为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】:
v3.0.12 - 【问题描述】:
我们目前的使用情境会在 TiDB 上建立大量的 database (数量约 1 万个)
每个 database 裡面大约有 10 张 table, 总 Regions 数量目前约 8 万个
stress 一阵子后我们发现 TiDB Server 的 memory 用量会持续上升
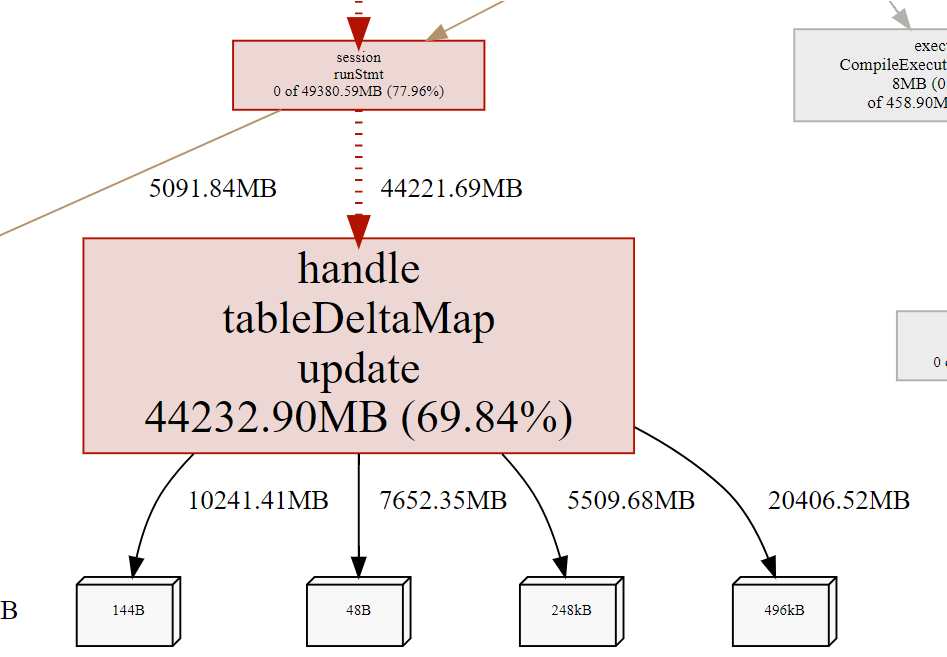
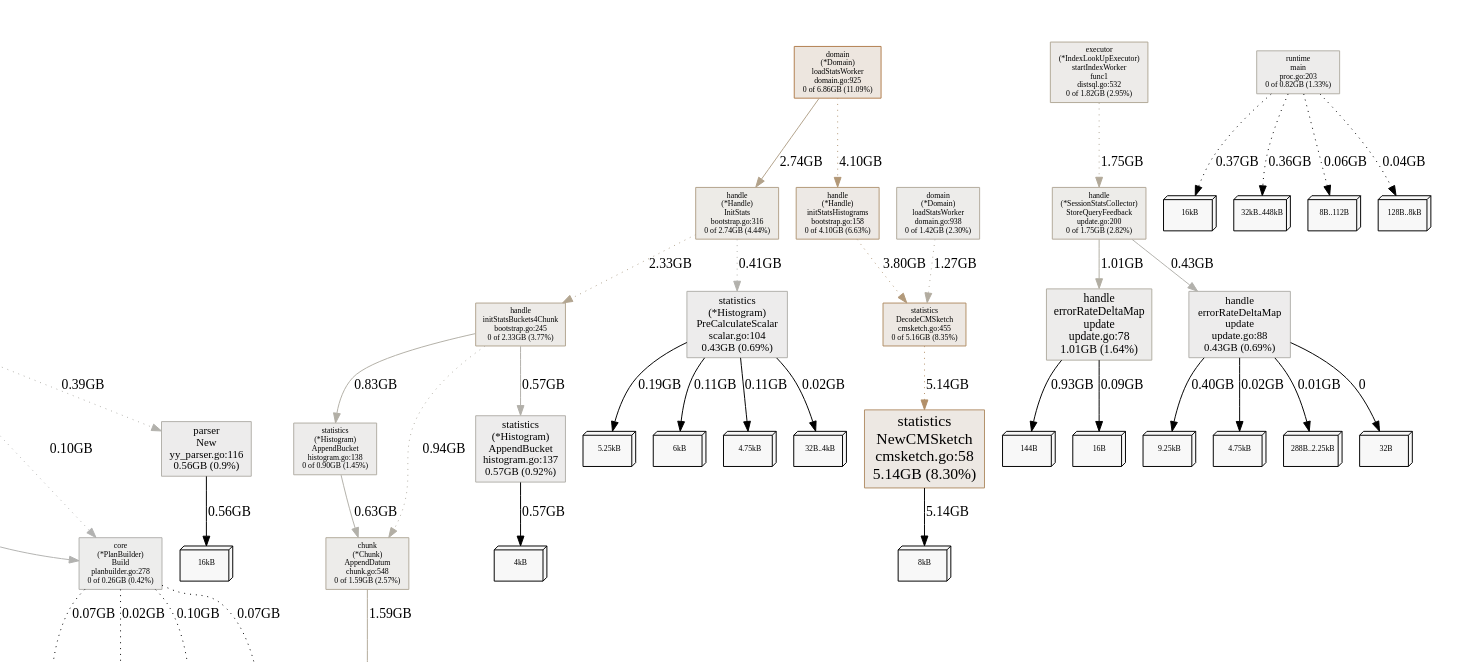
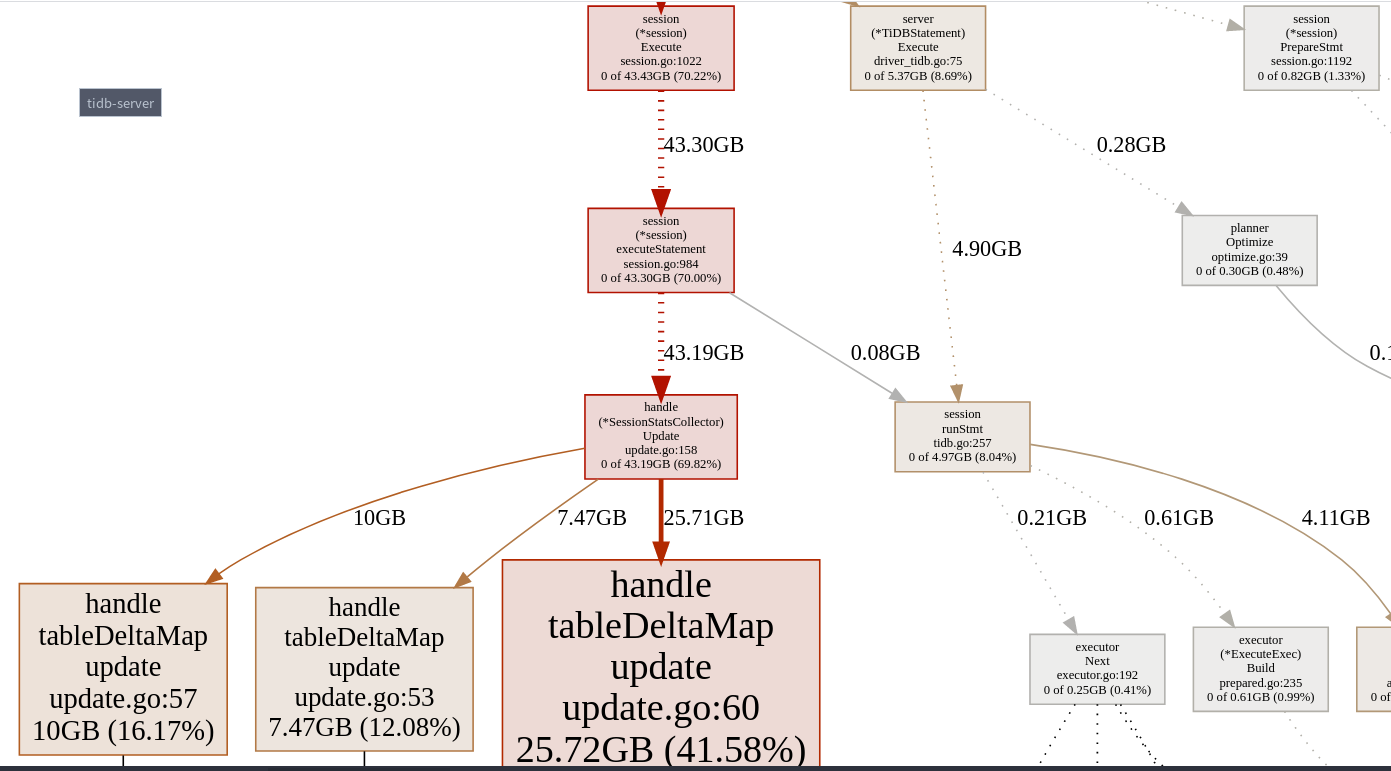
透过 pprof 查看主要 memory 上升的部分为 statistics 的 handle.tableDeltaMap.update
Fetching profile over HTTP from http://10.244.3.4:10080/debug/pprof/heap
Saved profile in /root/pprof/pprof.tidb-server.alloc_objects.alloc_space.inuse_objects.inuse_space.099.pb.gz
File: tidb-server
Type: inuse_space
Time: Apr 21, 2020 at 2:36am (UTC)
Entering interactive mode (type "help" for commands, "o" for options)
(pprof) top
Showing nodes accounting for 56.76GB, 91.76% of 61.85GB total
Dropped 965 nodes (cum <= 0.31GB)
Showing top 10 nodes out of 82
flat flat% sum% cum cum%
43.20GB 69.84% 69.84% 43.20GB 69.84% github.com/pingcap/tidb/statistics/handle.tableDeltaMap.update
5.16GB 8.34% 78.17% 5.16GB 8.34% github.com/pingcap/tidb/statistics.NewCMSketch
1.75GB 2.82% 81.00% 1.75GB 2.82% github.com/pingcap/tidb/statistics/handle.errorRateDeltaMap.update
以下是透过 list 查看 handle.tableDeltaMap.update 的结果
(pprof) list github.com/pingcap/tidb/statistics/handle.tableDeltaMap.update
Total: 61.85GB
ROUTINE ======================== github.com/pingcap/tidb/statistics/handle.tableDeltaMap.update in /home/jenkins/agent/workspace/tidb_v3.0.12/go/src/github.com/pingcap/tidb/statistics/handle/update.go
43.20GB 43.20GB (flat, cum) 69.84% of Total
. . 48:func (m tableDeltaMap) update(id int64, delta int64, count int64, colSize *map[int64]int64) {
. . 49: item := m[id]
. . 50: item.Delta += delta
. . 51: item.Count += count
. . 52: if item.ColSize == nil {
7.47GB 7.47GB 53: item.ColSize = make(map[int64]int64)
. . 54: }
. . 55: if colSize != nil {
1MB 1MB 56: for key, val := range *colSize {
10GB 10GB 57: item.ColSize[key] += val
. . 58: }
. . 59: }
25.72GB 25.72GB 60: m[id] = item
. . 61:}
. . 62:
. . 63:type errorRateDelta struct {
. . 64: PkID int64
. . 65: PkErrorRate *statistics.ErrorRate
我们的理解是每个 session 都会建立自己的 SessionStatsCollector
如果这个 session 处理过很多张 table, 则这个 SessionStatsCollector 裡面的 mapper 就会长得比较大, 直到 session close 才会把内存释放出来
我们有尝试让 client connection 每隔 30 分钟重新建立连线,让 session 不会一直使用
理论上这样 session 被关闭后应该会把 memory 放出来才对? 但实际测试起来 memory 还是持续升高
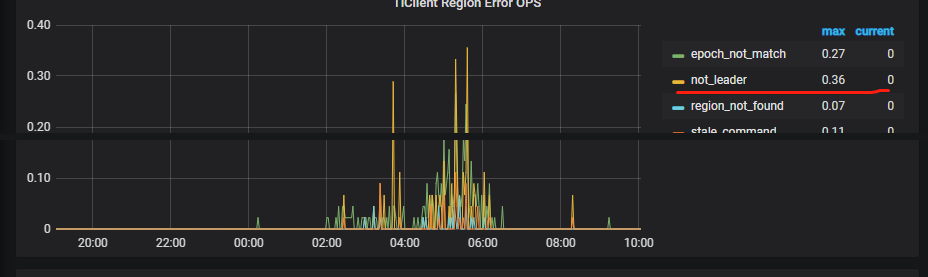
虽然一晚的测试中间有一度往下降 (20:00 & 03:30),但后续还是一直爬升
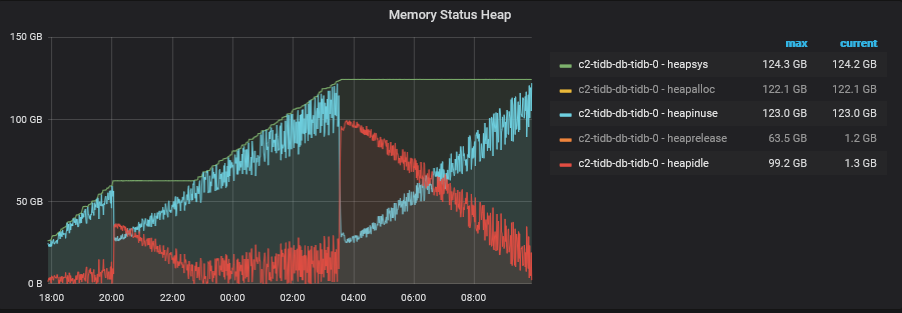
如果把测试停止 (client 不继续发送 request),则 memory 很快就降下来,透过 pprof 查看 handle.tableDeltaMap.update 的用量都会释放
以下是抓取下来的 pprof 档
pprof.tidb-server.pb.gz (368.0 KB)
【 我的疑问 】
想询问一下老师是否有什麽建议? 另外 TiDB 如果用在这样有大量 database 与 table 的状况下,有没有什麽要特别注意的地方? 谢谢