为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】:3.1rc
- 【问题描述】:
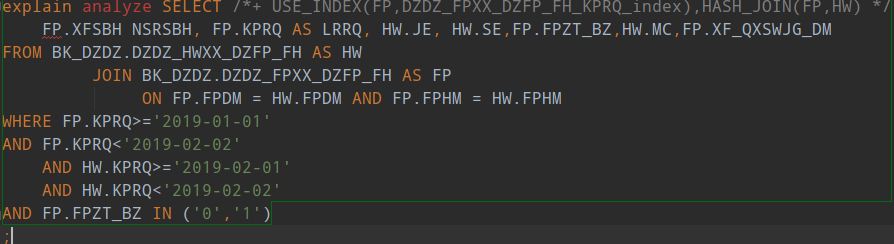
两个表一个6千万记录,一个1.3亿记录,通过发票代码和发票号码关联。查询一个月的数据,如何优化?
硬件环境:至强2.5GHZ20核双CPU,内存128G,DB2主机,PD3主机,KV7主机
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出打印结果,请务必全选并复制粘贴上传。
为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
1、看到执行计划最终返回了 120w+ 的记录,整个返回的记录数还是很大的,能否从业务的角度来缩减返回前端的数据量。
2、整个执行计划中看到有使用 hint hash ,这个是当前使用优化器自动选择的执行计划,执行效率更差吗?
3、在保持 hash join 的基础上,整个耗时在 hash join 是比较多的,建议先在 session 级别尝试调整下下述参数,观察下执行效果:
嗯,感谢分析,可以按照业务分类查询,这也是我考虑要优化的点之一;另外,hash hint 效果不明显;另一个tidb_hash_join_concurrency我设置为140,按照您的经验不知道是否合适,我的kv是20核*2的CPU,一共7个。tidb集群只用来做AP,数据通过ogg实时刷oracle数据过来
如果调整参数后,没有特别明显的提升,那么建议您从业务的角度,看是否可以添加更多的过滤条件,减少数据返回的数量~~
感谢,目前我们已经采用增加过滤条件,并发执行多查询,降低查询时间粒度,等方法,目前可实现1.6秒内返回前台,基本满足了olap需要。增加了中间计算层开发,但是tidb不支持存储过程,并发计算是不是要自己体外进行。
你好,
是的,事务并发建议通过程序实现。
可以测试下 tiflash ,对 ap 业务可能还会有提升。
https://pingcap.com/docs-cn/stable/reference/tiflash/use-tiflash/
嗯,我也是这么考虑,我们一定会尝试tiflash的
感谢支持,