本文作者王碧虹,发表时间 2018/03/01。
背景介绍
收益支持系统(Revenue Support System,简称 RSS)是海航易建科技与香港航空共同研发的基于大数据实时分析处理的航空业务支持和决策系统。RSS 的目标在于根据顾客需求进行市场细分和定价,在科学分析的基础上通过价格和座位库存控制手段平衡需求和供给的关系,将产品销售给合适的旅客,其核心价值在于支撑和帮助航空公司业务人员和决策者进行业务管理和科学决策。 RSS 在航空公司角色和定位,决定了该系统对 OLAP 和 OLTP 的操作在准确性和实时性方面具有很高的要求,并且由于航空公司每天产生海量的订票、值机、离港和财务数据,使得要求系统在数据存储方面要有很好的水平扩展能力。
前期方案
前期我们主要使用 MySQL 数据库,但是单表记录大于 2000 万行时,现有的业务报表查询和导出操作明显变慢,通过各种 sql 调优和代码优化手段,也无法继续满足服务等级协议,只能通过分库分表来解决,但是这会增加的后续业务逻辑开发复杂度与数据库运维困难。后来,随着业务的深入和数据的积累,代理人在全球各个全球分销系统(Global Distribution System,GDS)中的订座数据数据(Marketing Information Data Tapes,MIDT)就近2年的数据就超过 3.8 亿行,后续会同步近 10 年的数据,初步预估单表数据量将突破10亿条数据,并且后续每年的正常量可能会突破 2 亿条,如果继续使用 MySQL,必然面临着更细粒度分库、分表的难题,而且当前业界很多分表分库的中间件对 OLAP 支持的并不完美,而且很难满足复杂的 OLAP 需求,并且需要进行分表策略的额外配置。这样必然加大了开发和运维的难度和降低了开发的灵活性。
在这个过程中,我们曾经使用 HDFS + Hive + Spark + Kylin 作为大数据解决方案,但是这个方案对于实时的OLTP却满足不了。
为了满足两者的需求,我们需要把一份大数据存储两份,MySQL + 分表中间件做 OLTP 操作,HDFS + Hive + Spark + Kylin 做 OLAP 分析。
茅塞顿开
在业务遇到不可妥协的技术瓶颈后,我们重新评估业务模型,发现对于数据库的选型必须满足:
- 支持业务弹性的水平扩容与缩容;
- 支持 MySQL 便捷稳定的迁移,不影响线上业务;
- 支持 SQL 和复杂的查询,尽量少的改动代码;
- 满足业务故障自恢复的高可用,且易维护;
- 强一致的分布式事务处理;
为了解决上述问题,我们发现了 TiDB、CockroachDB 与 oceanbase 这三款分布式的数据库。由于 CockroachDB 是支持 Postgresql 数据库,我们是 MySQL 的协议,oceanbase 发布在阿里云,我们的数据属于收益核心数据需要发布在集团内部,这样一来 TiDB 成了我们选择。TiDB 数据库完美的支持了 MySQL 的 SQL 语法,它可是让我们不改变平时用 MySQL 的操作习惯。并且能够很好的满足我们的 OLTP 需求和复杂的 OLAP 的需求。另外 TiSpark 是建立在 Spark 引擎之上的,Spark 在机器学习领域上还是比较成熟的。考虑到收益系统未来会涉及到一些预测分析,会需要用到机器学习。综合这些考虑,TiDB + TiSpark 成为了我们首选的技术解决方案。
后续我们了解到饿了么的80%的核心流程都跑在tidb的高性能集群上面,还有新一代的互联网代表企业摩拜、今日头条,以及机票行业的qunar都有tidb的深度应用。
TiDB简介
TiDB项目在世界上最流行的开源代码托管平台 GitHub 上共计已获得 10000+ Star,项目集合了 150 多位来自全球的 Contributors (代码贡献者)。
TiDB是 PingCAP 公司受 Google Spanner / F1论文启发而设计的开源分布式 NewSQL 数据库。TiDB 具备如下NewSQL 核心特性:
- SQL 支持(TiDB 是 MySQL 兼容的)
- 水平线性弹性扩展
- 分布式事务
- 跨数据中心数据强一致性保证
- 故障自恢复的高可用
TiDB 适用于 100% 的 OLTP 场景和 80% 的 OLAP 场景。对业务没有任何侵入性,能优雅的替换传统的数据库中间件、数据库分库分表等 Sharding 方案。同时它也让开发运维人员不用关注数据库 Scale 的细节问题,专注于业务开发,极大的提升研发的生产力。
参考:TiDB 简介
TiDB的架构
TiDB 集群主要分为三个组件: TiDB Server、TiKVServer、PD Server ,整体实现架构如下:

TiDB 整体架构图
TiDB Server
TiDB Server 主要负责接收 SQL 请求,处理 SQL 相关的逻辑,并通过 PD 找到存储计算所需数据的 TiKV 地址,与 TiKV 交互获取数据,最终返回结果。 TiDB Server 是无状态的,其本身并不存储数据,只负责计算,可以无限水平扩展,可以通过负载均衡组件(如 LVS、HAProxy 或 F5)对外提供统一的接入地址。
PD Server
PlacementDriver (简称 PD) 是整个集群的管理模块,其主要工作有三个:
- 存储集群的元信息(某个 Key 存储在哪个 TiKV 节点);
- 对TiKV 集群进行调度和负载均衡(如数据迁移、Raft group leader 迁移等);
- 分配全局唯一且递增的事务 ID;
TiKV Server
TiKV Server 负责存储数据,从外部看 TiKV 是一个分布式的提供事务的 Key-Value 存储引擎。存储数据的基本单位是 Region,每个 Region 负责存储一个 Key Range 的数据,每个 TiKV 节点会负责多个 Region 。TiKV 使用 Raft 协议做复制,保持数据的一致性和容灾。副本以 Region 为单位进行管理,不同节点上的多个 Region 构成一个 Raft Group,互为副本。数据在多个 TiKV 之间的负载均衡由 PD 调度,以 Region 为单位进行调度。
参考:TiDB 简介
TiDB在易建
RSS 系统的架构如下:
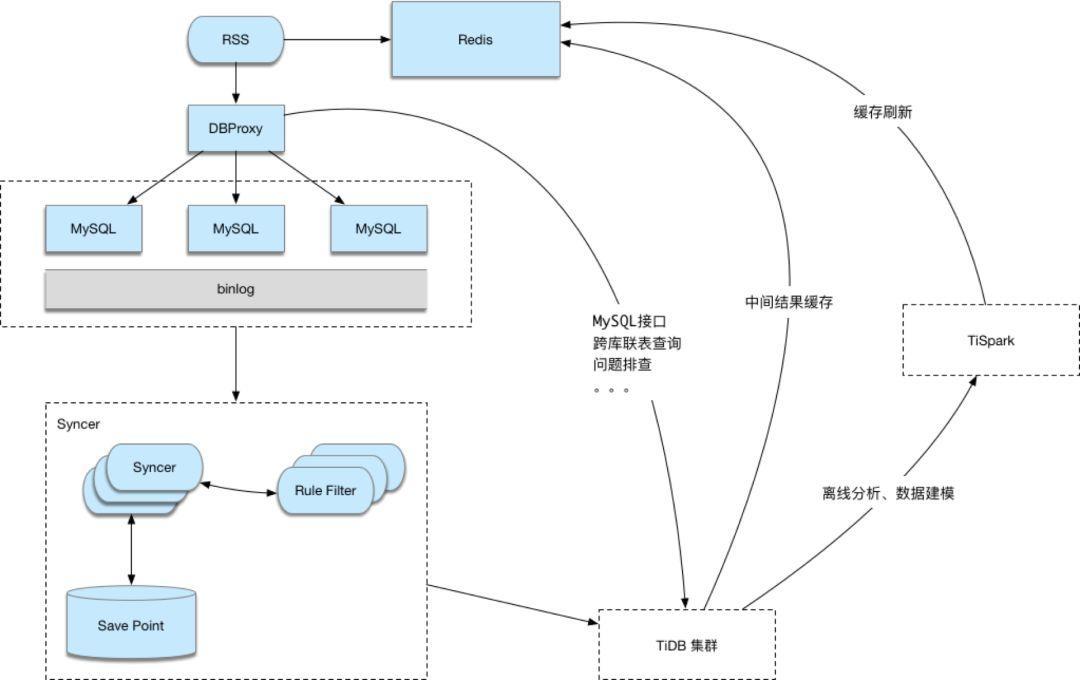
RSS 系统的架构图
我们的 TiDB 集群共有 5 台高性能的海航云服务器来提供服务,经过测试 write 性能可以稳定的做到 1 万 TPS,同时,read 性能可以做到 0.5 万 TPS,后续升级到 SSD 硬盘将能够提高更高的读写性能。使用了 TiDB 后,我们不需要再考虑分表分库的问题,因为数据在一起,也不用考虑数据同步的问题。近 10 亿行数据都可以复用以前的 MySQL 代码,进行 OLAP 分析也比上一代收益系统提速近 20 倍,同时,免去了数据同步的可能存在的问题。而且也能很好的满足我们 OLTP 操作的需求,懂得 MySQL 的开发人员都可以轻松的进行大数据开发,没有学习门槛,既节省了开发成本,又降低了数据运维成本。
后记
部署 TiDB 近 3 个月来,收益系统的数据量已经增长近 1 倍达到 5 亿的数据量,近 10 张千万级别的中间表数据,期间我们做过 TiDB 的扩容与版本升级,这些操作对业务来讲都是完全透明的,而且扩容与升级简单。我们可以更加专注业务程序的开发与优化,无需了解数据库分片的规则,对于快速变化的业务来说是非常重要的。同时,由于 TiSpark 的整合可以再同一个集群里面分析海量的数据并将结果无缝共享,对于核心业务的应用的开发来讲是非常方便的,由于能够快速响应业务的需求对于当前激烈竞争的航空业来说,提升了航空公司自身的核心竞争力。