- 【TiDB 版本】:v3.0.3
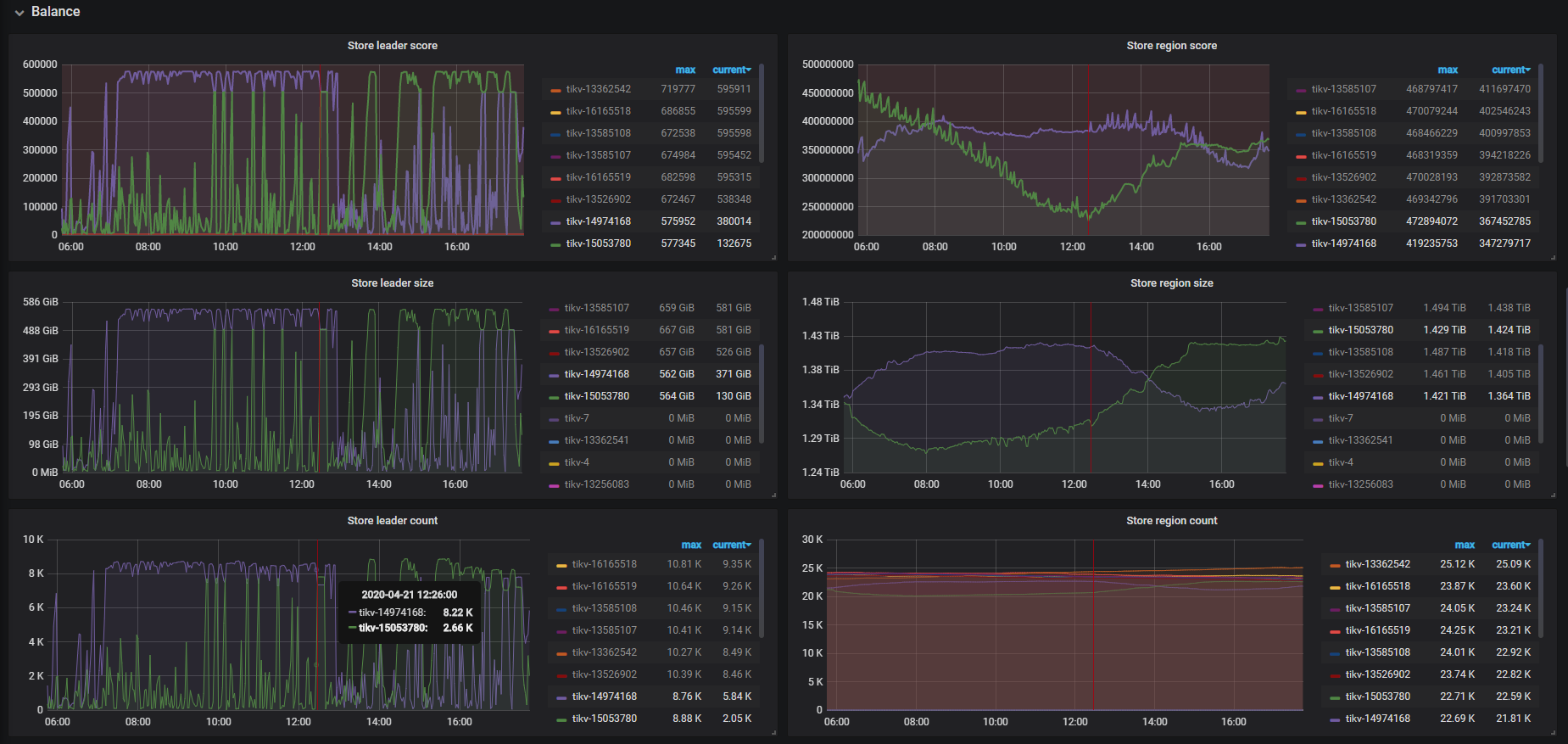
- 【问题描述】: 集群个别tikv节点的leader和region得分变化趋势,明显和其他tikv节点存在不一样,出现连续波动下降后又上升趋势,具体见图:
请问是什么原因引起?如何来解决避免?
您好:
麻烦反馈下pd-ctl的store 和member 信息,多谢
https://pingcap.com/docs-cn/v3.0/reference/tools/pd-control/#下载安装包
pd-ctl store返回结果如下: { “count”: 8, “stores”: [ { “store”: { “id”: 13585107, “address”: “192.168.8.112:20172”, “labels”: [ { “key”: “host”, “value”: “Server12” } ], “version”: “3.0.3”, “state_name”: “Up” }, “status”: { “capacity”: “400 GiB”, “available”: “131 GiB”, “leader_count”: 7831, “leader_weight”: 1, “leader_score”: 503043, “leader_size”: 503043, “region_count”: 23129, “region_weight”: 1, “region_score”: 388207686.32116985, “region_size”: 1503167, “start_ts”: “2020-03-25T14:47:08+08:00”, “last_heartbeat_ts”: “2020-04-22T09:53:45.267851181+08:00”, “uptime”: “667h6m37.267851181s” } }, { “store”: { “id”: 13585108, “address”: “192.168.8.112:20171”, “labels”: [ { “key”: “host”, “value”: “Server12” } ], “version”: “3.0.3”, “state_name”: “Up” }, “status”: { “capacity”: “400 GiB”, “available”: “131 GiB”, “leader_count”: 7886, “leader_weight”: 1, “leader_score”: 502788, “leader_size”: 502788, “region_count”: 23087, “region_weight”: 1, “region_score”: 388467914.8260646, “region_size”: 1495373, “start_ts”: “2020-02-24T12:56:12+08:00”, “last_heartbeat_ts”: “2020-04-22T09:53:44.936029011+08:00”, “uptime”: “1388h57m32.936029011s” } }, { “store”: { “id”: 14974168, “address”: “192.168.8.110:20171”, “labels”: [ { “key”: “host”, “value”: “Server10” } ], “version”: “3.0.3”, “state_name”: “Up” }, “status”: { “capacity”: “400 GiB”, “available”: “134 GiB”, “leader_count”: 7489, “leader_weight”: 1, “leader_score”: 502823, “leader_size”: 502823, “region_count”: 22439, “region_weight”: 1, “region_score”: 342493693.92874336, “region_size”: 1462718, “start_ts”: “2020-03-25T11:14:07+08:00”, “last_heartbeat_ts”: “2020-04-22T09:53:45.723725999+08:00”, “uptime”: “670h39m38.723725999s” } }, { “store”: { “id”: 16165518, “address”: “192.168.8.102:20172”, “labels”: [ { “key”: “host”, “value”: “Server02” } ], “version”: “3.0.3”, “state_name”: “Up” }, “status”: { “capacity”: “400 GiB”, “available”: “131 GiB”, “leader_count”: 7903, “leader_weight”: 1, “leader_score”: 503015, “leader_size”: 503015, “region_count”: 23300, “region_weight”: 1, “region_score”: 388070769.96702385, “region_size”: 1506462, “start_ts”: “2020-04-16T18:12:37+08:00”, “last_heartbeat_ts”: “2020-04-22T09:53:45.77473392+08:00”, “uptime”: “135h41m8.77473392s” } }, { “store”: { “id”: 16165519, “address”: “192.168.8.102:20173”, “labels”: [ { “key”: “host”, “value”: “Server02” } ], “version”: “3.0.3”, “state_name”: “Up” }, “status”: { “capacity”: “400 GiB”, “available”: “131 GiB”, “leader_count”: 7877, “leader_weight”: 1, “leader_score”: 502933, “leader_size”: 502933, “region_count”: 23577, “region_weight”: 1, “region_score”: 387224011.9178319, “region_size”: 1528240, “start_ts”: “2020-04-16T18:12:37+08:00”, “last_heartbeat_ts”: “2020-04-22T09:53:45.778911044+08:00”, “uptime”: “135h41m8.778911044s” } }, { “store”: { “id”: 13362542, “address”: “192.168.8.111:20172”, “labels”: [ { “key”: “host”, “value”: “Server11” } ], “version”: “3.0.3”, “state_name”: “Up” }, “status”: { “capacity”: “400 GiB”, “available”: “131 GiB”, “leader_count”: 7260, “leader_weight”: 1, “leader_score”: 502824, “leader_size”: 502824, “region_count”: 24761, “region_weight”: 1, “region_score”: 385579923.8984618, “region_size”: 1626967, “start_ts”: “2020-04-08T23:07:56+08:00”, “last_heartbeat_ts”: “2020-04-22T09:53:45.653217625+08:00”, “uptime”: “322h45m49.653217625s” } }, { “store”: { “id”: 13526902, “address”: “192.168.8.111:20173”, “labels”: [ { “key”: “host”, “value”: “Server11” } ], “version”: “3.0.3”, “state_name”: “Up” }, “status”: { “capacity”: “400 GiB”, “available”: “131 GiB”, “leader_count”: 7871, “leader_weight”: 1, “leader_score”: 503092, “leader_size”: 503092, “region_count”: 22843, “region_weight”: 1, “region_score”: 389534297.0428705, “region_size”: 1474959, “start_ts”: “2020-04-04T03:58:46+08:00”, “last_heartbeat_ts”: “2020-04-22T09:53:43.02950433+08:00”, “uptime”: “437h54m57.02950433s” } }, { “store”: { “id”: 15053780, “address”: “192.168.8.110:20173”, “labels”: [ { “key”: “host”, “value”: “Server10” } ], “version”: “3.0.3”, “state_name”: “Up” }, “status”: { “capacity”: “400 GiB”, “available”: “135 GiB”, “leader_count”: 7685, “leader_weight”: 1, “leader_score”: 503033, “leader_size”: 503033, “region_count”: 22284, “region_weight”: 1, “region_score”: 335901589.7735925, “region_size”: 1473911, “sending_snap_count”: 1, “start_ts”: “2020-04-10T15:52:44+08:00”, “last_heartbeat_ts”: “2020-04-22T09:53:45.776943586+08:00”, “uptime”: “282h1m1.776943586s” } } ] }
pd-ctl member返回结果如下: { “header”: { “cluster_id”: 6544922758357498172 }, “members”: [ { “name”: “pd_pd02-server04”, “member_id”: 1575038782155728736, “peer_urls”: [ “http://192.168.8.104:2380” ], “client_urls”: [ “http://192.168.8.104:2379” ] }, { “name”: “pd_pd03-server01”, “member_id”: 4892620490119213145, “peer_urls”: [ “http://192.168.8.101:2380” ], “client_urls”: [ “http://192.168.8.101:2379” ] }, { “name”: “pd_pd01-server03”, “member_id”: 18009580211031656515, “peer_urls”: [ “http://192.168.8.103:2380” ], “client_urls”: [ “http://192.168.8.103:2379” ] } ], “leader”: { “name”: “pd_pd03-server01”, “member_id”: 4892620490119213145, “peer_urls”: [ “http://192.168.8.101:2380” ], “client_urls”: [ “http://192.168.8.101:2379” ] }, “etcd_leader”: { “name”: “pd_pd03-server01”, “member_id”: 4892620490119213145, “peer_urls”: [ “http://192.168.8.101:2380” ], “client_urls”: [ “http://192.168.8.101:2379” ] } }
您好:
1. 从您当前反馈的store信息来看,是均衡的

2. 有时候某个store的region信息变化,可能是由于有DDL或者gc后数据的重新balance,最终region数量和leader数据一致,基本是正常的。
这个是早上平衡时执行指令获取的瞬时状态是正常的,从可视化监视图可以看出leader和region得分变化波动很大,想请教一下这个得分是怎么计算出来的?什么因素会影响这个得分从而造成波动?
可以看下这个帖子
将与tikv-15053780同节点的tikv-14974168下线后,发现tikv-15053780的leader score/size出现了新的变化:波动区间范围明显变小小于其他节点值的水平,具体见下图:
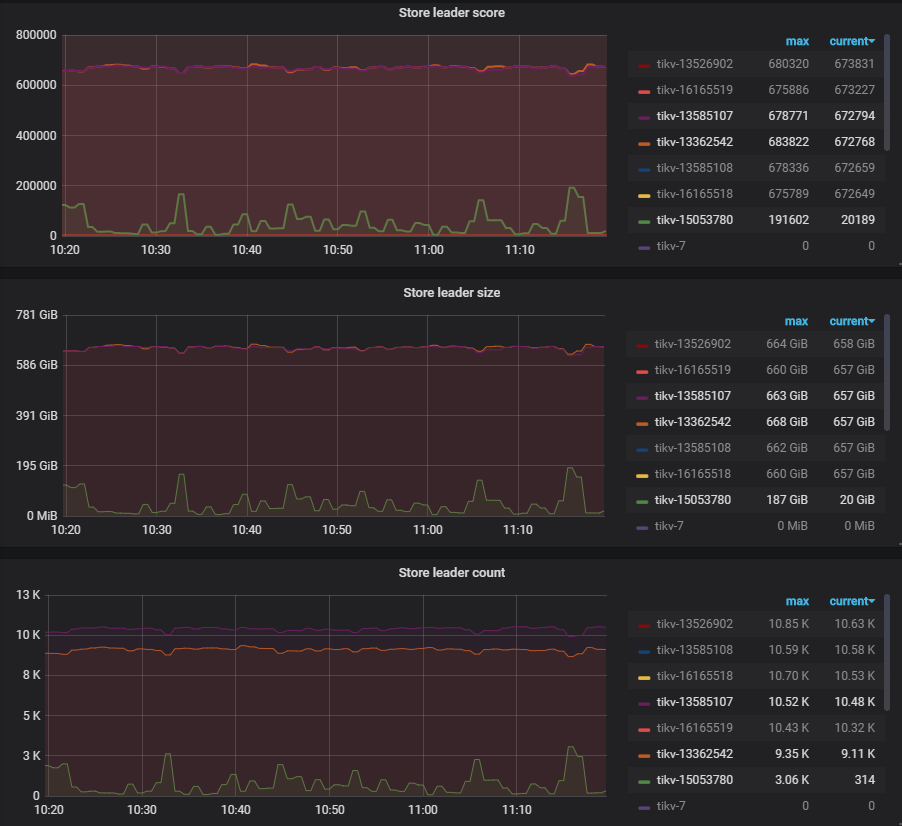
感觉leader size增长到一定值后就见顶拉下来了,请问这个tikv-15053780实例leader size 和score的这种不同于其他正常节点变化是由什么因素引起? 该如何将其恢复到和其他节点正常的状态?
正在分析请稍等
您好: 1. 麻烦还是反馈下pd-ctl store的信息 2. region score的监控信息也麻烦反馈下,多谢
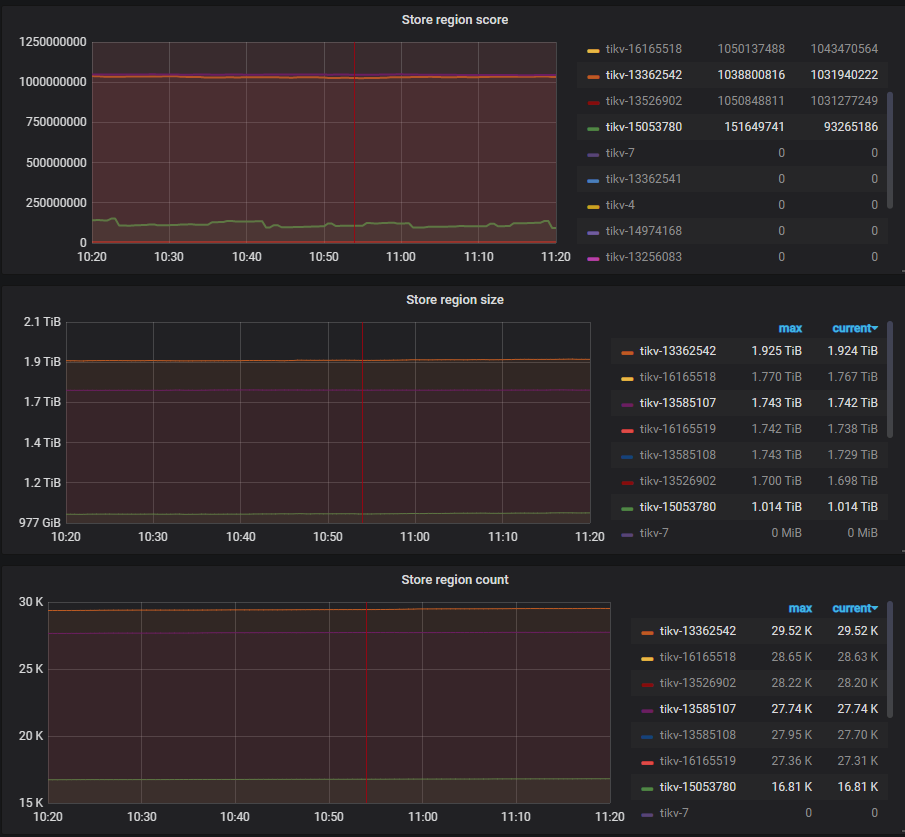
pd-ctl store信息如下: { “count”: 7, “stores”: [ { “store”: { “id”: 16165519, “address”: “192.168.8.102:20173”, “labels”: [ { “key”: “host”, “value”: “Server02” } ], “version”: “3.0.3”, “state_name”: “Up” }, “status”: { “capacity”: “400 GiB”, “available”: “84 GiB”, “leader_count”: 9735, “leader_weight”: 1, “leader_score”: 646800, “leader_size”: 646800, “region_count”: 27265, “region_weight”: 1, “region_score”: 1024291683.7199063, “region_size”: 1818744, “start_ts”: “2020-04-16T18:12:37+08:00”, “last_heartbeat_ts”: “2020-04-24T14:59:16.891623745+08:00”, “uptime”: “188h46m39.891623745s” } }, { “store”: { “id”: 13585107, “address”: “192.168.8.112:20172”, “labels”: [ { “key”: “host”, “value”: “Server12” } ], “version”: “3.0.3”, “state_name”: “Up” }, “status”: { “capacity”: “400 GiB”, “available”: “84 GiB”, “leader_count”: 9699, “leader_weight”: 1, “leader_score”: 627775, “leader_size”: 627775, “region_count”: 27445, “region_weight”: 1, “region_score”: 1024375212.9298496, “region_size”: 1809246, “start_ts”: “2020-03-25T14:47:08+08:00”, “last_heartbeat_ts”: “2020-04-24T14:59:15.454258952+08:00”, “uptime”: “720h12m7.454258952s” } }, { “store”: { “id”: 13585108, “address”: “192.168.8.112:20171”, “labels”: [ { “key”: “host”, “value”: “Server12” } ], “version”: “3.0.3”, “state_name”: “Up” }, “status”: { “capacity”: “400 GiB”, “available”: “84 GiB”, “leader_count”: 9858, “leader_weight”: 1, “leader_score”: 627442, “leader_size”: 627442, “region_count”: 27757, “region_weight”: 1, “region_score”: 1022688840.0837064, “region_size”: 1813256, “start_ts”: “2020-02-24T12:56:12+08:00”, “last_heartbeat_ts”: “2020-04-24T14:59:17.803884545+08:00”, “uptime”: “1442h3m5.803884545s” } }, { “store”: { “id”: 16165518, “address”: “192.168.8.102:20172”, “labels”: [ { “key”: “host”, “value”: “Server02” } ], “version”: “3.0.3”, “state_name”: “Up” }, “status”: { “capacity”: “400 GiB”, “available”: “83 GiB”, “leader_count”: 10019, “leader_weight”: 1, “leader_score”: 642294, “leader_size”: 642294, “region_count”: 28542, “region_weight”: 1, “region_score”: 1027695369.7387671, “region_size”: 1847508, “start_ts”: “2020-04-16T18:12:37+08:00”, “last_heartbeat_ts”: “2020-04-24T14:59:11.428344205+08:00”, “uptime”: “188h46m34.428344205s” } }, { “store”: { “id”: 13362542, “address”: “192.168.8.111:20172”, “labels”: [ { “key”: “host”, “value”: “Server11” } ], “version”: “3.0.3”, “state_name”: “Up” }, “status”: { “capacity”: “400 GiB”, “available”: “84 GiB”, “leader_count”: 8607, “leader_weight”: 1, “leader_score”: 635007, “leader_size”: 635007, “region_count”: 29565, “region_weight”: 1, “region_score”: 1027391890.4165349, “region_size”: 2016444, “start_ts”: “2020-04-23T12:27:50+08:00”, “last_heartbeat_ts”: “2020-04-24T14:59:15.686723964+08:00”, “uptime”: “26h31m25.686723964s” } }, { “store”: { “id”: 13526902, “address”: “192.168.8.111:20173”, “labels”: [ { “key”: “host”, “value”: “Server11” } ], “version”: “3.0.3”, “state_name”: “Up” }, “status”: { “capacity”: “400 GiB”, “available”: “84 GiB”, “leader_count”: 10124, “leader_weight”: 1, “leader_score”: 627534, “leader_size”: 627534, “region_count”: 28395, “region_weight”: 1, “region_score”: 1024884042.7261806, “region_size”: 1792018, “start_ts”: “2020-04-04T03:58:46+08:00”, “last_heartbeat_ts”: “2020-04-24T14:59:14.528526052+08:00”, “uptime”: “491h0m28.528526052s” } }, { “store”: { “id”: 15053780, “address”: “192.168.8.110:20173”, “labels”: [ { “key”: “host”, “value”: “Server10” } ], “version”: “3.0.3”, “state_name”: “Up” }, “status”: { “capacity”: “400 GiB”, “available”: “158 GiB”, “leader_count”: 3942, “leader_weight”: 1, “leader_score”: 249745, “leader_size”: 249745, “region_count”: 16993, “region_weight”: 1, “region_score”: 34805248.94462633, “region_size”: 1073031, “start_ts”: “2020-04-23T17:49:34+08:00”, “last_heartbeat_ts”: “2020-04-24T14:59:17.150006146+08:00”, “uptime”: “21h9m43.150006146s” } } ] }
您好:
1. 从结果看Server10当前score分数和其他不大一致,可用空间也较多.
2. 能否上传inventory.ini文件,并且执行df -h 在 tikv 服务器上
每个 服务器有两个 tikv实例,请问是使用同一个根目录吗?inventory.ini (3.2 KB)
每个服务器上的两个tikv实例,都是各自使用自己的根目录,对应/TiDBDisk*,一个目录对应挂载的是一个单独的SSD固态盘。各tikv节点df结果如下:
Filesystem Size Used Avail Use% Mounted on
Server02:
/dev/nvme0n1p1 493G 369G 100G 79% /TiDBDisk1
/dev/nvme1n1p1 493G 374G 94G 80% /TiDBDisk2
Server10:
/dev/nvme1n1p1 504G 262G 217G 55% /TiDBDisk2
/dev/nvme0n1p1 504G 35G 444G 8% /TiDBDisk1
Server11:
/dev/nvme1n1p1 493G 365G 104G 78% /TiDBDisk1
/dev/nvme0n1p1 493G 367G 102G 79% /TiDBDisk0
Server12:
/dev/nvme1n1p1 493G 366G 102G 79% /TiDBDisk1
/dev/nvme0n1p1 493G 366G 102G 79% /TiDBDisk0
Server10当前score分数的明显与其他不一致,会是什么影响导致的呢?如果leader score仅取决于leader size的话,那leader score波动大代表着leader size也变化大,什么因素会导致leader size出现这种大幅度的变化呢?观察grafana可视化监视看到这个问题Store对应ssd的IOUtil长时间一直处于接近100%的水平,会跟这个有关系吗?另外,pd-ctl store查询出的这个问题Store的状态会偶尔出现Disconnected状态,也会有关系吗?
建议可以发下对应抖动比较剧烈的时间区间里面 PD operator 相关的监控以及 pd-ctl config show 的输出
- Server10 分数与其他不一致是因为可用空间大小与其他 store 存在明显差别。pd 计算分数的时候采取的是分段的策略。在空间小于某个阈值的时候会考虑剩余空间容量。 如果确实有大量调度产生,想减轻 region 的抖动,大致有两种思路: (1)可以尝试通过 pd-ctl 调整 low-space-ratio 和 high-space-ratio,比如 0.1 和 0.15。目的是提高这个阈值,避免可用空间变化带来的波动。不过需要自己多留意剩余空间。 (2)通过调整 tolerant-size-ratio 到比如 20 或者更大,目的是提高 balance region 产生调度的门槛,避免过度的调度带来的影响。可能存在的问题就是,稳定后可能存在少量空间的差异
- leader 产生调度可能有多种情况,比如热点等。IO 负载高导致 tikv 卡住了,也有可能会导致 leader 产生调度
pd-ctl config show输出如下:{
“replication”: {
“location-labels”: “host”,
“max-replicas”: 3,
“strictly-match-label”: “false”
},
“schedule”: {
“disable-location-replacement”: “false”,
“disable-make-up-replica”: “false”,
“disable-namespace-relocation”: “false”,
“disable-raft-learner”: “false”,
“disable-remove-down-replica”: “false”,
“disable-remove-extra-replica”: “false”,
“disable-replace-offline-replica”: “false”,
“enable-one-way-merge”: “false”,
“high-space-ratio”: 0.6,
“hot-region-cache-hits-threshold”: 3,
“hot-region-schedule-limit”: 4,
“leader-schedule-limit”: 64,
“low-space-ratio”: 0.8,
“max-merge-region-keys”: 0,
“max-merge-region-size”: 0,
“max-pending-peer-count”: 16,
“max-snapshot-count”: 3,
“max-store-down-time”: “1h0m0s”,
“merge-schedule-limit”: 20,
“patrol-region-interval”: “100ms”,
“region-schedule-limit”: 16,
“replica-schedule-limit”: 24,
“scheduler-max-waiting-operator”: 3,
“schedulers-v2”: [
{
“args”: null,
“disable”: false,
“type”: “balance-region”
},
{
“args”: null,
“disable”: false,
“type”: “balance-leader”
},
{
“args”: null,
“disable”: false,
“type”: “hot-region”
},
{
“args”: null,
“disable”: false,
“type”: “label”
},
{
“args”: [
“9”
],
“disable”: false,
“type”: “evict-leader”
},
{
“args”: [
“13526901”
],
“disable”: false,
“type”: “evict-leader”
},
{
“args”: [
“14974168”
],
“disable”: false,
“type”: “evict-leader”
}
],
“split-merge-interval”: “1h0m0s”,
“store-balance-rate”: 15,
“tolerant-size-ratio”: 2.5
}
}
PD operator 监控如下:

另外,我还注意到grafana监视中问题tikv节点的Apply log duration per server、Append log duration per server、Process ready duration per server指标与其他节点相比明显偏高,具体见下图:
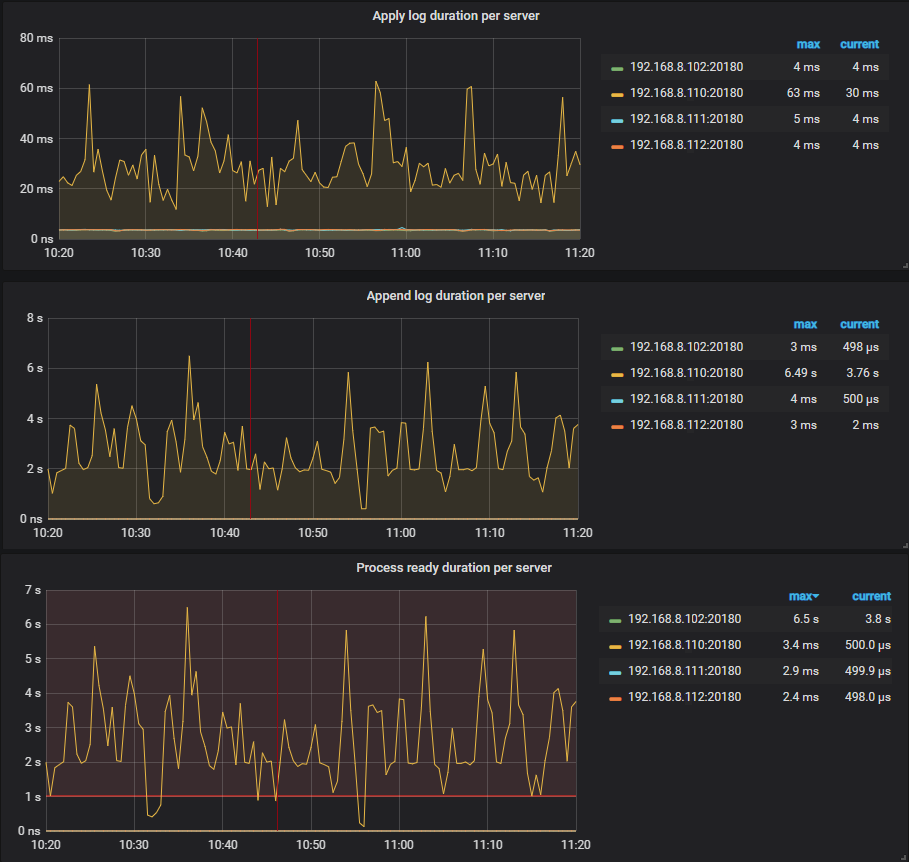
leader-schedule-limit 这个参数在 3.0 中的应该默认是 4 建议可以调至默认值,关于 Apply log duration per server 等参数搞的问题,可以看看 TiKV 监控中 grpc 请求数量是否均衡,以及 thread cpu 是否均衡