为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】:TiDB-v4.0.0-rc
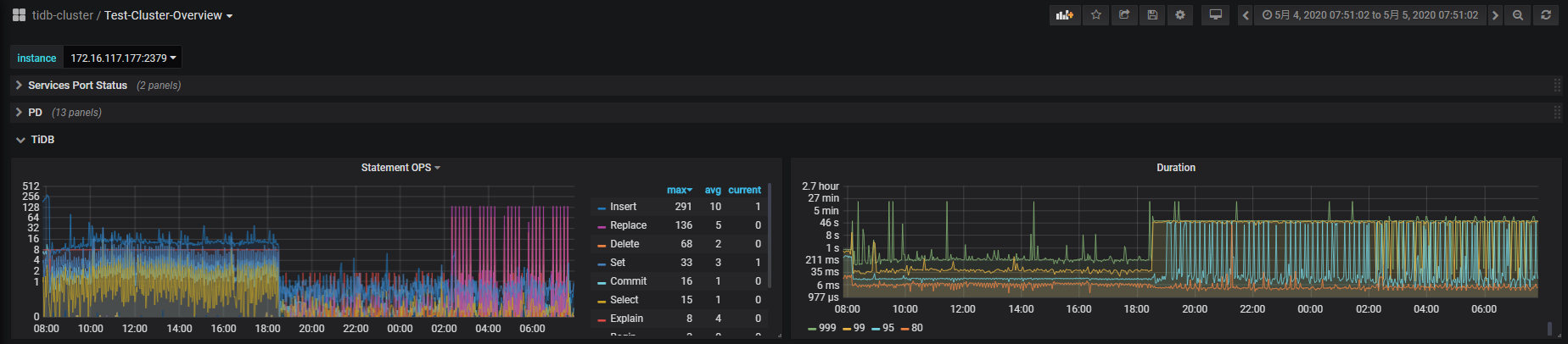
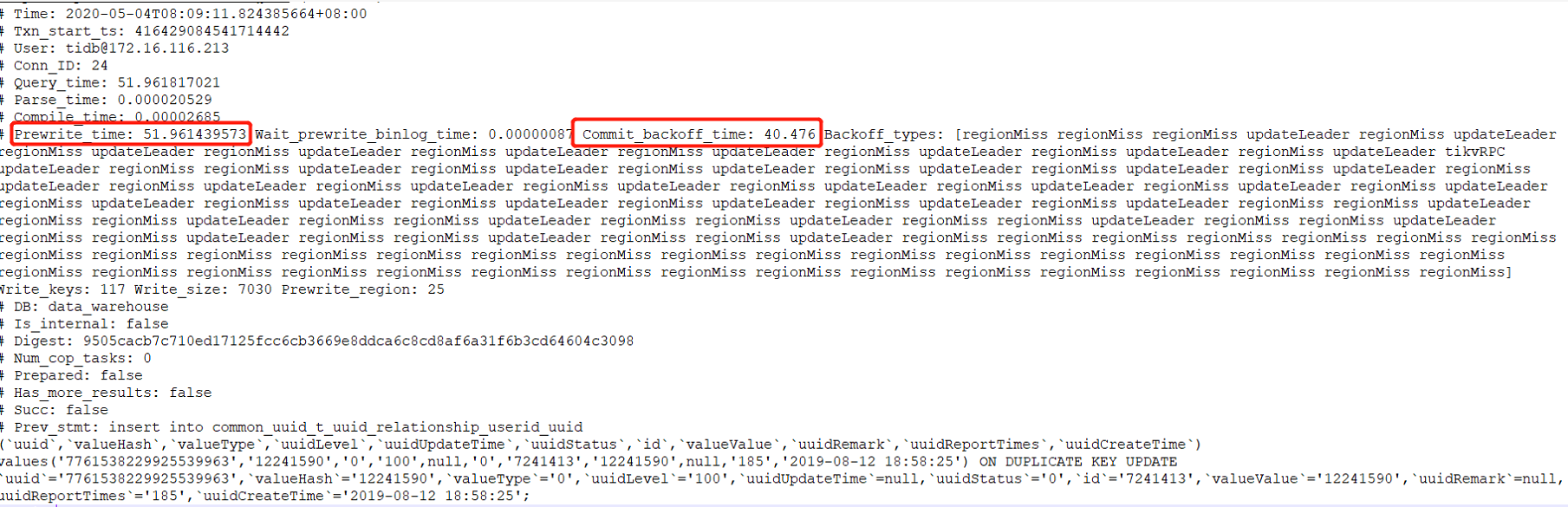
- 【问题描述】:从5月4号早上8点多开始,查询忽然就要40多秒才能出结果,插入耗时更长

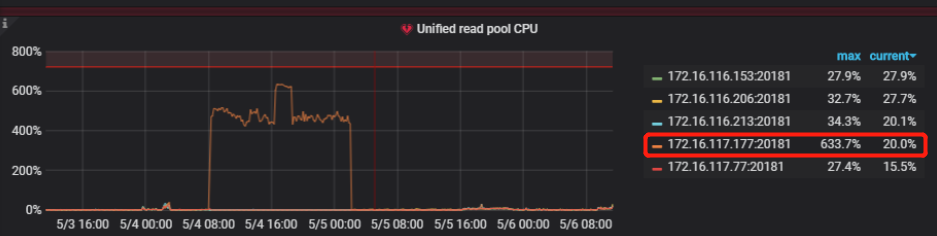
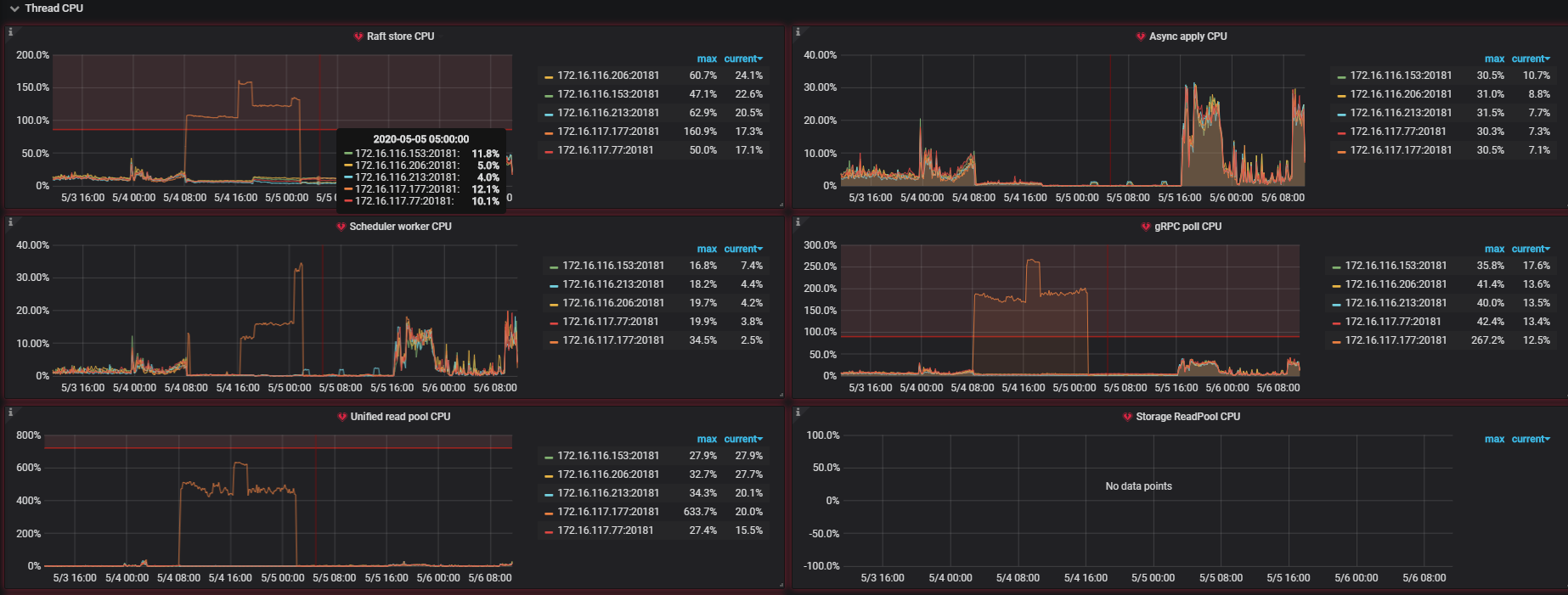
看起来只有177节点的raft-cpu特别高,但是一个节点为什么会导致整个集群几乎不可用?
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出打印结果,请务必全选并复制粘贴上传。
为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
看起来只有177节点的raft-cpu特别高,但是一个节点为什么会导致整个集群几乎不可用?
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出打印结果,请务必全选并复制粘贴上传。
over-view
screencapture-172-16-116-213-3000-d-eDbRZpnWk-test-cluster-overview-2020-05-06-11_52_14.pdf (3.9 MB)
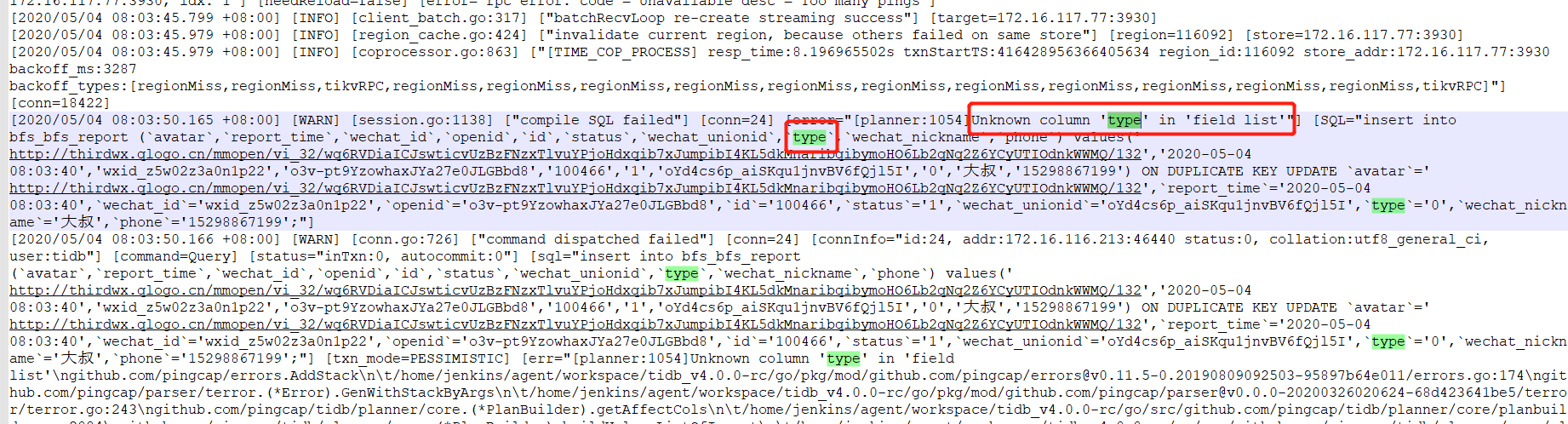
bfs_bfs_report这个表有的时候会报这个错,但是没有出现读写极速变慢的问题;
DM只使用单表同步,没有使用分库合表操作。
请问您是使用 ansible 还是 tiup 安装的? 是新集群还是从其他版本升级上来的? 拓扑是什么? 有共部署吗? 比如pd tidb tikv 部署在同一台服务器?
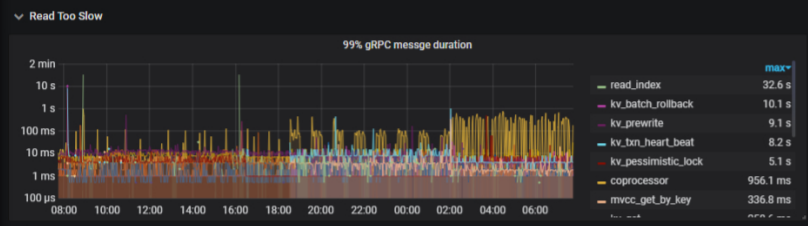
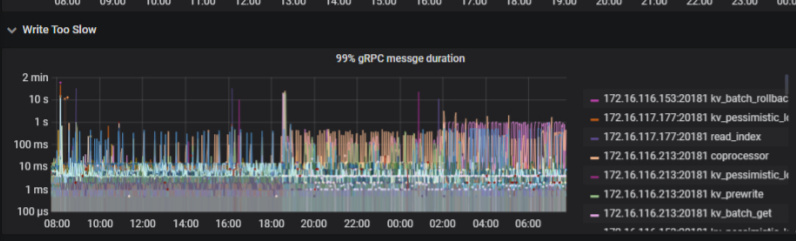
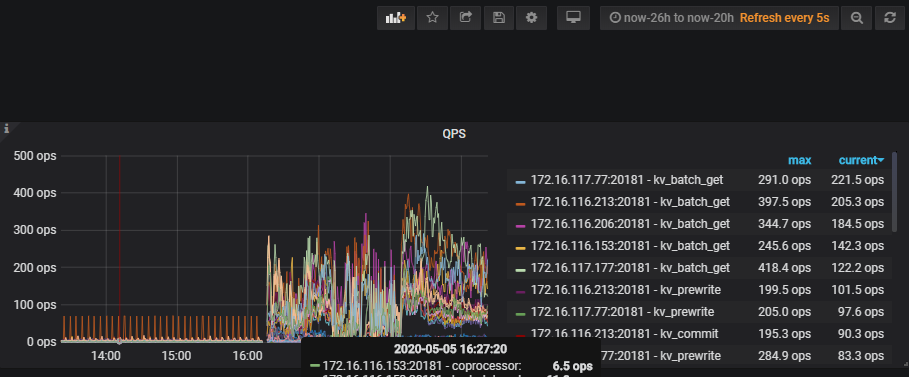
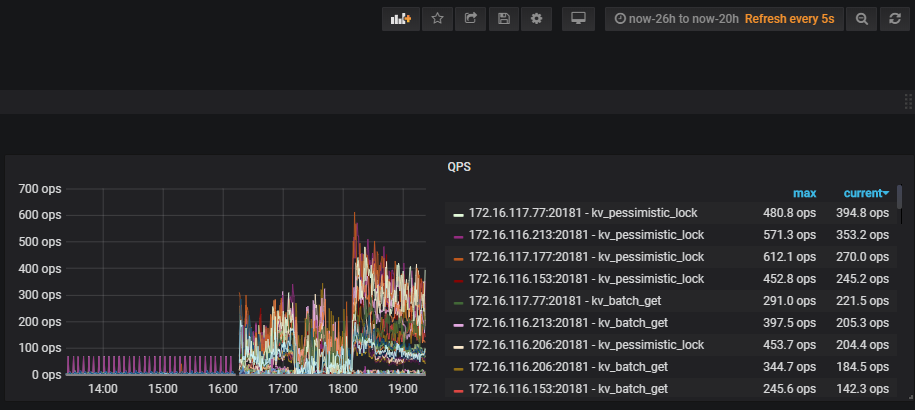
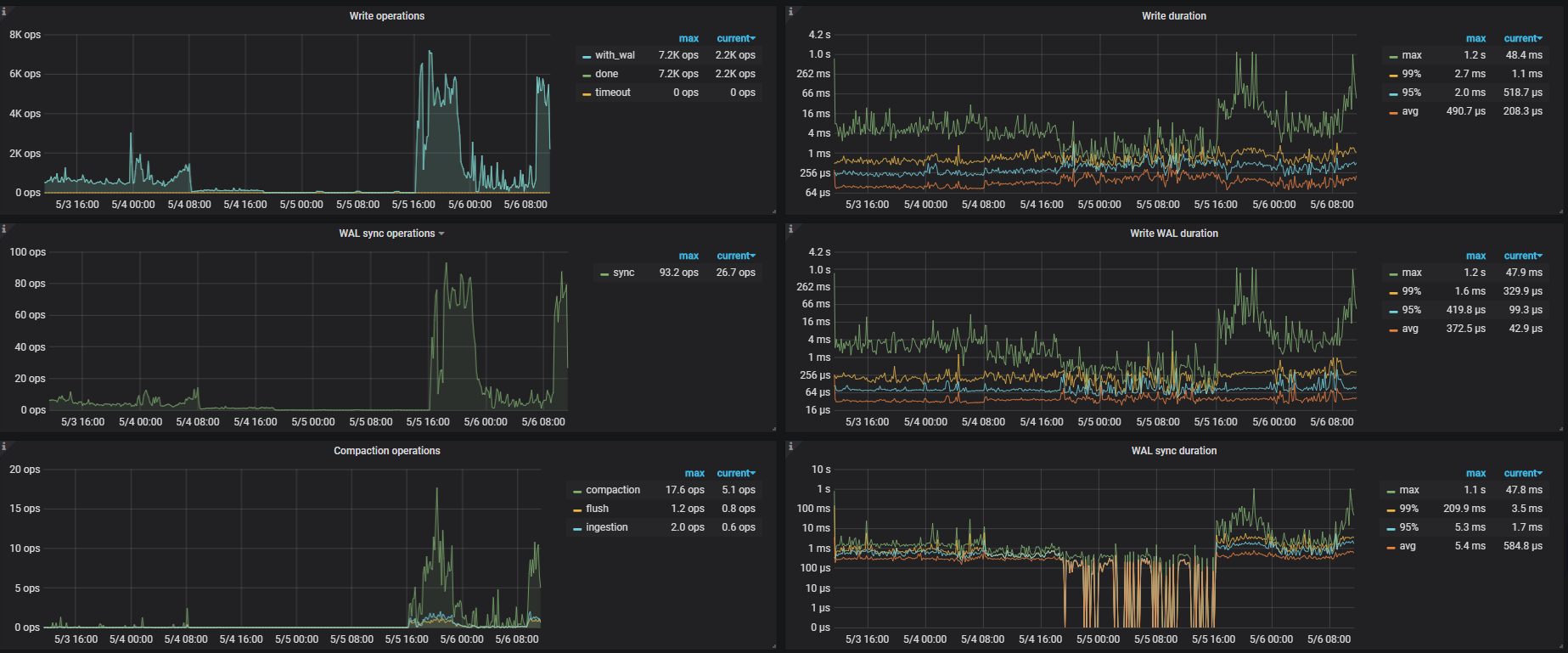
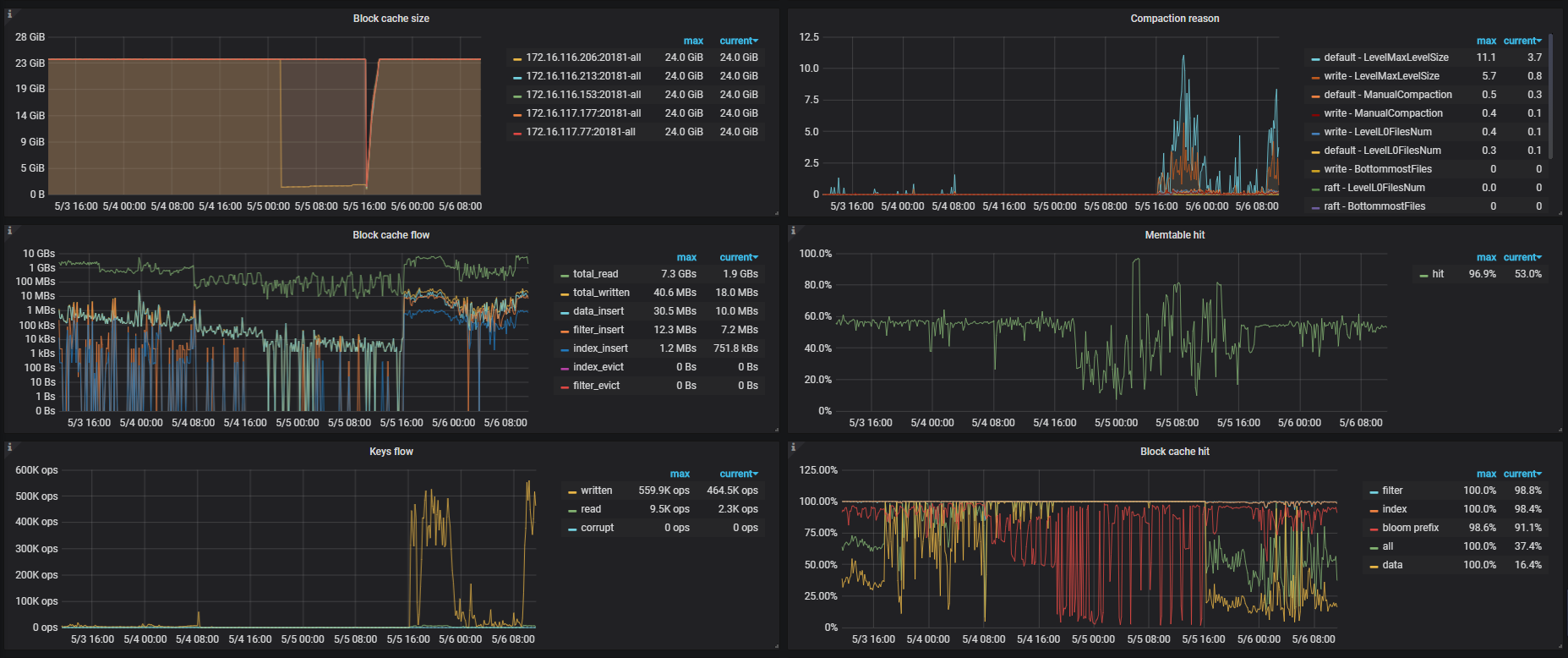
从监控看,这段时间 读和写 都差不多 ,duration 比较长。
是在5号凌晨2,3点重启的吗?
能否监控时间包含正常时间段,方便对比正常和异常时间段的指标, 多谢。
1 使用tiup升级的,初始版本是3.1.0-rc,集群拓扑如下
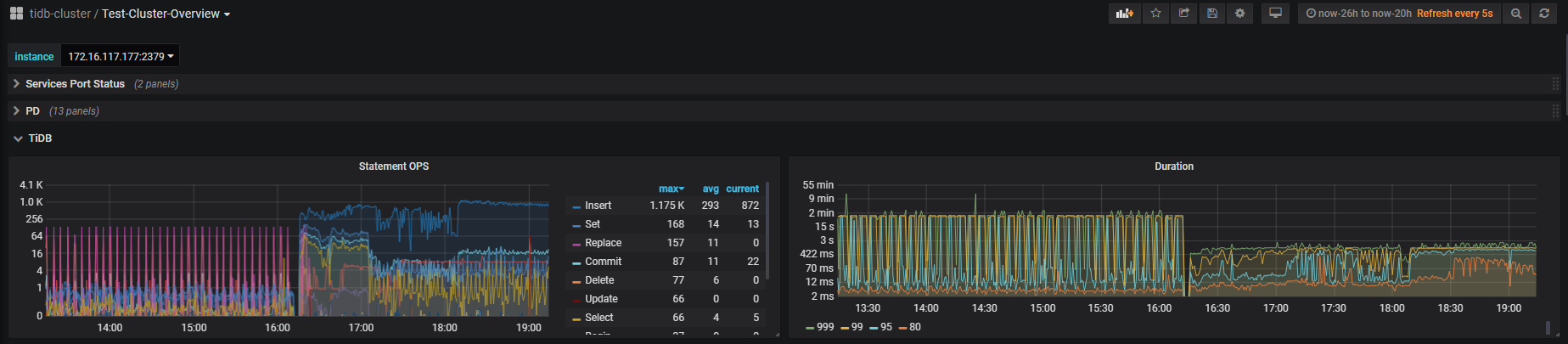
2 一直到5月5号下午4点14分重启集群之前,集群几乎不能进行查询和写入,重启之后读写基本恢复
3 在5月5号下午4点14分左右重启的
4 5月5号下午4点之后的基本是正常的
问题现象:
5月4号上午8点多一点, 一直到5月5号下午4点14分重启集群之前,集群几乎不能进行查询和写入
问题分析:
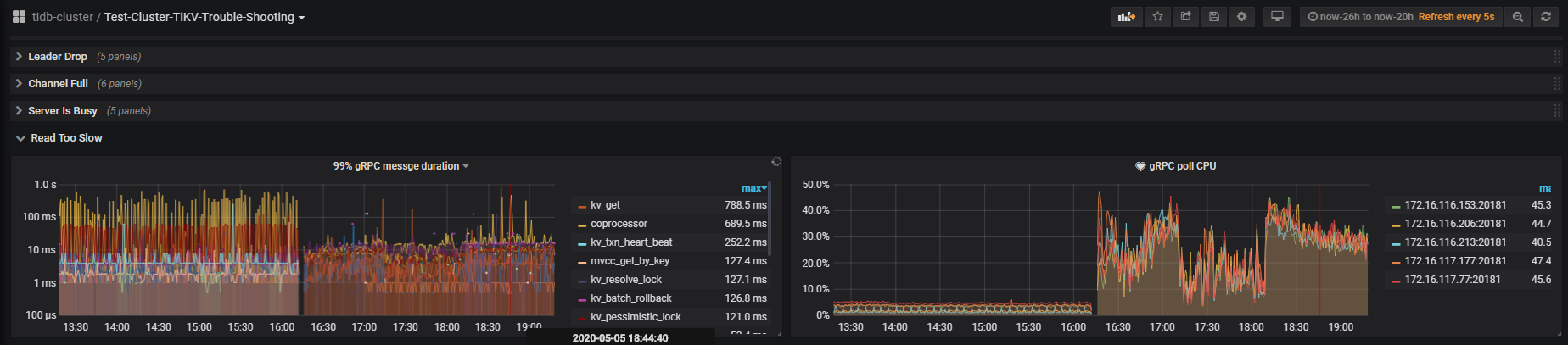
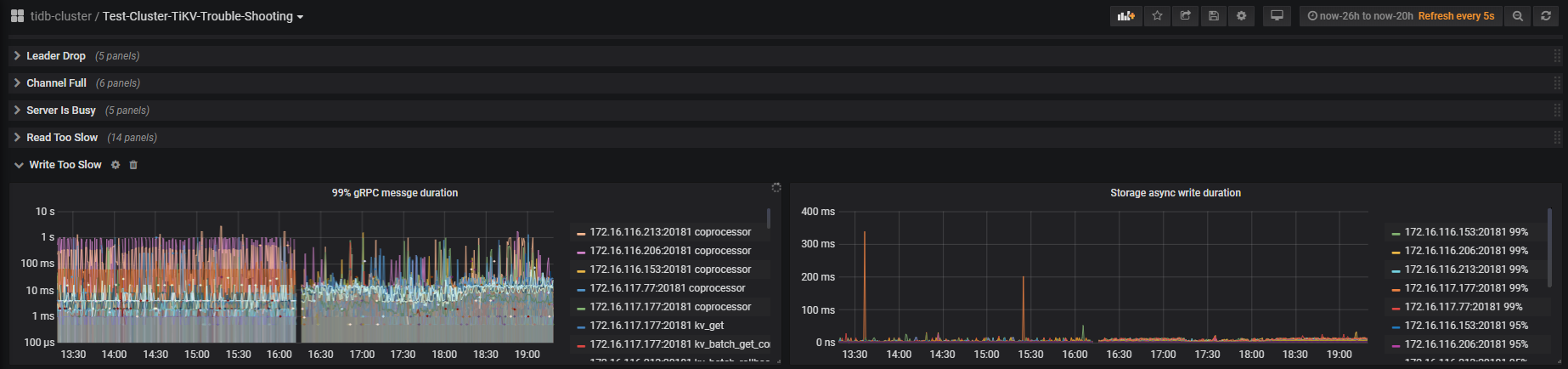
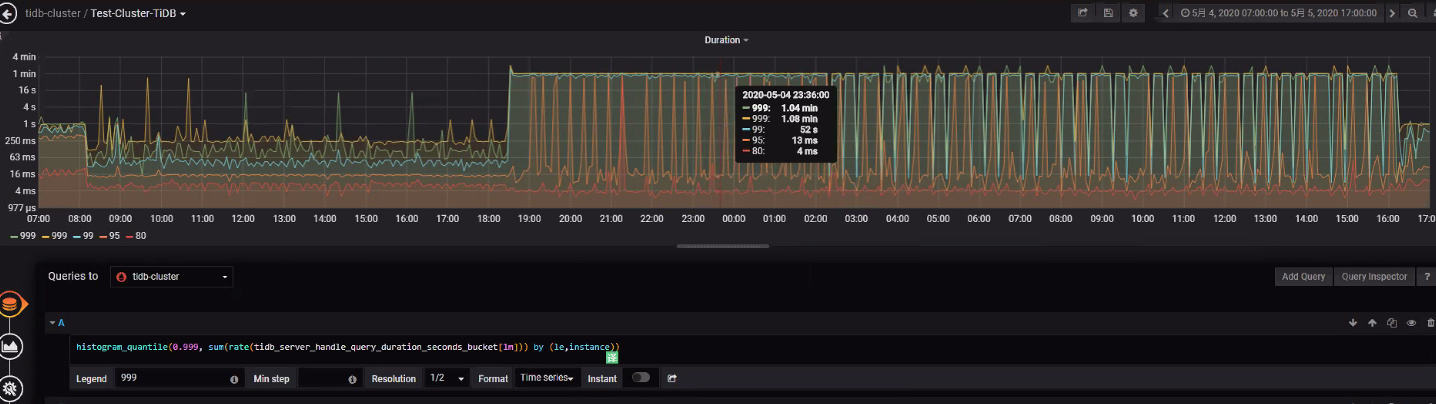
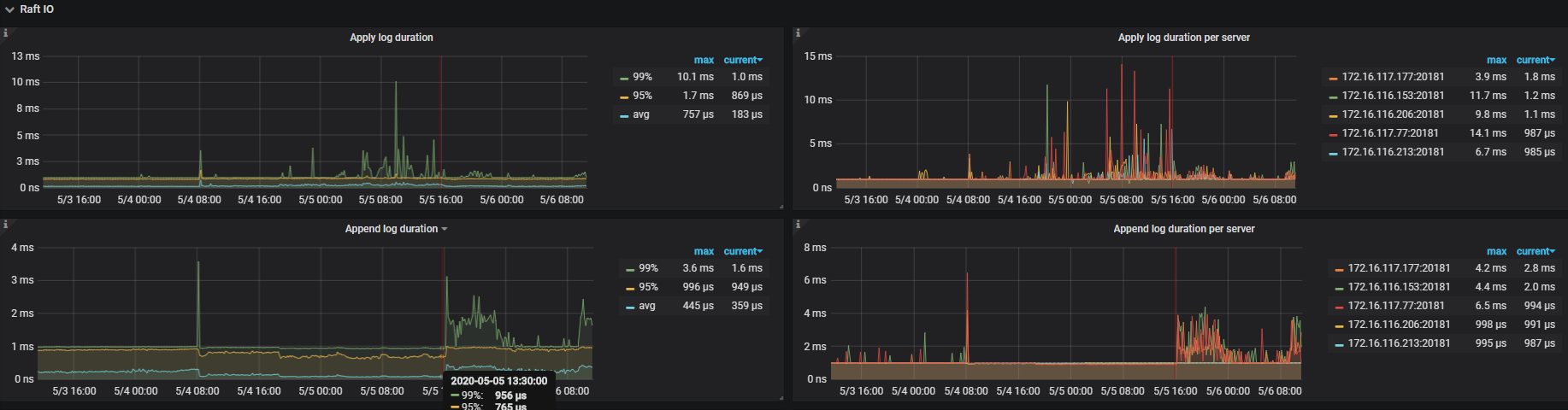
查看问题发生时的tidb监控信息,达到了1min
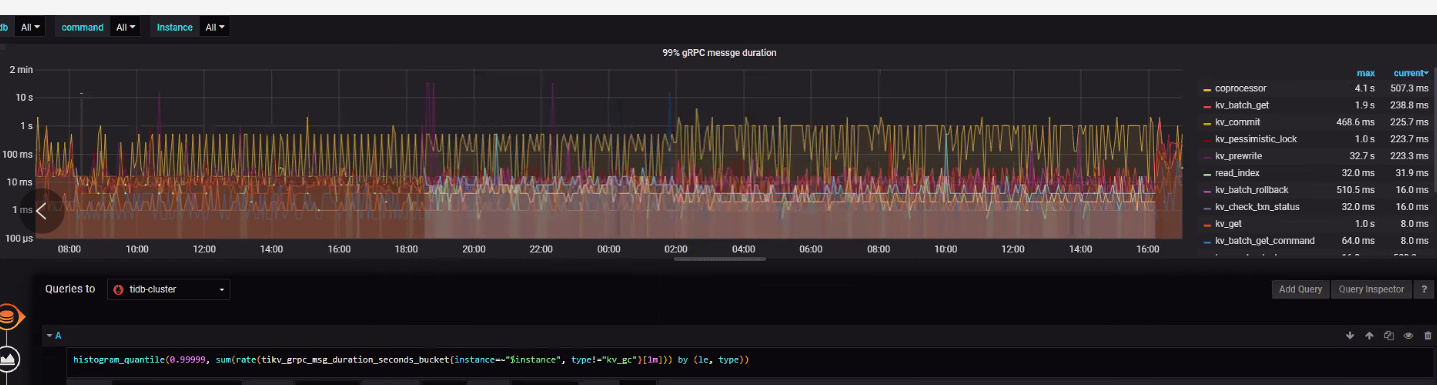
查看问题发生时tikv监控信息,在10s左右
查看slow日志,时间大多数消耗在了backoff
麻烦上传问题发生时的 pd 和 tikv 日志,多谢
请问安装dashboard了吗? 麻烦上传一份 集群诊断报告,多谢。
请问提供的 tikv-log.zip 是 177 tikv 节点的日志吗?另外根据已有的信息看到应该是有 5 个 tikv 节点,麻烦提供下异常前后的完整日志。 在 dashboard 页面,选择 日志搜索 :时间段选择重启前后一个小时区间,INFO,选择 TiDB & TiKV 实例 ,然后右边选择下载。
您好,上面提供的是177节点的tikv和pd的日志;下面提供的是重启前后一小时的两个tidb和5个tikv的log
链接:https://pan.baidu.com/s/16U6eLeaC33o4vmjhXTSHGw 提取码:l9vx
收到 我们分析下
好的,谢谢啦
从日志和监控分析,这个问题大概率是触发了 4.0rc 版本的 grpc 死锁问题:因为 grpc 死锁导致 177 节点上面的 region 一直进行选举,读写请求打过来之后一直在 backoff,反映在监控上 raftstore 和 readpool 异常高,同时该节点上面的读写请求响应慢。后面重启集群之后,死锁消失,region 选举恢复正常,读写正常。死锁问题在 rc1 版本已经修复,可以升级至 rc1 版本。
![]() 什么原因导致的死锁呀?节假日服务也不繁忙啊
什么原因导致的死锁呀?节假日服务也不繁忙啊