为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】:v3.0.11 DM v1.0.3
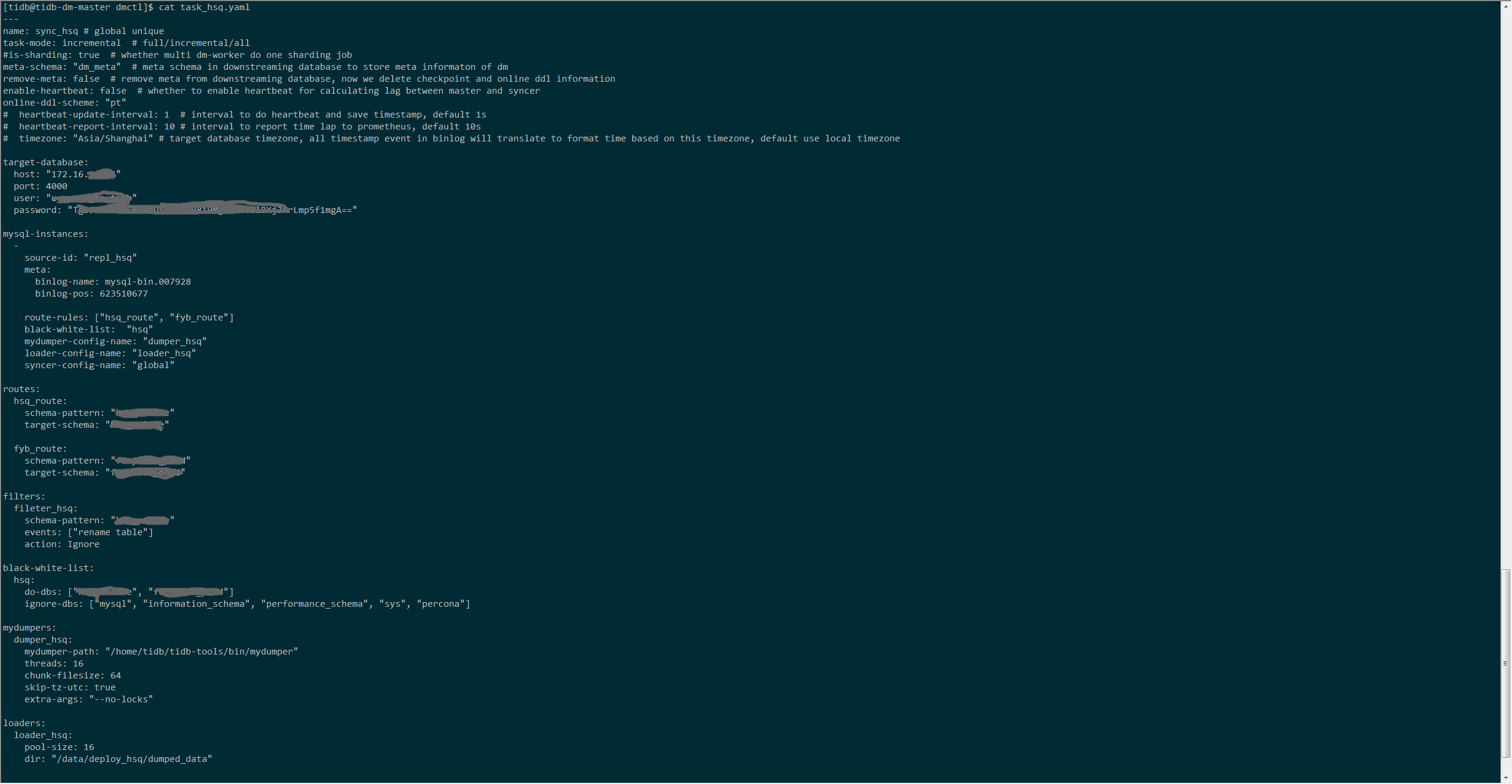
- 【问题描述】:
dm同步报如下错误:
dm-worker日志如下:

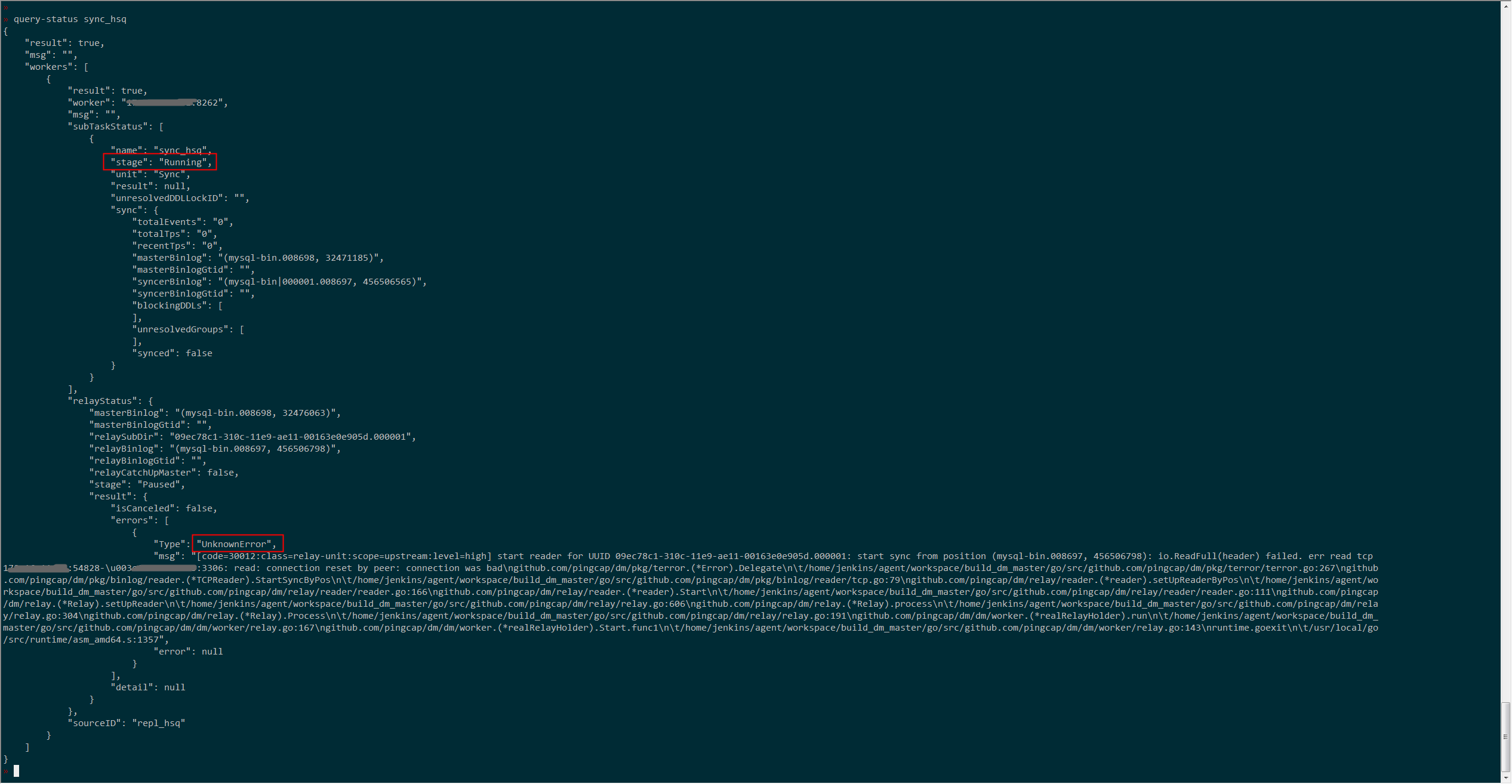
然后我使用stop-task / start-task 重启任务,错误依旧存在,看状态是running,实际已经停止
为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
dm同步报如下错误:
dm-worker日志如下:
然后我使用stop-task / start-task 重启任务,错误依旧存在,看状态是running,实际已经停止
我之前遇到过,应该是网络的问题
报错显示的是链接被重置:
1、请检查上游 MySQL 和下游 DM-Worker 的网络联通性,如通过 telnet 命令进行验证
2、请检查上下游 MySQL 和 DM 服务器直接是否有网络安全策略,存在链接回收的设置。
3、请检查其他链接超时回收的设置
4、请尝试重启 DM-Worker 后,尝试启动 task ,再观察下
重启dm-worker后,现在relay log已经开始继续写入了,但是同步任务还是启动不了,错误就是上面截图所示
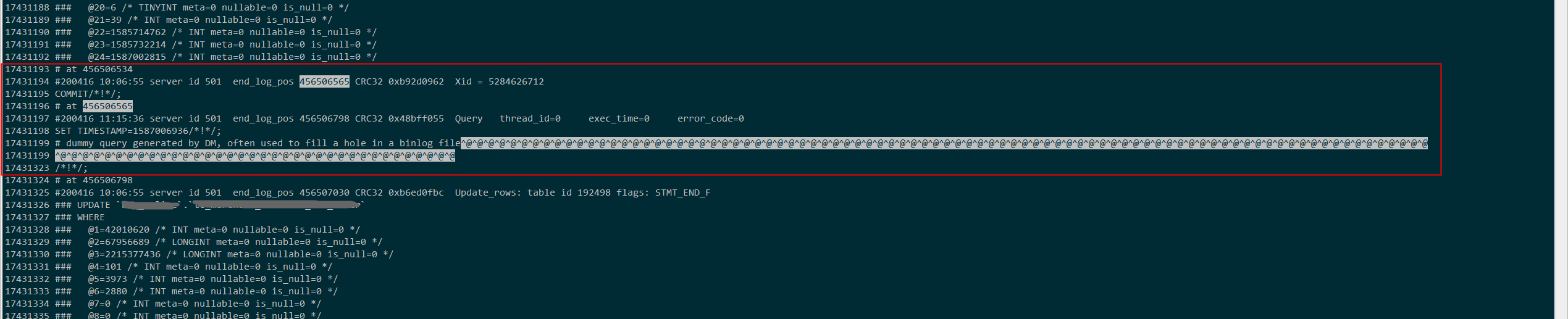
请使用 mysqlbinlog -vv 解析下下述的 relaylog 看下是否有异常发生:
![]()
对比了下源mysql binlog,中间没有漏掉信息,直接跳过了,现在已经恢复了
![]() ,请帮忙反馈下,这个环境的 relaylog 的 meta 文件是否手动的编辑修改过?
,请帮忙反馈下,这个环境的 relaylog 的 meta 文件是否手动的编辑修改过?
下次出现相应的报错,可以尝试下述步骤,避免数据丢失:
建议重新从上游拉取报错位置的 binlog 文件,并重新开始同步,参考步骤如下:
1)停止 task
2)停止 dm-worker
3)修改 relay-meta 文件为报错的 binlog 的内容,比如:报错时有 binlog-name = "mysql-bin.004451" 与 binlog-pos = 2453 ,则将其分别更新为 binlog-name = "mysql-bin.004452" 和 binlog-pos = 4 ,同时更新 GTID 的信息比如对应位点的 GTID 为 binlog-gtid = "f0e914ef-54cf-11e7-813d-6c92bf2fa791:1-138218058" 。
4)重启 dm-worker
5)将下游 dm_meta 数据库中 global checkpoint 与每个 table 的 checkpoint 中的 binlog_name 更新为出错的 binlog 文件,将 binlog_pos 更新为已同步过的一个合法的 position 值,比如 4。
6)修改 task 的 safe-mode 为 true,并启动 task
7)观察同步状态,报错的 binlog 同步完成后,可以修改 task 的 safe-mode 为 false,然后继续同步
relay log下的meta文件没有人为修改
好的,谢谢!
![]()