tidb版本 : 用tiup部署的3.0.12
TiDB Cluster: tidb-test
TiDB Version: v3.0.12
ID Role Host Ports Status Data Dir Deploy Dir
-- ---- ---- ----- ------ -------- ----------
10.3.87.221:9093 alertmanager 10.3.87.221 9093/9094 Up /tidb/app/data/alertmanager-9093 /tidb/app/deploy/alertmanager-9093
10.3.87.221:3000 grafana 10.3.87.221 3000 Up - /tidb/app/deploy/grafana-3000
10.3.87.202:2379 pd 10.3.87.202 2379/2380 Healthy /tidb/app/data/pd-2379 /tidb/app/deploy/pd-2379
10.3.87.221:2379 pd 10.3.87.221 2379/2380 Healthy|L /tidb/app/data/pd-2379 /tidb/app/deploy/pd-2379
10.3.87.34:2389 pd 10.3.87.34 2389/2381 Healthy /tidb/app/data/pd-2389 /tidb/app/deploy/pd-2389
10.3.87.221:9090 prometheus 10.3.87.221 9090 Up /tidb/app/data/prometheus-9090 /tidb/app/deploy/prometheus-9090
10.3.87.202:4000 tidb 10.3.87.202 4000/10080 Up - /tidb/app/deploy/tidb-4000
10.3.87.221:4000 tidb 10.3.87.221 4000/10080 Up - /tidb/app/deploy/tidb-4000
10.3.87.34:4000 tidb 10.3.87.34 4000/10080 Up - /tidb/app/deploy/tidb-4000
10.3.87.202:20160 tikv 10.3.87.202 20160/20180 Up /tidb/app/data/tikv-20160 /tidb/app/deploy/tikv-20160
10.3.87.221:20160 tikv 10.3.87.221 20160/20180 Up /tidb/app/data/tikv-20160 /tidb/app/deploy/tikv-20160
10.3.87.34:20160 tikv 10.3.87.34 20160/20180 Up /tidb/app/data/tikv-20160 /tidb/app/deploy/tikv-20160
我看了一下prometheus的配制文件确实是去抓了三个节点的数据
- job_name: pd
honor_labels: true
scrape_interval: 15s
scrape_timeout: 10s
metrics_path: /metrics
scheme: http
static_configs:
- targets:
- 10.3.87.221:2379
- 10.3.87.202:2379
- 10.3.87.34:2389
但得到的数据是
| pd_cluster_status{instance=“10.3.87.221:2379”,job=“pd”,namespace=“global”,type=“leader_count”} | 79 |
|---|---|
| pd_cluster_status{instance=“10.3.87.221:2379”,job=“pd”,namespace=“global”,type=“region_count”} | 237 |
| pd_cluster_status{instance=“10.3.87.221:2379”,job=“pd”,namespace=“global”,type=“storage_capacity”} | 263819968512 |
| pd_cluster_status{instance=“10.3.87.221:2379”,job=“pd”,namespace=“global”,type=“storage_size”} | 325384432 |
| pd_cluster_status{instance=“10.3.87.221:2379”,job=“pd”,namespace=“global”,type=“store_disconnected_count”} | 0 |
| pd_cluster_status{instance=“10.3.87.221:2379”,job=“pd”,namespace=“global”,type=“store_down_count”} | 0 |
| pd_cluster_status{instance=“10.3.87.221:2379”,job=“pd”,namespace=“global”,type=“store_low_space_count”} | 0 |
| pd_cluster_status{instance=“10.3.87.221:2379”,job=“pd”,namespace=“global”,type=“store_offline_count”} | 0 |
| pd_cluster_status{instance=“10.3.87.221:2379”,job=“pd”,namespace=“global”,type=“store_tombstone_count”} | 0 |
| pd_cluster_status{instance=“10.3.87.221:2379”,job=“pd”,namespace=“global”,type=“store_unhealth_count”} | 0 |
| pd_cluster_status{instance=“10.3.87.221:2379”,job=“pd”,namespace=“global”,type=“store_up_count”} |
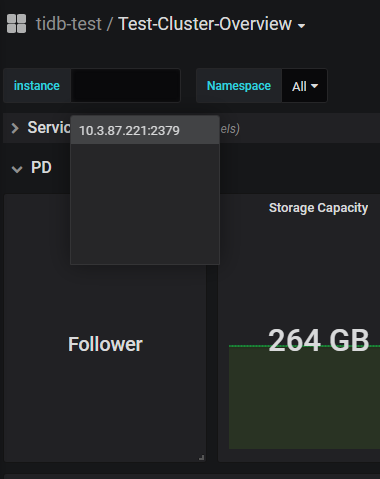

而且我还发现同一个实例但在两个面板上显示的角色不一样
一个是leader 一个是follower