你好
参数中添加
–ssh-timeout int Timeout in seconds to connect host via SSH, ignored for operations that don’t need an SSH connection. (default 5)
然后tiup也部署在这个上面10.10.11.151上面,是不是这样部署有问题,现在按照你加的这个参数也还是有问题
你好,
1、 提供下 ![]()
2、提供一个 tikv 节点的 tikv.log 文件,看下。
3、检查防火墙、selinux 是否关闭
官网的 topology.yaml 完善下,
global:
user: "tidb"
ssh_port: 22
deploy_dir: "/tidb-deploy"
data_dir: "/tidb-data"
pd_servers:
- host: 10.0.1.4
- host: 10.0.1.5
- host: 10.0.1.6
tidb_servers:
- host: 10.0.1.7
- host: 10.0.1.8
- host: 10.0.1.9
tikv_servers:
- host: 10.0.1.1
- host: 10.0.1.2
- host: 10.0.1.3
tiflash_servers:
- host: 10.0.1.10
monitoring_servers:
- host: 10.0.1.4
grafana_servers:
- host: 10.0.1.4
alertmanager_servers:
- host: 10.0.1.4

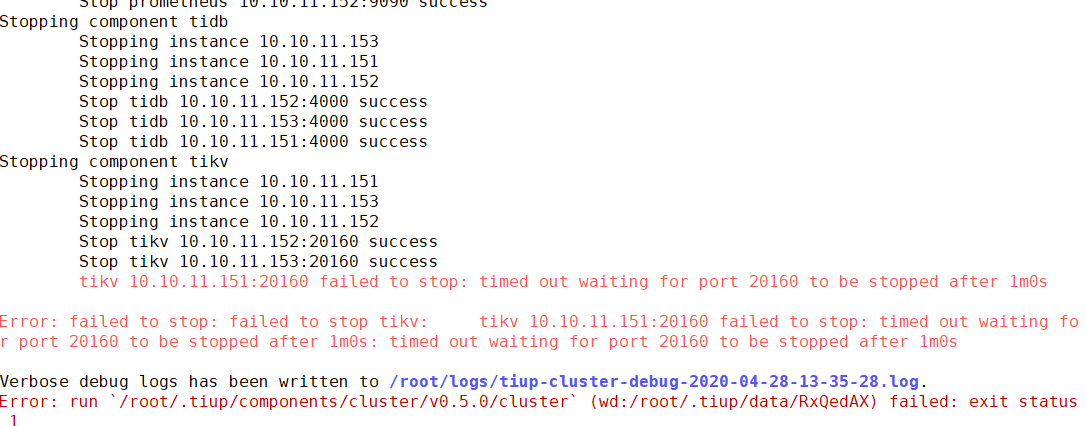
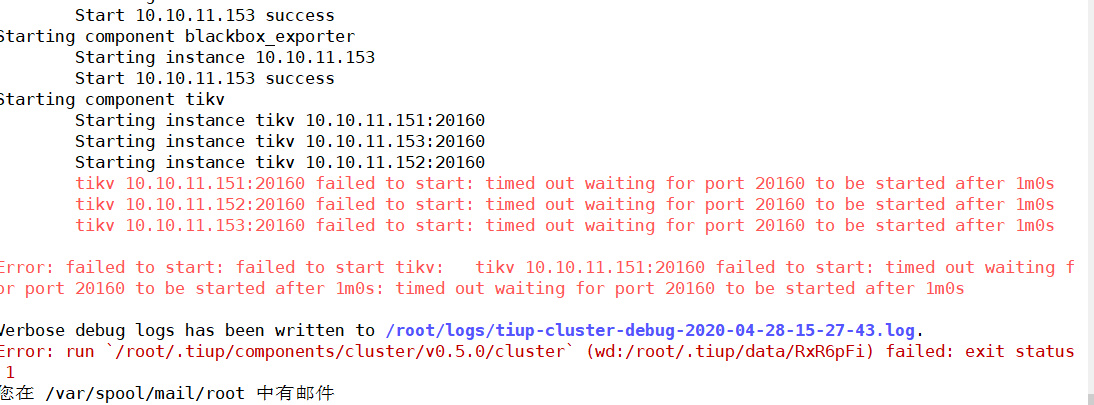
这是因为另外一个没停止吗还是什么,停启的次数比较多
你好,
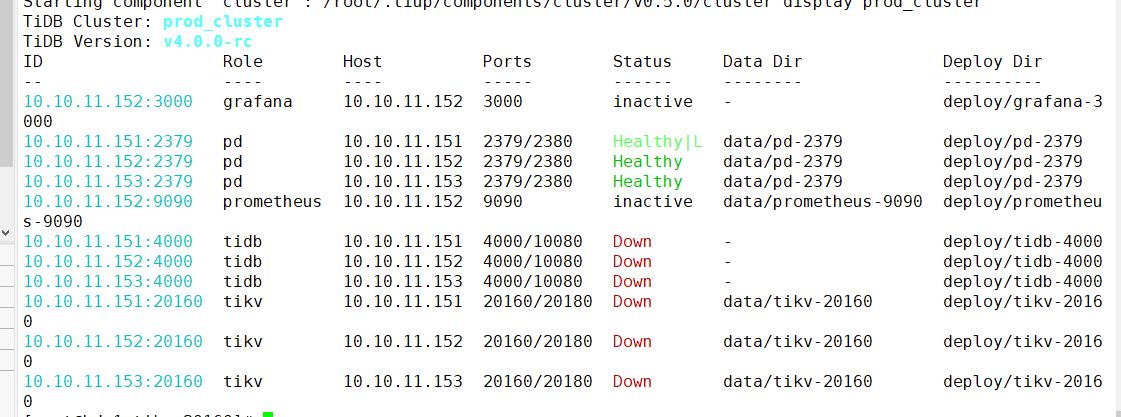
如果目前集群不健康,可以不关注此类报错,可能是其他问题导致的
应该怎么解决,11.151上启动的的集群,11.152上报的这个错,集群id 不一致
木有什么办法解决么,不健康那怎么用
你好,
不知道超时的错误是否已经解决?
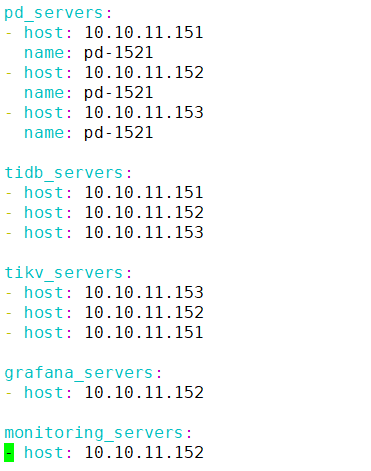
拓扑文件是否已经更新?
上传下 topology 看下,display 看下

你好,
tiup cluster stop cluster-name-
删除 {pd_date_dir}/下的文件, tiup cluster start cluster-name
尝试下
最简单的办法,尝试 执行 tiup cluster destroy cluster-name 销毁集群重新部署
OK,我这边尝试在重新全部删除,所有进程都杀掉
这边已经好了,全部删了,全部进程强制杀死,然后重新安装了一遍,现在正常
好的,如果还有其他问题,请重新开贴,感谢配合~~