
执行了两遍,报了不同的节点的相同错误
reload 的时候会滚动重启 TiKV 节点,在关闭 TiKV 节点时会先将这个节点上的 leader 迁移到别的 节点上,等所有 leader 迁移走后,然后关闭这个节点,减少 TiKV 节点重启的影响。
reload 的时候等待 TiKV 将所有 leader 迁移走,这个默认的超时时间是 5 分钟,可以调整一下超时时间 --tansafer-timeout 选项,再试下
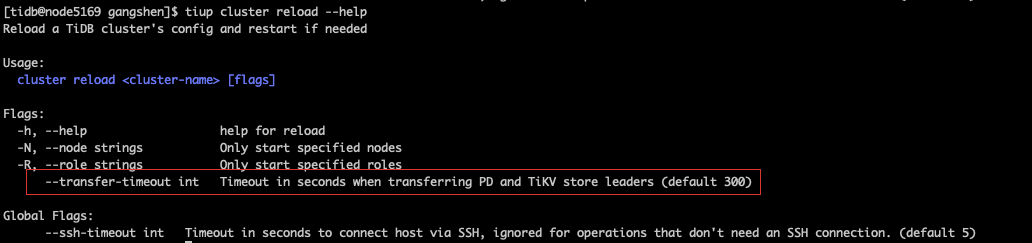
如果还是有无法迁移走所有的 leader 节点。麻烦提供一下 pd-ctl 执行 store 命令的输出结果,可以排查下 leader 无法迁移的问题。

- 调整一下超时时间 --tansafer-timeout 选项有进行尝试么,结果是怎么样的
- 输出结果过长,麻烦将输出的结果重定向到文本中,通过文本方式上传一下,提供部分信息的话,不太好排查问题

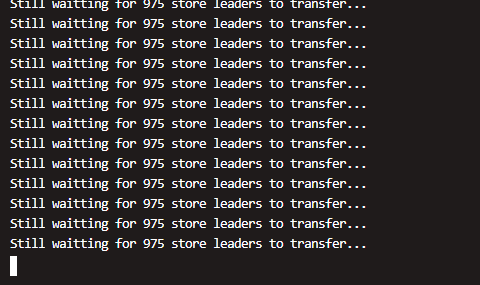
这个能回退到ansible 嘛,着急,有其他操作要做
通过 import 导入到 tiup 的 ansible 是被归档了
可以通过 find / -name inventory.ini 命令查找一下 ansible 归档路径
就是可以用ansible 吧
建议不要 tiup 和 ansible 方式混用,会导致不可以预知的风险。
方便的话,麻烦上传一下 pd leader 节点的日志,看下是否是因为迁移 leader 的过程中是否有调度失败的情况
那就把tiup删除了,可以嘛

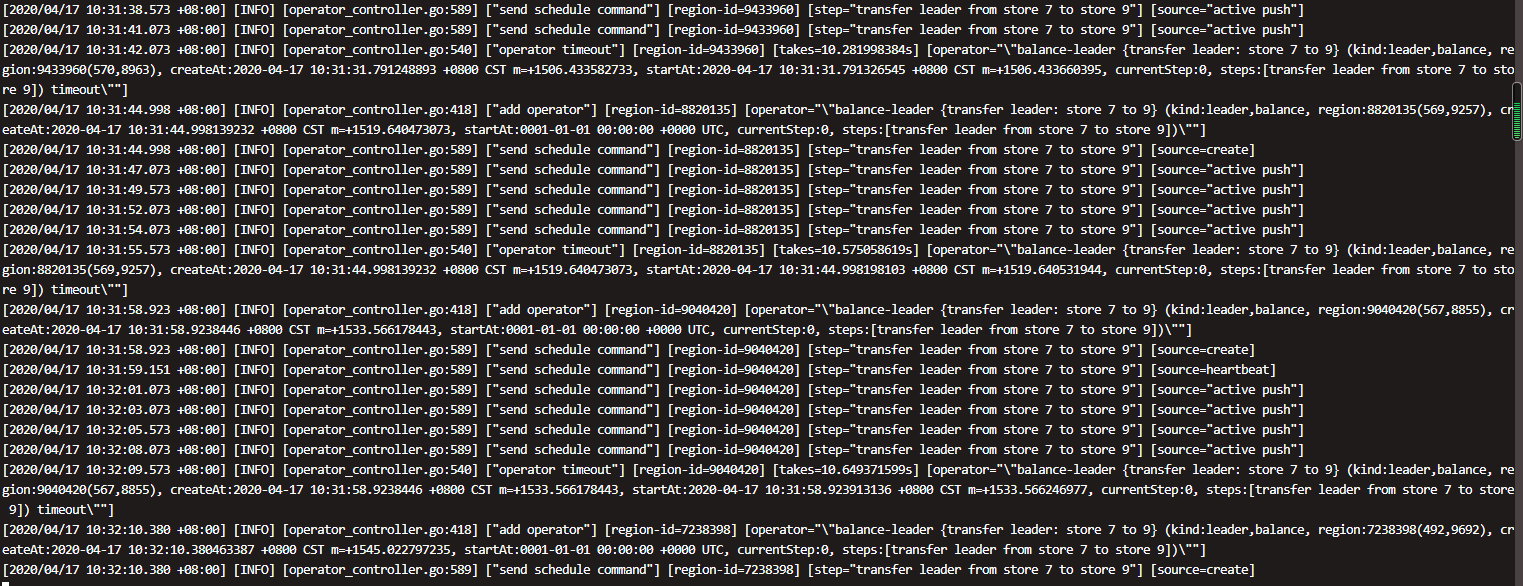
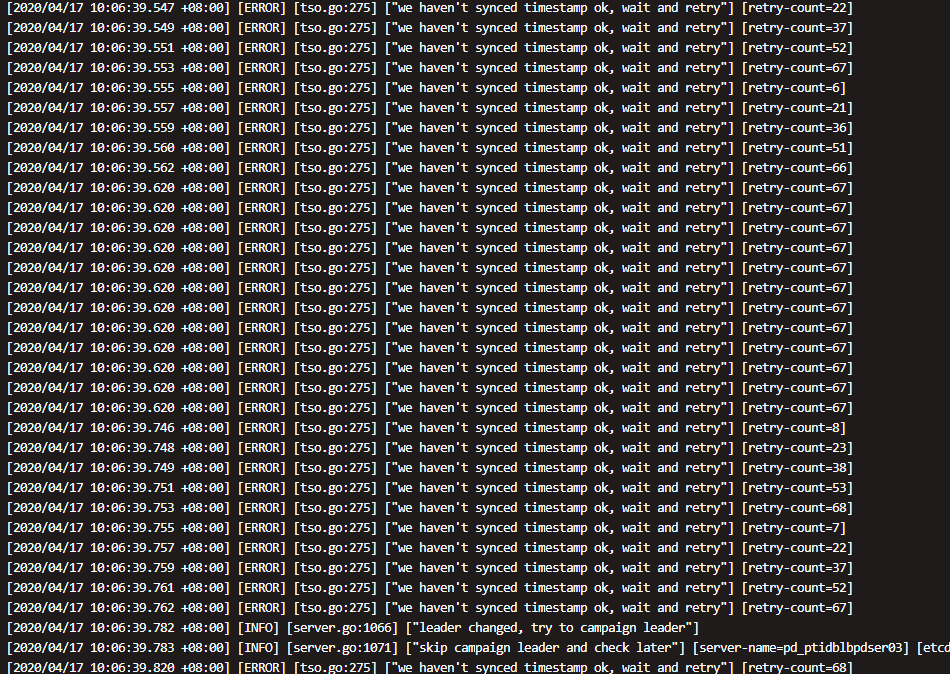

你好,我只是导入了tiup,没有升级下面的版本,因为我们本来就是这个版本,应该可以用ansible 吧
将集群升级到 v4.0.0-rc 版本
tiup cluster upgrade v4.0.0-rc
跑 reload 是因为修改了配置 要重起生效吗?
reload 重启前会先 trasfer kv 的leader, 后面我们会提供选项或略超时或者默认或略
目前如果要 重启可以 直接 restart 集群,因为前面跑 reload 配置已经更新到对应机器了, 但 restart 不会做 transfer leader.
如果只是要 缩容 一个 kv 应该用 scale-in