5 KB) heap_2020-05-09-10-19-49.profile (68.2 KB) heap_2020-05-09-10-19-56.profile (68.2 KB) heap_2020-05-09-10-20-04.profile (68.3 KB) heap_2020-05-09-10-20-08.profile (68.9 KB)
1、采集profile内存使用情况的文件已经上传,按照在内存不断上涨,马上重启前截取的 2、使用show full processlist得到结果如下截图。这些进程在重启后就有,并且没有造成内存溢出。
感谢,我们查看下稍后答复。
请问一下,这个集群有多少个table呢?每个表的表结构大致是什么样
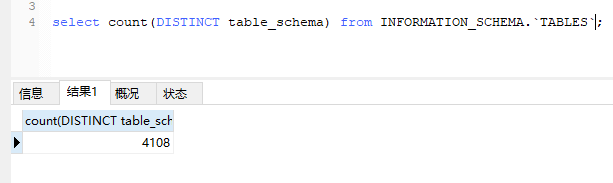
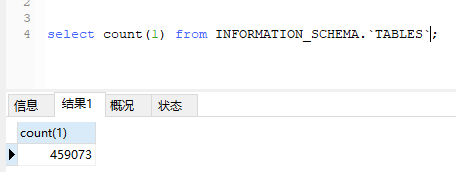
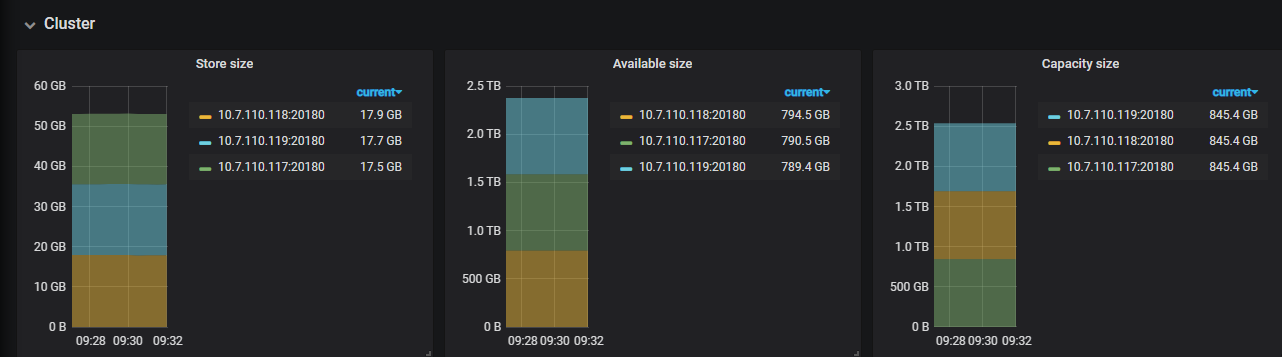
现在做什么都慢的不行,一直在拿TiDB当mysql+hive来用,将所有业务数据都采集过来,进行分析。前天将TiDB的内存由16G增加到32G了,到现在没有出现重启的现象,但查询速度真是慢啊。有什么办法能定位问题么?或者是TiDB不对支持这多数据库或表
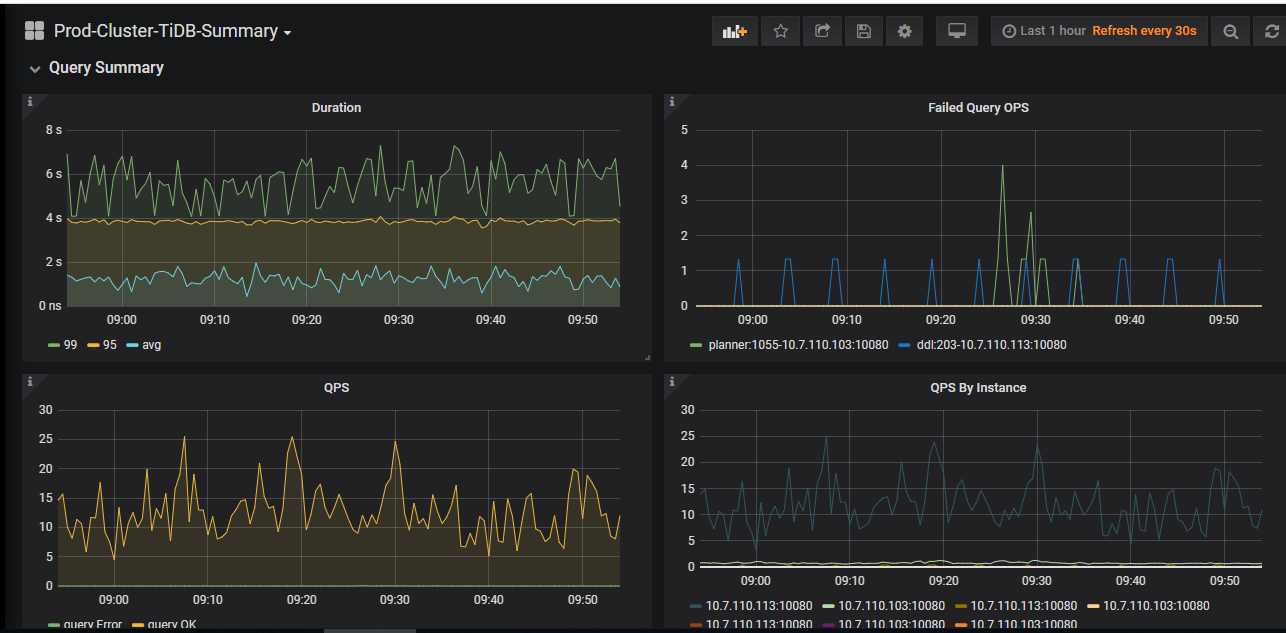
性能的问题,我们重新开个帖子来查看下,多谢。
已经转到https://asktug.com/t/topic/34254这个帖子里面。 这个贴子没有通过修改配置来确定问题,最终是通过增加两台TiDB的内存(16g到32g)来解决,后续还要跟踪,增加配置一持续1天多没有重启,原来25分钟就会重启。 感谢TiDB同学的支持!
好的,感谢反馈
通过分析内存,有一部分是在启动时载入了所有表的 table meta,占用了一部分内存;另一部分是后台载入统计信息,直到内存被打满。
因为这个场景下表很多,所以 table meta 和统计信息占用的内存很多。
关于优化统计信息内存的,已经有 issue 了 https://github.com/pingcap/tidb/issues/16572 我们后续会跟进。
导致问题重启的原因确实是表太多,导致region数量太多。但现在是拿TiDB当数据仓库使用,数据存储到TiDB中后基本不再使用时,即使使用的话频率也非常低,所以由表多和region多,导致内存占用多的问题,还是需要进行优化一下,毕竟程序还没有使用那块region呢,就不应该装载到内存当中。希望这个问题早日解决,感谢回复!
这个问题的解决方法在另一个贴子当中会进行回复。
![]()
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。