qq悟空
2020 年5 月 4 日 03:32
1
为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
【TiDB 版本】:v3.0.3
【问题描述】:目前需求是同步多个上游的mysql库至tidb中,但上游库的表均包含了自增数字主键,为了避免表同步到下游tidb中出现region热点的情况,需要将一些大表的表结构在同步开始前进行一些调整: 下游tidb表的自增数字主键修改为唯一索引;在下游tidb表结构中添加 shard_row_id_bits和pre_split_regions 配置;调整完成后再开始进行全量同步+增量同步。目前想到以下几种方案,帮确认下可行性及可能存在的问题,谢谢
1: 使用DM套件 (在配置文件中mydumpers配置项中增加
2: 使用Mydumper同步全量数据(不同步表结构,表结构在tidb中手动创建),使用TiDB Lightning导入全量数据,之后使用DM同步增量数据
3: 使用Mydumper进行全量备份,使用loader进行数据导入,使用DM进行增量数据同步
文档上有看到**"TiDB Lightning 运行后,TiDB 集群将无法正常对外提供服务"** ,这个指的仅仅是Importer-backend这种方式吗? 还是指Importer-backend与TiDB-backend两种方式呢?如果tidb需要在导入数据期间提供读写服务,是不是就不能使用TiDB Lightning这种方案呢 ?
配置DM使用增量同步 ,修改dm-worker配置文件中 task-mode: incremental ,请问该如何设置实例配置的 meta 配置项来指定增量同步开始的位置呢? 文档上没找到相关操作步骤和说明,烦请帮提供一下
谢谢
来了老弟
2020 年5 月 4 日 04:31
2
你好,
对于全量数据的导入可以使用 空表结构 + lighting 的导入方式
使用 mydumper 导出数据并添加 –no-schemas
在下游 tidb 创建改造后的表结构(自增数字主键修改为唯一索引;在下游 tidb 表结构中添加 shard_row_id_bits 和 pre_split_regions 配置)
在 tidb-lightning.toml 中设置 [mydumper] no-schema = true ,并使用 TiDB-Lightning 之 TiDB-Backend 导入模式 (此模式导入数据时 tidb 可以对外提供服务,因为使用过运行 sql 的方式进行的。)
通过 dm 进行增量同步,(在 mydumper 中查看增量 meta)
PS:
答:增量同步模式下通过修改 inventory 文件中 relay_binlog_name/relay_binlog_gtid ,来设置增量同步点。并重新 deploy。
qq悟空
2020 年5 月 4 日 07:53
3
1: 你建议的这种方式里,在前面3个步骤里实现的是全量同步阶段,这个全量阶段增量同步并未开始吧,我理解第四步增量同步阶段开始时才开始设置task-mode: incremental 和 配置relay_binlog_gtid增量同步起始位置 ,以及deploy、start对应的dm-worker任务 ,是这样吗
2:以上第三步和第四步,是否可以通过DM来实现全量+增量的方案来替换呢
谢谢
qq悟空
2020 年5 月 4 日 08:18
4
使用DM方式进行全量+增量步骤如下:
dm-worker配置文件中,mydumpers配置项增加 extra-args: "--no-schemas" ,其他配置不变
在下游 tidb 创建库和所有改造后的表结构(自增数字主键修改为唯一索引;在下游 tidb 表结构中添加 shard_row_id_bits 和 pre_split_regions 配置)
deploy 、start 同步任务,并start-task 同步任务
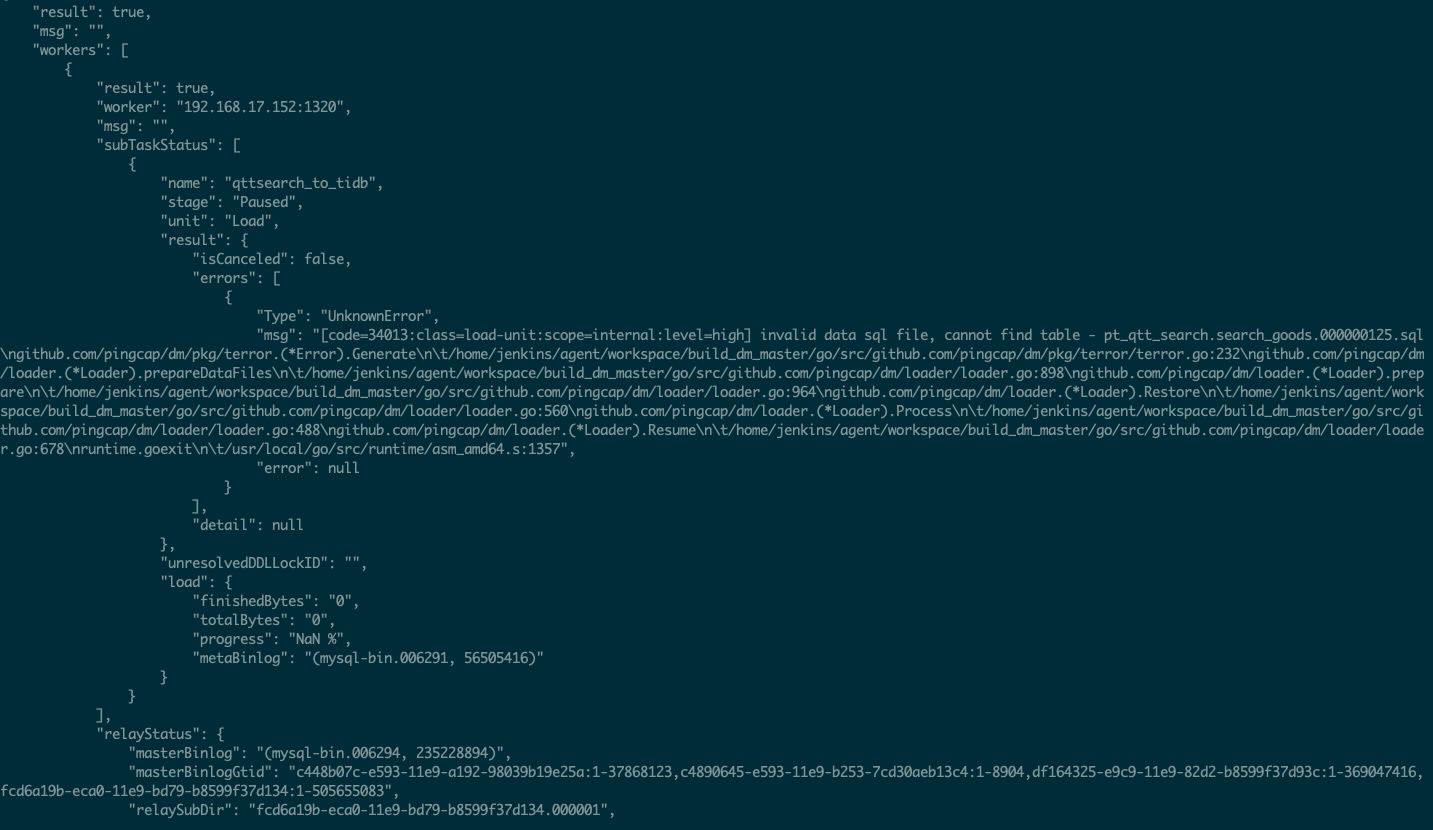
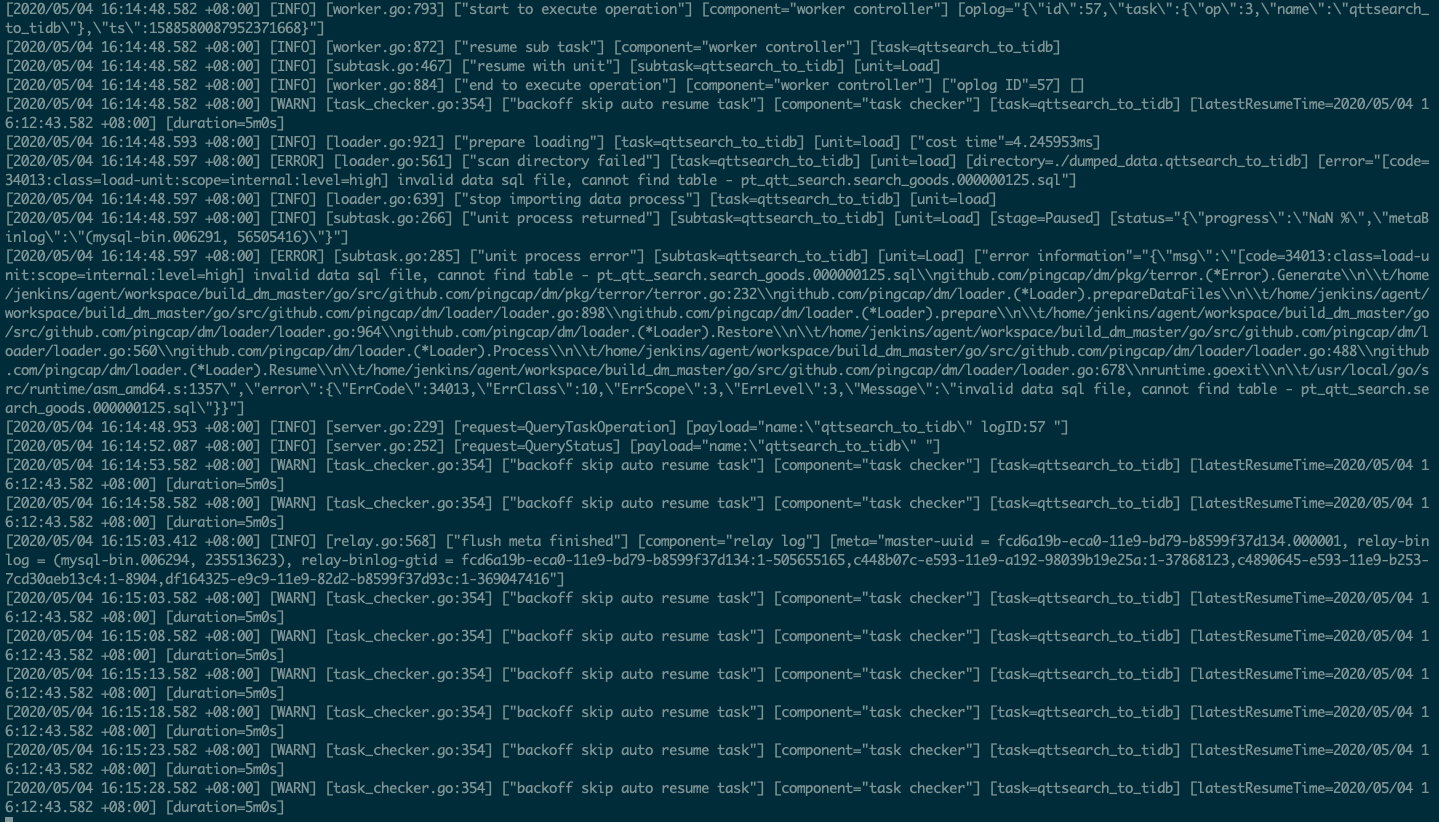
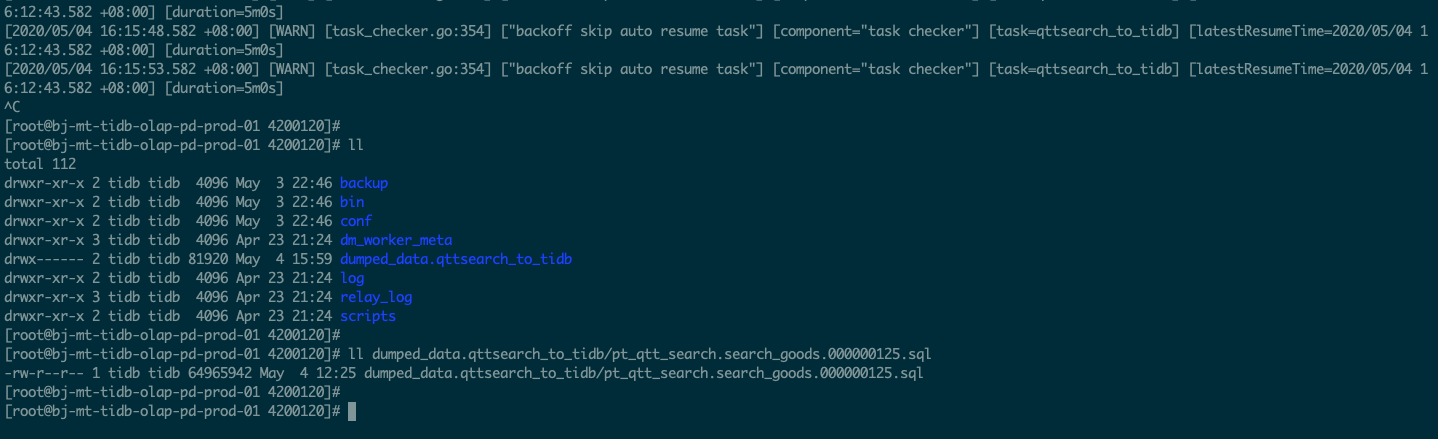
全量数据dump阶段顺利完成,但load阶段开始时就出现报错 code=34013:class=load-unit:scope=internal:level=high] invalid data sql file, cannot find table - pt_qtt_search.search_goods.000000125.sql 。 但在dumped_data.qttsearch_to_tidb目录中,pt_qtt_search.search_goods.000000125.sql文件是存在的,文件内也有表数据
帮确认下这个流程有什么问题吗 ? 出现的报错是什么原因导致的呢? 谢谢
来了老弟
2020 年5 月 4 日 11:20
6
你好,
整理 dm-worker deploy_dir 目录,删除 dump.task-name 和 relay-log 目录。删除 dm_meta 数据库,清空以上信息。
根据官网提示 task 任务完整配置
mydumper 相关参数添加在 task 任务文件中。
qq悟空
2020 年5 月 5 日 06:29
7
看文档确认了一下 ,DM这个方案应该是跑不通的 。loader工具不支持导入无表结构的全量备份数据,是这样的吗?
loader 是不直接支持无表结构的数据恢复,但是可以通过手动创建空的 -create-schema.sql 文件来绕过这个问题
为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
【TiDB 版本】:2.1.14
【问题描述】:mydumper使用-m, --no-schemas参数备份备份的数据,直接用loader无法导入,会报err[invalid mydumper files for there are no -schema-create.sql files found]。表结构已经存在了,也有数据,想把…
1 个赞
qq悟空
2020 年5 月 5 日 15:18
9
task-mode= incremental
incremental :只通过 binlog 把上游数据库的增量修改同步到下游数据库, 可以设置实例配置的 meta 配置项来指定增量同步开始的位置
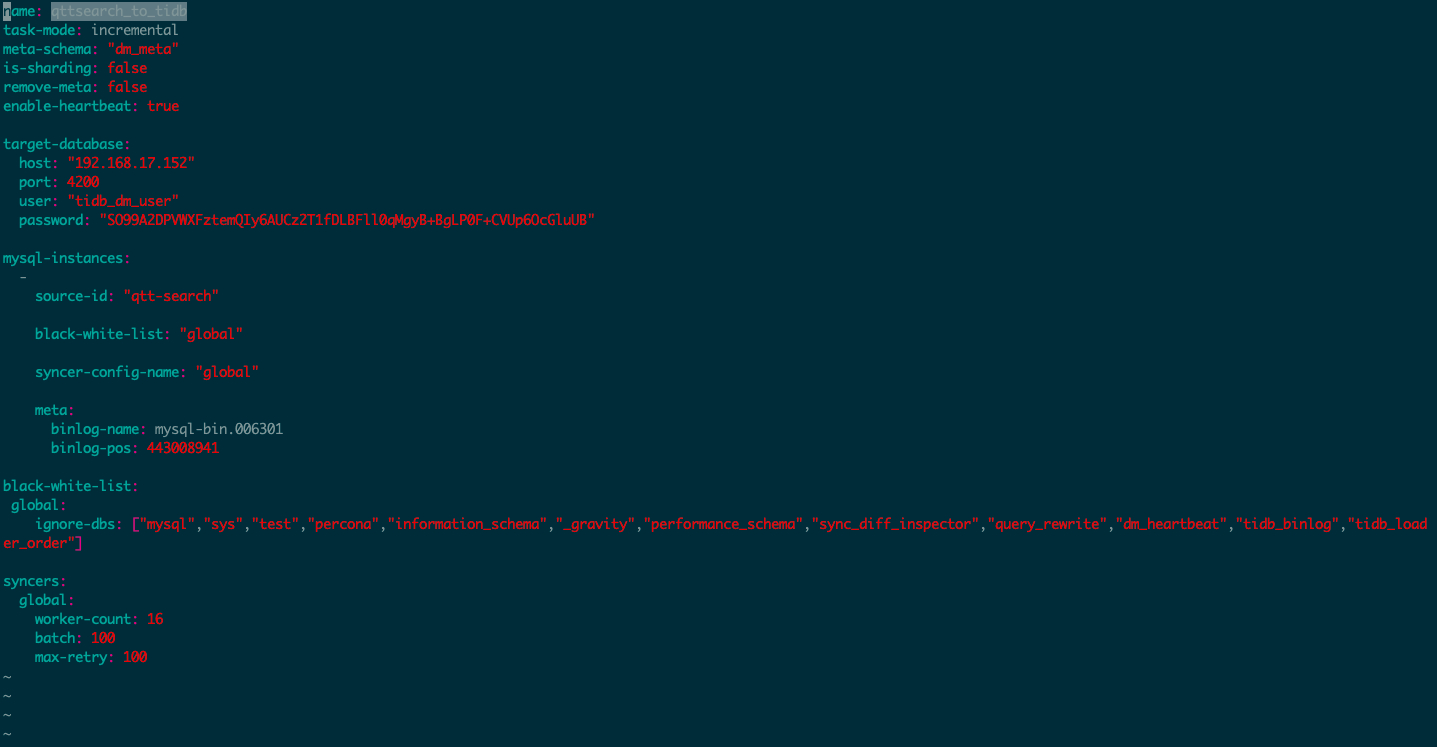
请问该在什么地方,如何设置实例的meta配置项呢? 目前dm-worker任务启动时报错 [code=20022:class=dm-master:scope=internal:level=medium] mysql-instance(0) must set meta for task-mode incremental
谢谢
qq悟空
2020 年5 月 6 日 03:25
11
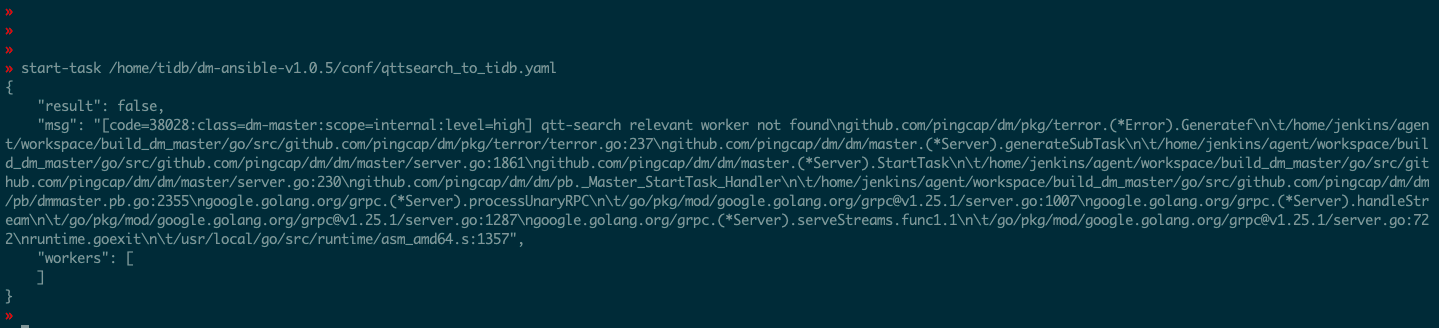
全量数据是通过mydumper/loader手动导入完成的,如下截图配置增量导入,报错了,帮确认下原因,谢谢
[code=38028:class=dm-master:scope=internal:level=high] qtt-search relevant worker not found
来了老弟
2020 年5 月 6 日 03:53
14
你好 ,
好的。
根据截图信息,可以检查下 inventory 和 task 文件中关于 password 配置项的正确性