TUG 华南区 4月份小组活动回顾
活动背景
本周二 12:10 在 TUG 华南区微信群里面发起读书分享的倡议,很快就得到了两位小伙伴的积极响应。
经过一些演讲者的时间安排,最终在 13:11 跟张进确定了本周六上午10点就在 TUG 华南区内部分享:《Designing Data-Intensive Application》。
《Designing Data-Intensive Application》

本期分享者
- 中国联通腾讯合作运营中心数据开发工程师
- 目前负责腾讯王卡数据平台建设
- 也是一名数据库和分布式系统的爱好者
这是一本什么样的书?
豆瓣评分高达 9.7 分。
分布式系统、数据库。
注定要成为经典的书

在开始之前,我们也来看看开源译作者的话。
数据是架构的中心
这句话是 TiDB 的黄东旭说的,但我觉得特别适合作为这本书的题记。
• DDIA用整本书的篇幅回答了一个问题: 如何设计一个数据系统?
• 读书之前,先读目录。

推荐大家阅读英文版,实在想读中文版的话,可以直接看 Github 上的翻译版本,我个人觉得这个翻译版本相比纸质版的翻译要好一些。
我与这本书的渊源
- 第一次读到此书是在在知乎上看到了一个问题: 2017 年,你看了啥 很好的计算机的博客/书/视频?
- 其实这个问题下面的书,我都看了一遍,最后只有《DDIA》成为了我的床头书。
- 第一次读这本书时,算是自己打印的原版书,啃了大概有小半年吧。
- 最后等到出了中文翻译版,便买了一本,就当做感谢作者对我的帮助。

左边是我的书,大家也可以看到我的书基本上快翻烂了。
右边是我当时淘宝下单。
我是如何去读的这本书?
那当然要就不得不说《如何阅读一本书》了。

这本书的主题是什么?
- 这本书在谈论什么东西?
- 这本书是如何讲述这个主题的?
- 它的核心章节,或者是观点是什么?
这本书讲的有道理吗?
- 这个章节讲的有道理吗?
- 他说的理论有对应的开源实现吗?
反问自己一句,读完这本书收获了多少?
- 合上眼,能对着目录讲出这个章节大概内容吗?
- 能把这本书用自己的话讲给别人听吗?
遇到了哪些困难?
- 最难的章节应该是“事务”这一节了吧,到现在我也不敢说我读懂了这一节。
- 因为读的是英文,所以没有像中文那样流畅。
- 通过写文章和阅读笔记去督促自己啃下去英文。
- 主动进行团队分享。
我还开了一个微信公众号,这些是我当时做的一些阅读笔记。

这本书带给我的收获
- 最重要的收获,当然就是帮我找到了现在的这份工作。
- 读完这本书,之后在读很多数据库和分布式系统相关的论文都轻松了很多。
- 脑海中第一次有了完整的数据系统体系。
- 比较功利的来说,这本书可以帮助你在架构选型时,知道你选择的组件有哪些合适的场景,而不至 于掉到坑里。
接下来介绍一下本书的各章节
如何评价一个数据系统?
先来看看几个指标:
-
可靠性
- 即使发生故障,系统也能 正常运行的能力
-
可扩展性
- 负载增加时,系统能有效 的保持其性能的能力
-
可维护性
- 简单、易操作、可演化
如何理解这个世界?
我们来看看下面这个模型:
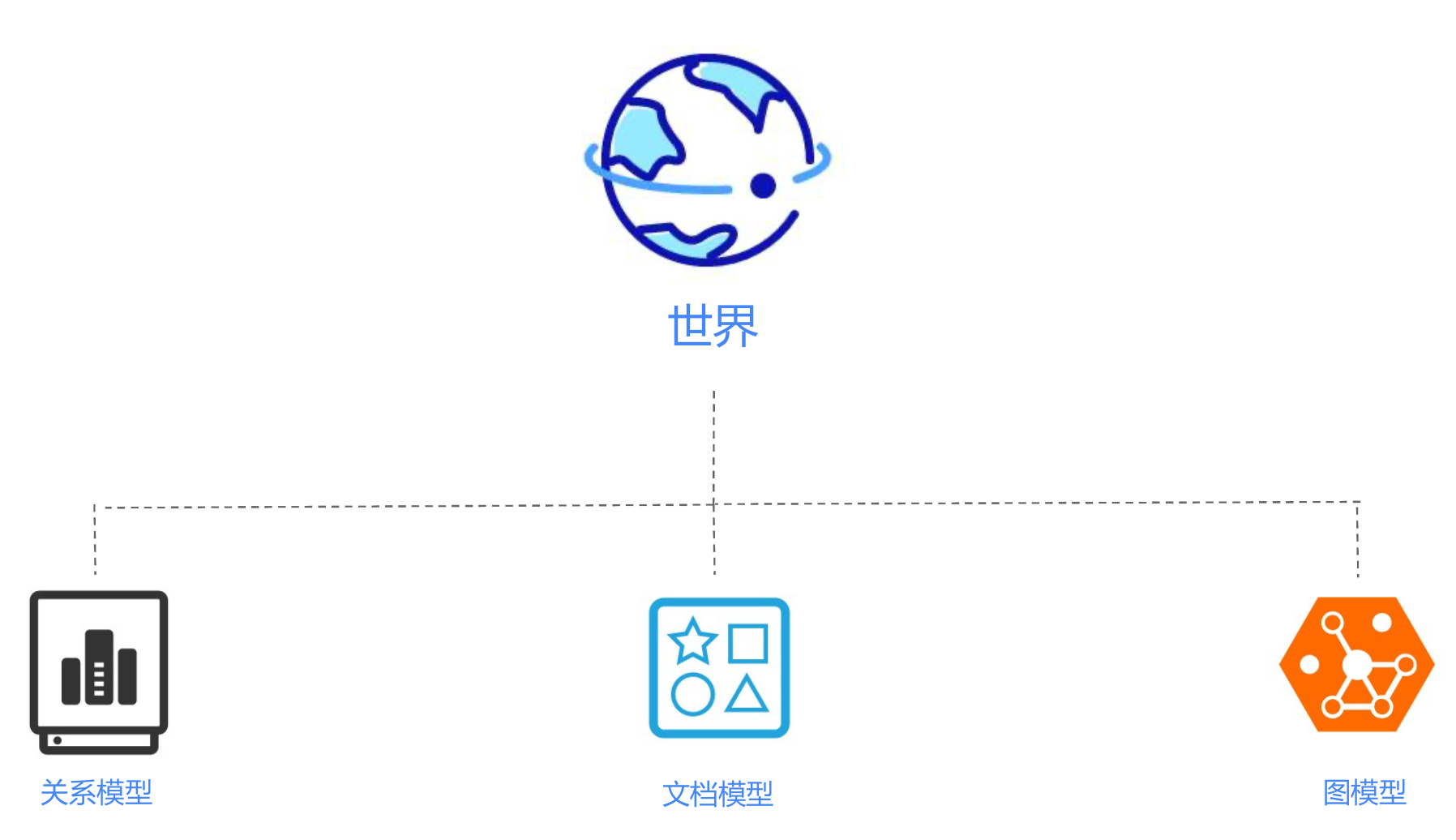
数据该如何存储?
存储引擎的设计:
- 事务分析处理(OLTP): hash, LSM tree, b tree
- 联机分析处理(OLAP): 列式存储
数据该长什么样?
编码:
普通文本:CSV、JSON、XML及其二进制格式
特定协议:Thrift 与 Protocol Buffers
特定格式:Avro
分布式系统的世界
水平拓展
- 复制与分区
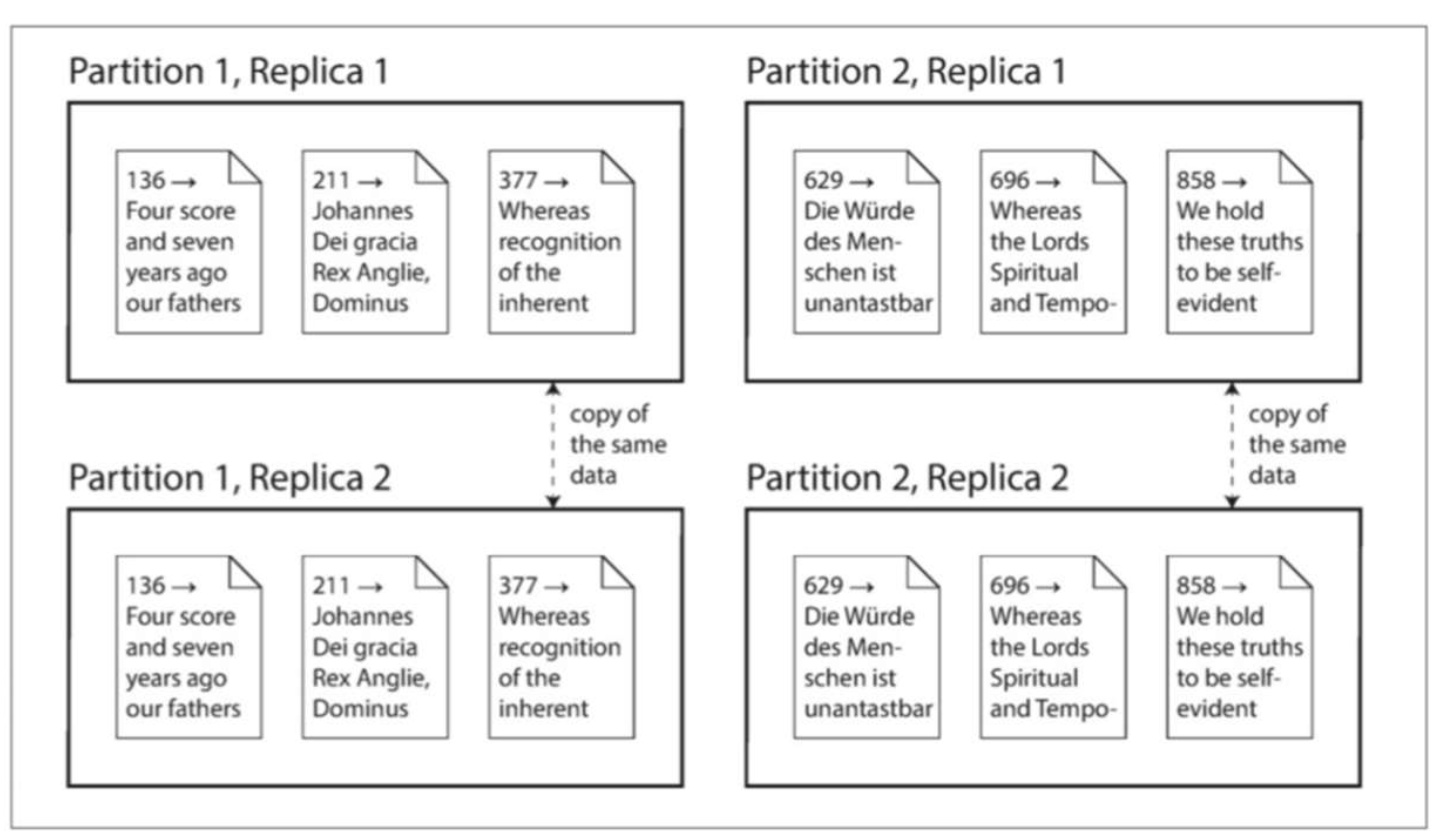
同一份数据如何备份到不同机器上
数据复制
数据复制的意义
- 高可用性
- 容错
- 低延迟
- 可扩展
数据复制的方案
- 单领导者
- 多领导者
- 无领导者
同一份数据如何分散到不同的机器上
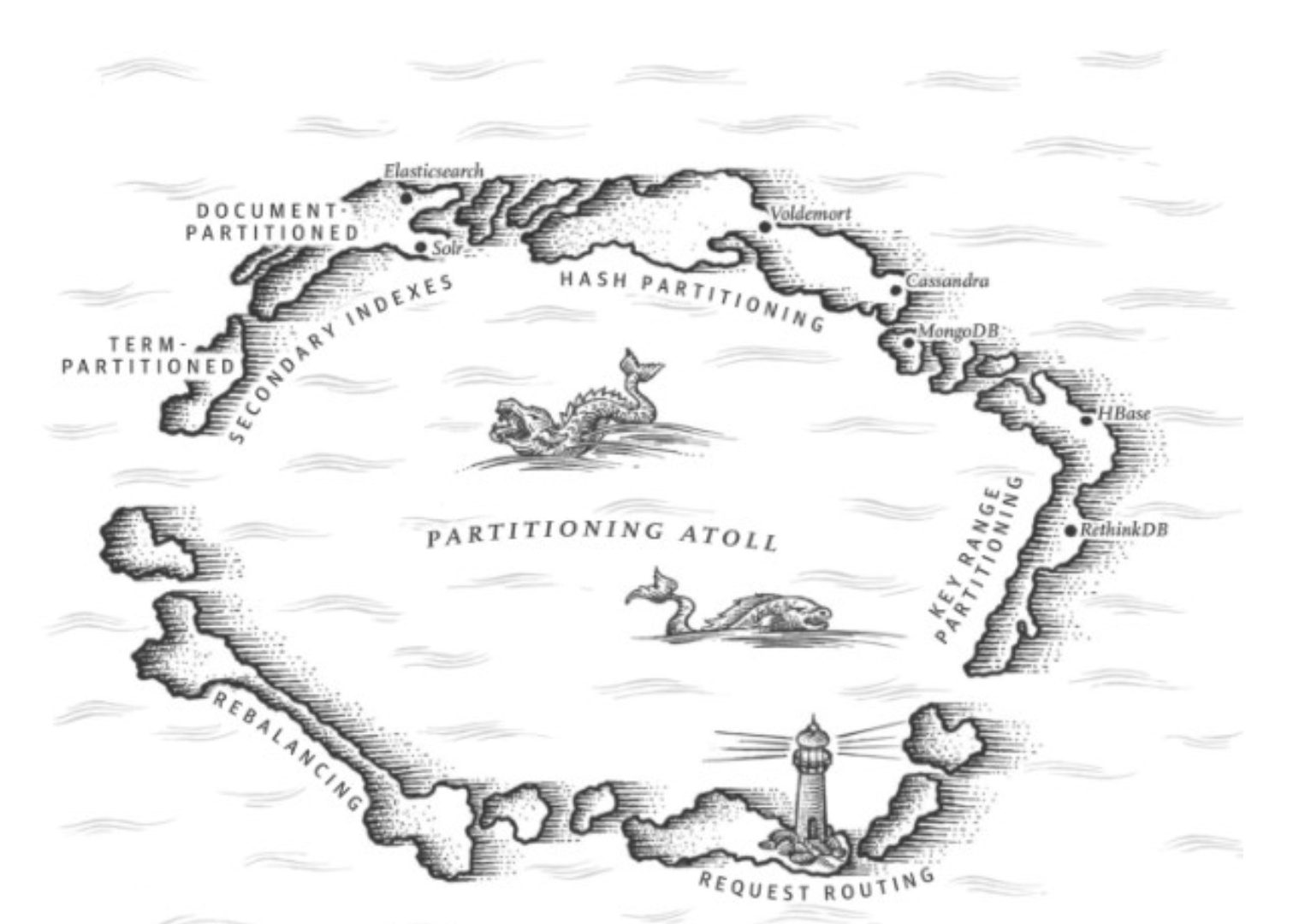
数据分区
-
分区方式
- Hash分区
- 范围分区
-
分区再平衡
-
请求路由
数据写入到一半,系统挂了怎么办?

事务
隔离级别
- 脏读
- 脏写
- 不可重复读 • 更新丢失
- 写倾斜
- 幻读
实现可串行化隔离级别
- 严格串行执行事务
- 两阶段锁
- 可串行化的快照隔离
番外:分布式系统的麻烦

- 不可靠的网络
- 不可靠的时钟
- 没有统一的共识
如何让分布式系统看起来像单机系统?
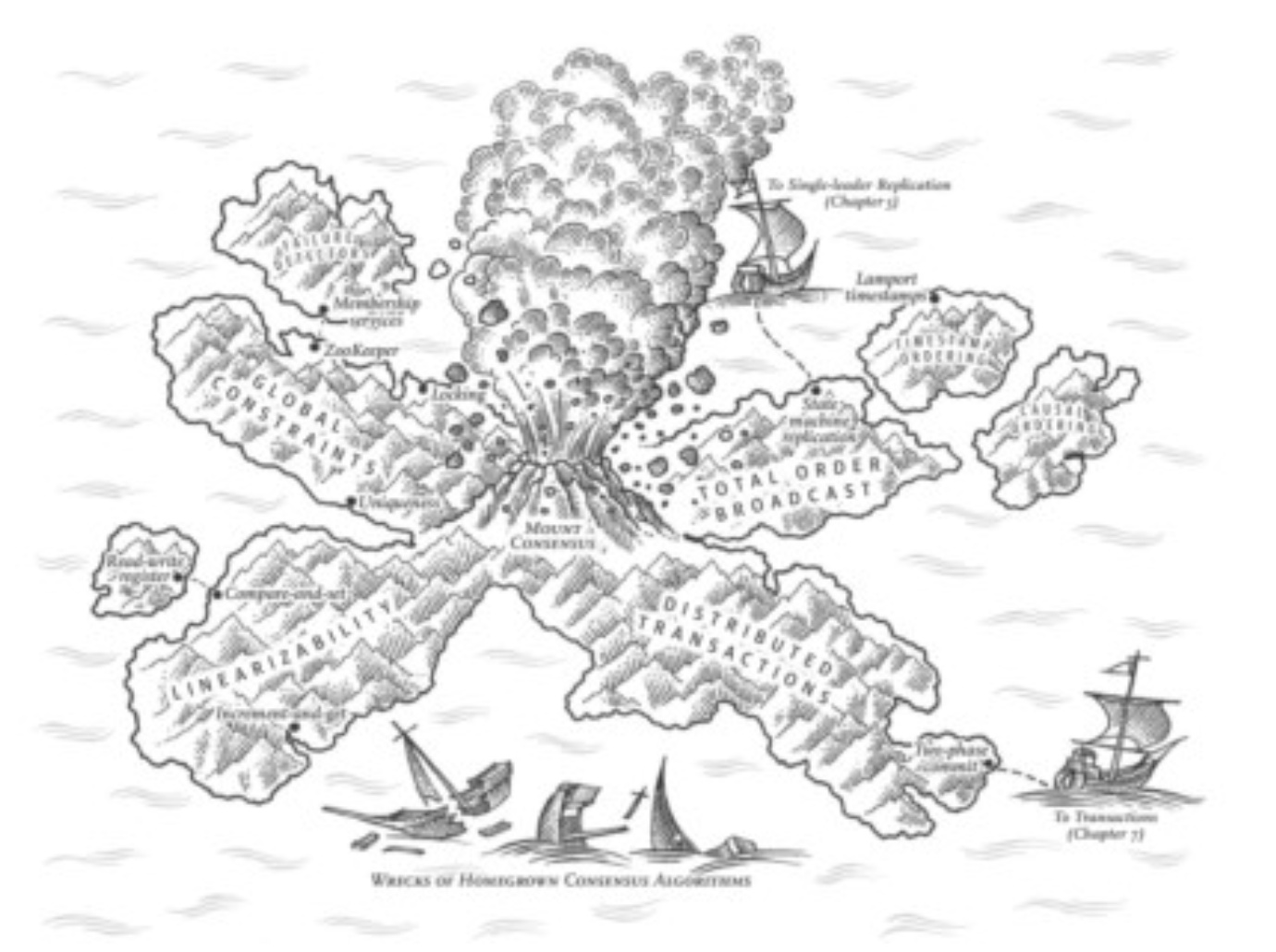
一致性与共识
-
线性一致性
- CAS寄存器
- 原子事务提交 • 全序广播
- 锁和租约
- 成员/协调服务 • 唯一性约束
派生系统
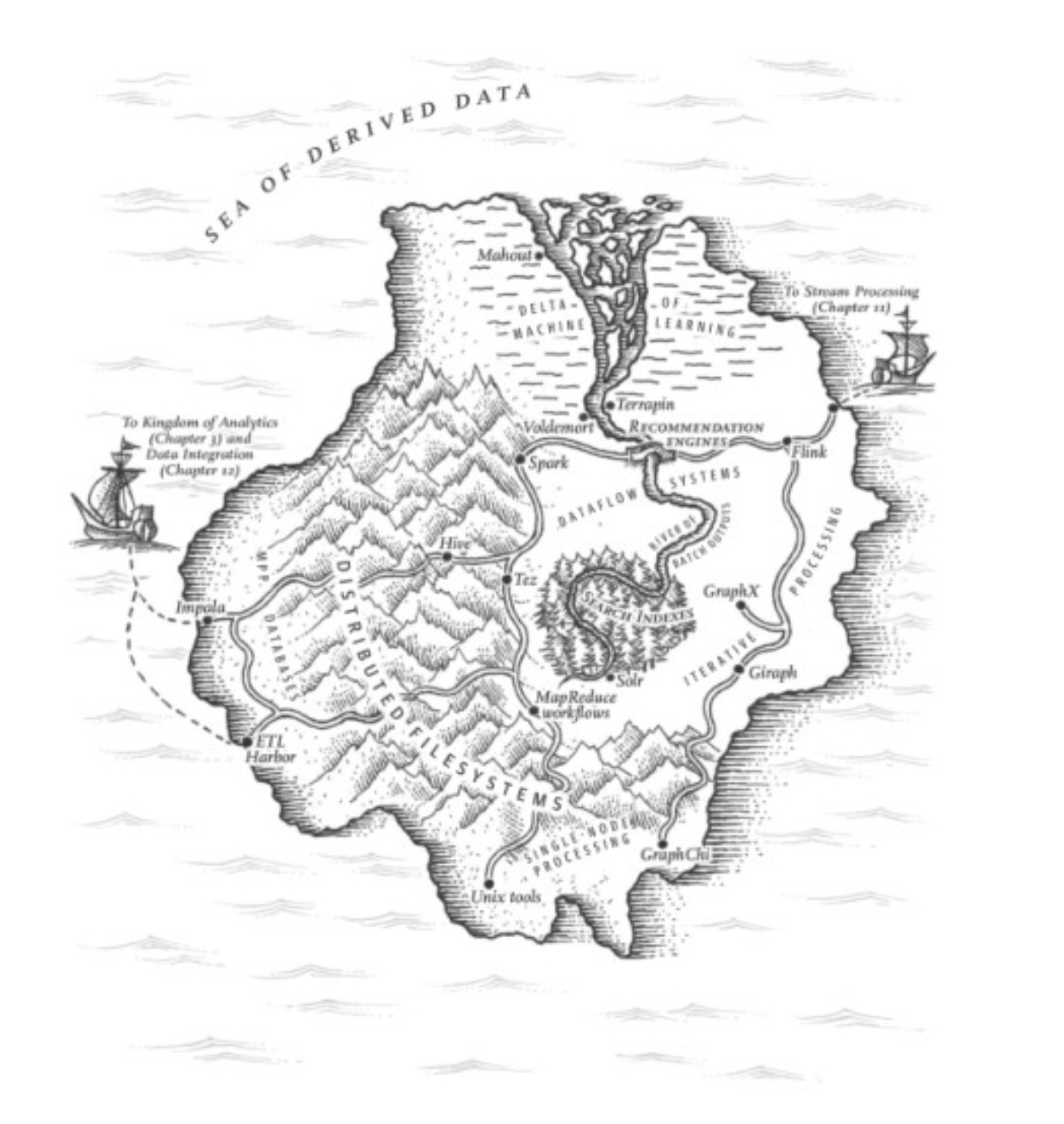
离线分析
-
核心问题
- 容错
- 数据分片
-
Unix 哲学
- MapReduce
-
Join
- 排序合并连接
- 广播散列连接
- 分区散列连接
实时分析
-
消息处理
- AMQP/JMS风格的消息代理
- 基于日志的消息代理
-
流处理中的 Join
- 流和流 join
- 流和表 join
- 表和表 join
-
容错和恰好一次语义
作者对未来的畅想
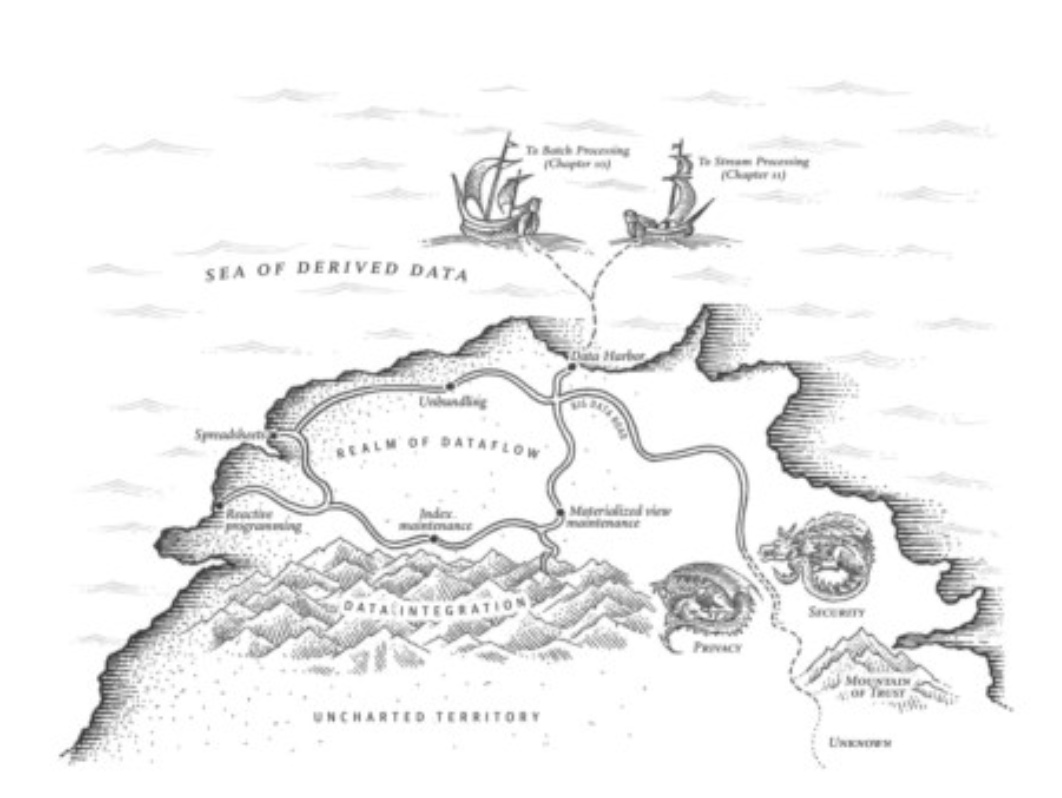
数据系统的未来
-
数据集成
- 数据流动
-
分拆数据库
- 每一个组件专注于自己的事
- 数据流:应用代码与状态变化的交互
-
将事情做正确
- 抑制重复
总结
- 这本书值得每一个做软件的人去反复阅读。
- 它类似于金庸小说里提到的武功的内力,读完此书并不会马上给你带来什么显然易见的收获,也不会直接帮助你写代码。但是,时间久了,这本书带给你的思考和认知水平的提升,也就是内力的提 升,最终会让你收获颇丰。
- 感谢 Martin Kleppmann 教授带给我们的这部经典。
YouTube
PPT
DDIA 分享.pdf (1.6 MB)
附小福利:
阅读本文或观看视频后来谈谈你的读后感,你也可以来报名下月的读书分享。
都将有机会获得房老师赞助的《数据密集型应用系统设计》。