作者:郝海民,许超。本文系 2019 年 11 月北京 TUG 线下活动“高可用架构设计与实践”分享实录。
VIPKID 是全球增长速度最快的在线青少儿英语教育品牌,公司主要采用阿里云+ AWS 的双云架构,从 MySQL 数据库集群和跨云等方面都做到了高可用。随着 VIPKID 业务数据量的暴增, MySQL 自身单机瓶颈的问题逐渐暴露,已无法继续承载服务。于是 VIPKID 经过存储选型引入了 TiDB。本文主要介绍 VIPKID 的高可用架构设计与 TiDB 实践经验。
VIPKID 双云架构
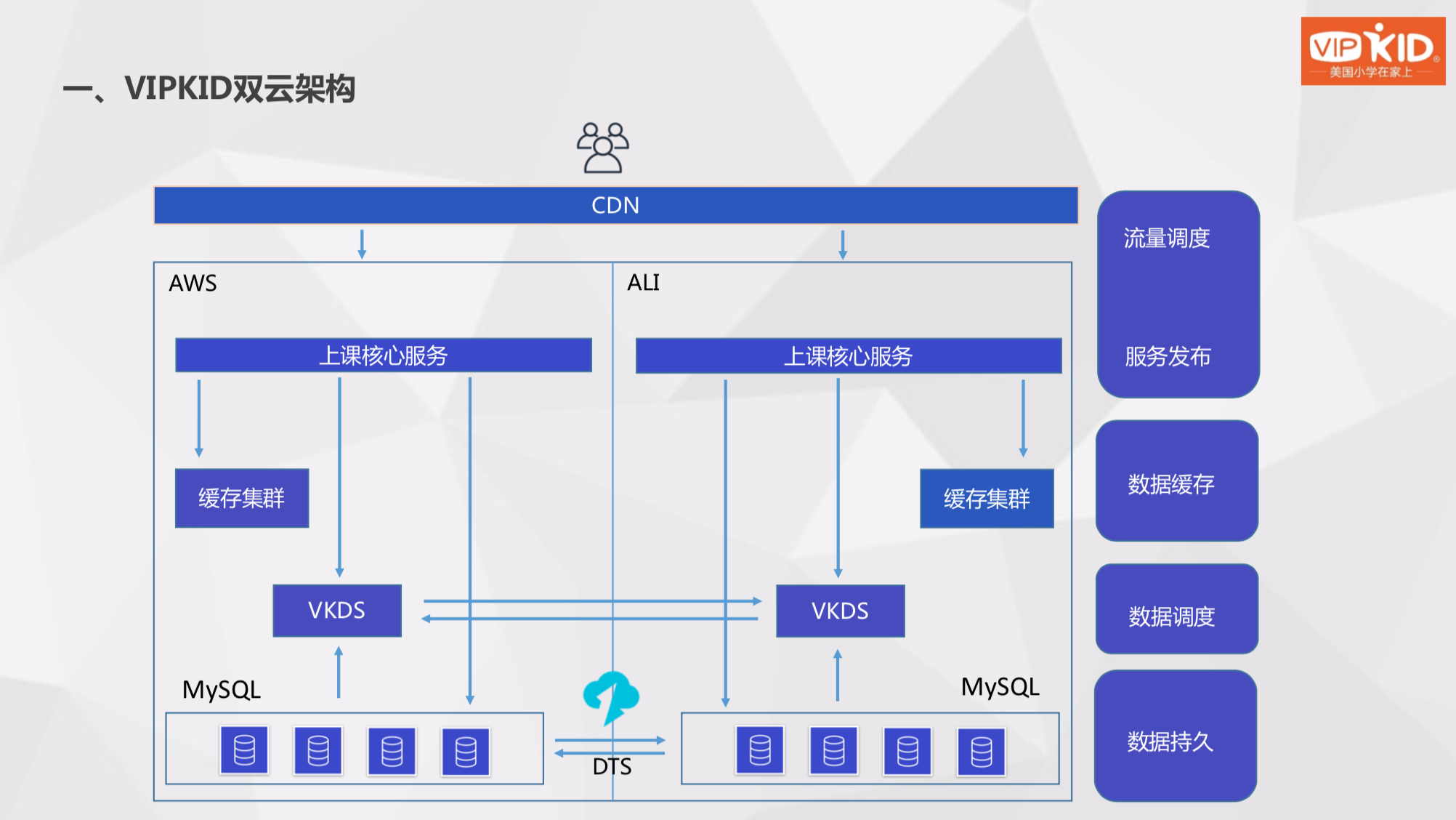
首先来看一下我们的架构简化图。我们在两个云上都部署了上课核心服务,下面是我们的缓存集群,最下面是我们的数据库持久层 - MySQL 集群,MySQL 用 DTS 做了双向同步。中间层是我们自研的 VKDS 中间件,来实现高可用的一些基本功能。
MySQL 集群高可用
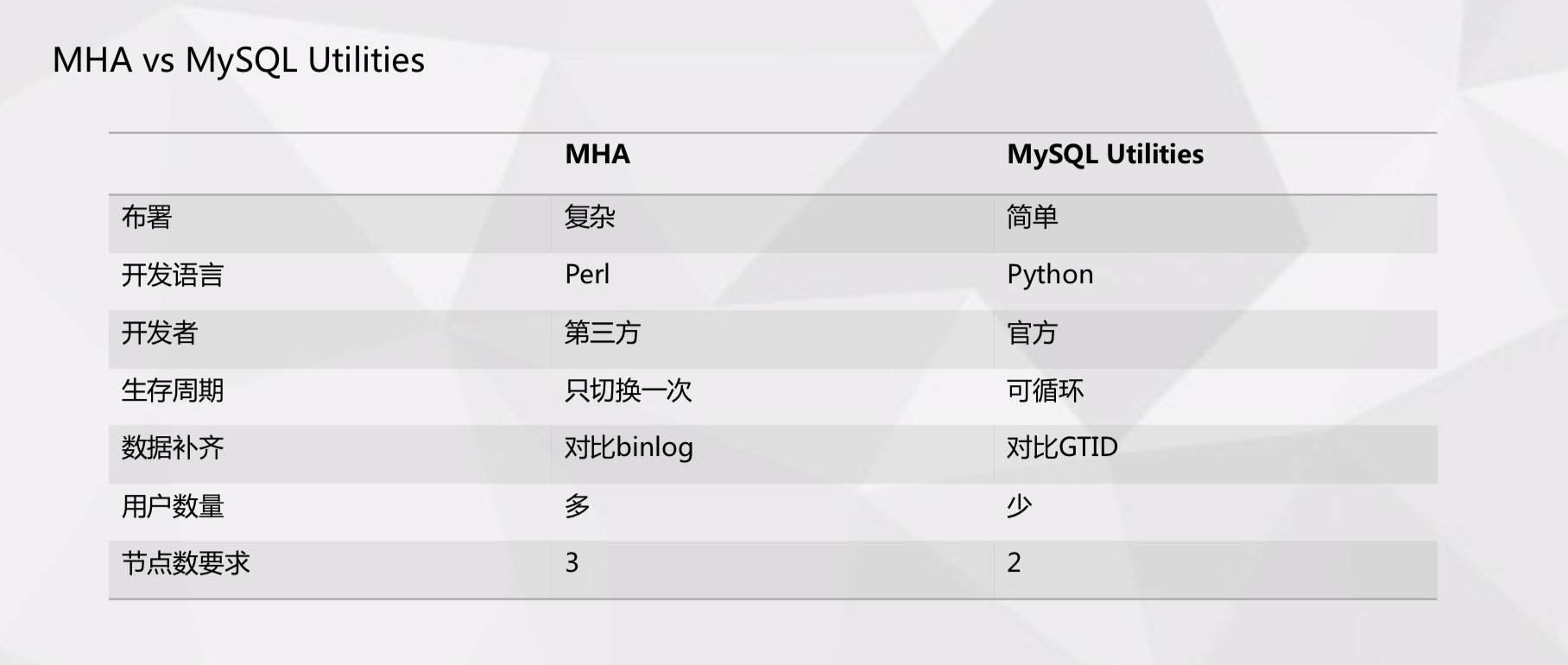
架构高可用,首先要实现集群高可用。 MySQL 推出 MHA 也很长时间了,但我们基于一些考虑,目前核心业务用的还是传统的主从架构。我们选用 MySQL Utilities 的高可用方案,MySQL Utilities 是官方提供的 MySQL管理工具。这里我们来看一下 MHA 和 MySQL Utilities 的一个简单对比:
- 首先在部署上面,MHA 比较复杂,需要客户端、服务端配合;MySQL Utilities 相对比较简单,只需要在中控机上安装,就可以完整切换;
- 在开发语言层面,MHA 使用 Perl,而 MySQL Utilities 是 Python。Python 是 VIPKID 开发人员必备的技能,可以直接使用 Python 去改变 MySQL Utilities 里的一些功能,进行自定义,操作相对也比较简单;
- 从开发者来看,MHA 是第三方开发,MySQL Utilities 是官方开发;
- 从生命周期来看,MHA 只切换一次,但 MySQL Utilities 可以切换多次。例如一主三从架构,如果主库发生故障,可以切换到从库,并且只要还有可用的从库,就能在故障时循环切换;
- 从最核心的数据补齐来看,MHA 靠数据互信打通比对差异 Binlog,来实现数据补齐。MySQL Utilities 依托 GTID 的原理,来实现差异数据补齐。当备主数据落后于其他节点时,首先要切换到其他节点上把数据补齐,然后才会将其提升为主库,而其他的从库需要切换到这个备主后才能完成释放流程;
- 从用户数量看,已经有很多公司在使用 MHA,但 MySQL Utilities 使用的公司还比较少;
- 从节点要求看,MHA 至少需要 3 个节点,MySQL Utilities 只需要 2 个节点。
我们选择 MySQL Utilities 的另一个重要原因是 MHA 需要通过 VIP 切换,可能会造成数据不一致的问题。
我们现在线上生产环境是官方 MySQL 5.7 版本。我们使用的 MySQL Utilities 版本在 5.6 以上,这样才支持 GTID。对于我们来说 GTID 是必选项,“master_info_repository = TABLE, relay_log_info_repository = TABLE” 这两个参数也是我们线上规范安装的标配。但 report_host 和report _port 这两个变量不是必须的,只是需要靠这两个变量去发现下面的从库。
如果不使用这两个参数,也可以手动完成主从节点切换。MHA 需要通过互信打通来读取样本,但 MySQL Utilities 只需要一个有权限的账号就可以完成切换。同时我们建议开启半同步,或者增强半同步,把握主动权。最后,为了保证数据完整性,我们建议将 GTID 的完整性和主从数据一致性列为日常健康巡检的一部分。
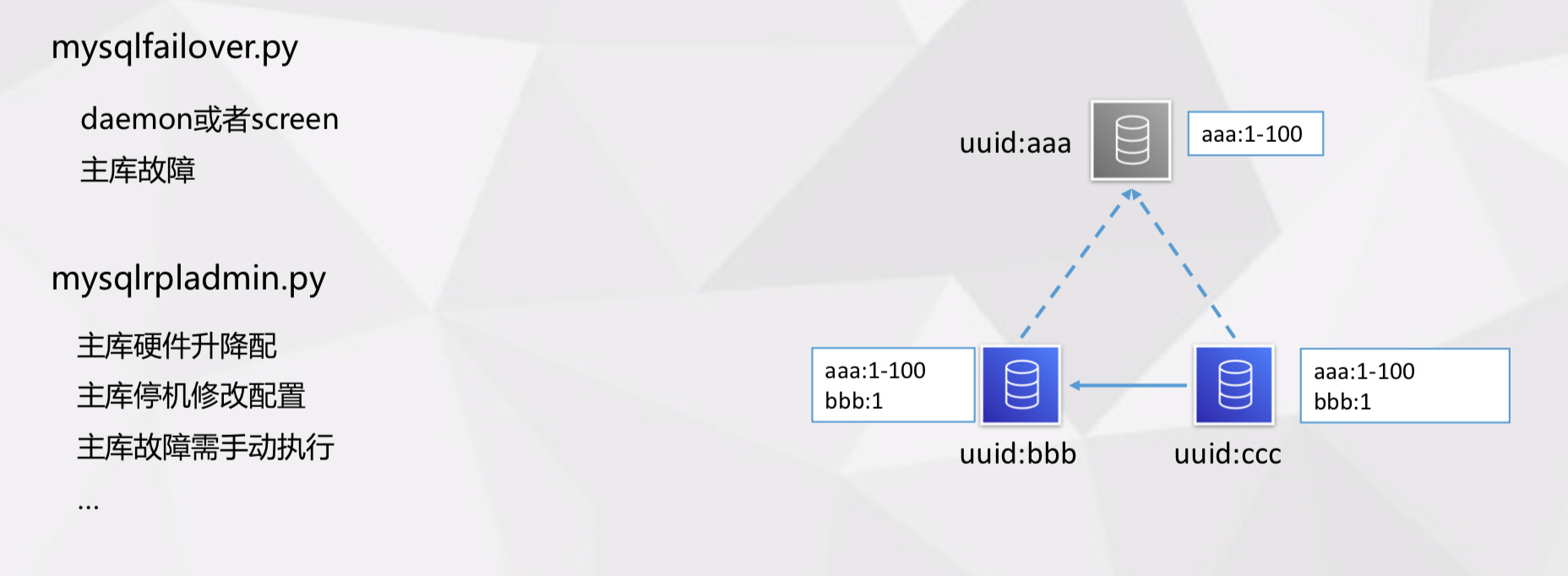
MySQL Utilities 有很多工具,但我们高可用只用到了两个脚本:
- mysqlfailover.py,主要用于主库故障自动 failover,但在网络不稳定的场景中,我们很难评估是真的故障还是网络不稳定,就需要人为干预。
- mysqlrpladmin.py,可以手动 failover,例如主库硬件优化时或主库停机修改静态配置时就需要用这到这个功能。
MySQL Utilities 还提供了两个参数给用户进行自定义操作,分别用于切换前、切换后调用,可以生产脚本实现主从差异化配置。
切换完后还需要和其他平台对接,例如上线平台、备份平台,还需要和生产、数据查询平台进行元信息同步等对接。
VKDS 中间件
目前我们有一个从库用来做备份和线上订正,但在降本增效的考量下我们需要在这个从库上也跑业务流量,就需要将这个从库修改为动态的。
传统的数据应用如果主库发生故障需要切换到从库,切换完后应用需要发布新配置,会延迟故障恢复的时长。但这是业务侧没法接受的,所以我们自研了 VKDS 中间件来解决这个问题。
虽然是中间件,但是它并不承载流量的转发,所以它非常轻量,只是数据库的备组。客户端会定期跟服务端订阅配置信息,服务端任何一个数据变更,比如连接池、数据库名、数据库用户密码修改都会在服务端版本 + 1。客户端感知到版本更新,就会拉到本地重新创建连接池,整个过程不需要重启应用。研发不需要进行版本操作,只需关注应用是否正常恢复,报错日志有没有持续发生就可以。VKDS 还具备一些其他功能,例如权重调配、运维时间监控等。
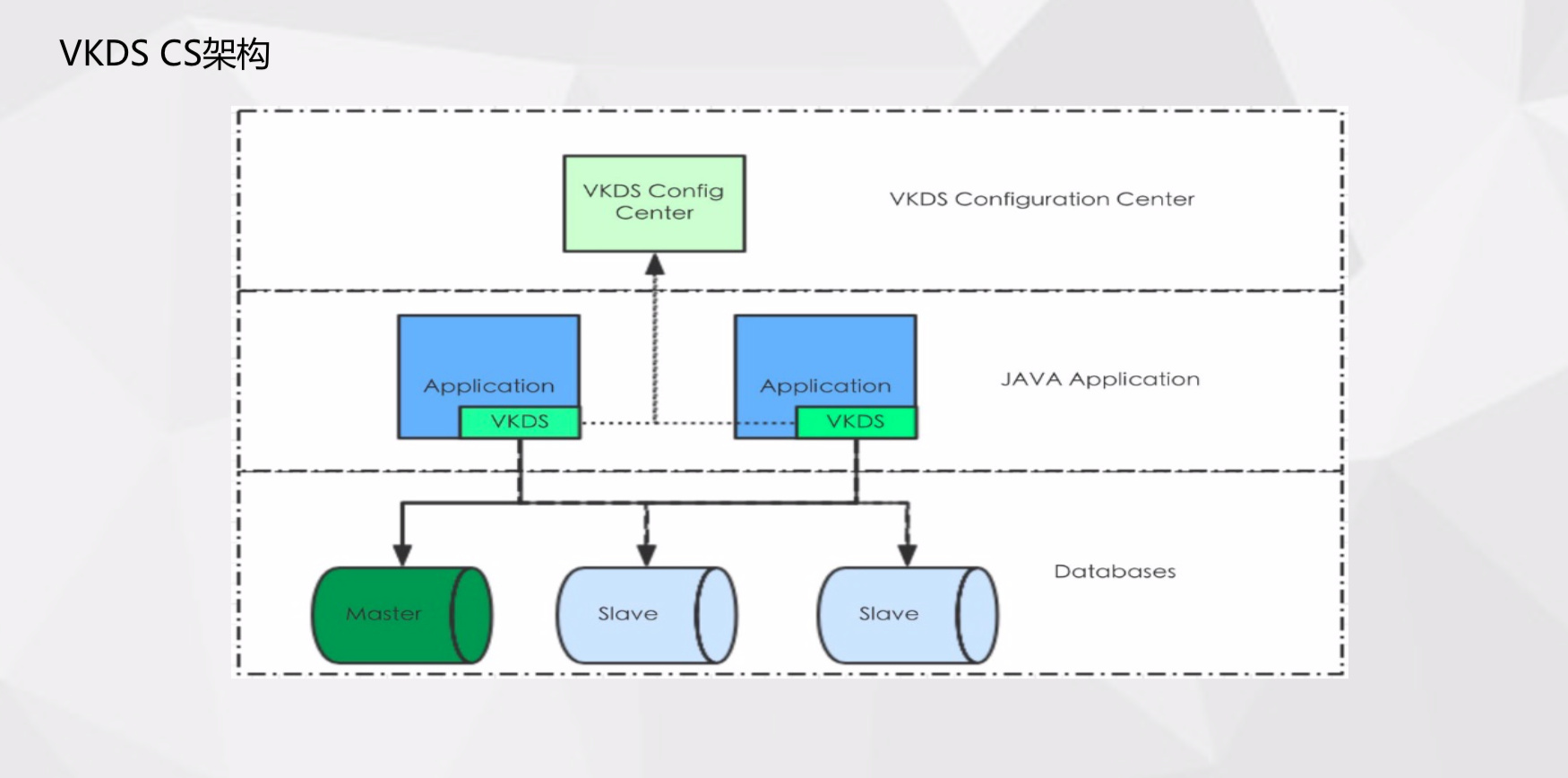

随着业务增长我们也有了分片部署的需求,这个需求 VKDS 也是支持的。我们目前一个数据源对应一个库,多个分片需要创建多个数据源,应用通过使用多数据源来满足分片的需求。

跨云高可用
每次线上故障都会造成大量损失,我们的业务场景对高可用有着非常强烈的要求。我们现在使用双云架构:阿里云负责写,AWS 负责读。平常的流量调配是阿里云 95%,AWS 5%,其他 5% 的写流量需要通过跨云写到阿里云中,这 5% 的流量也可以去验证 AWS 是否运行正常。
我们计划是两个云定期对调,比如 AWS 变成可写,阿里云变成只读。我们的这个架构对于云灰度、新版本上线、压测都是支持的,VKDS 也做了双份在云和云之间进行数据同步,最底层我们用 DTS 做了双向同步。
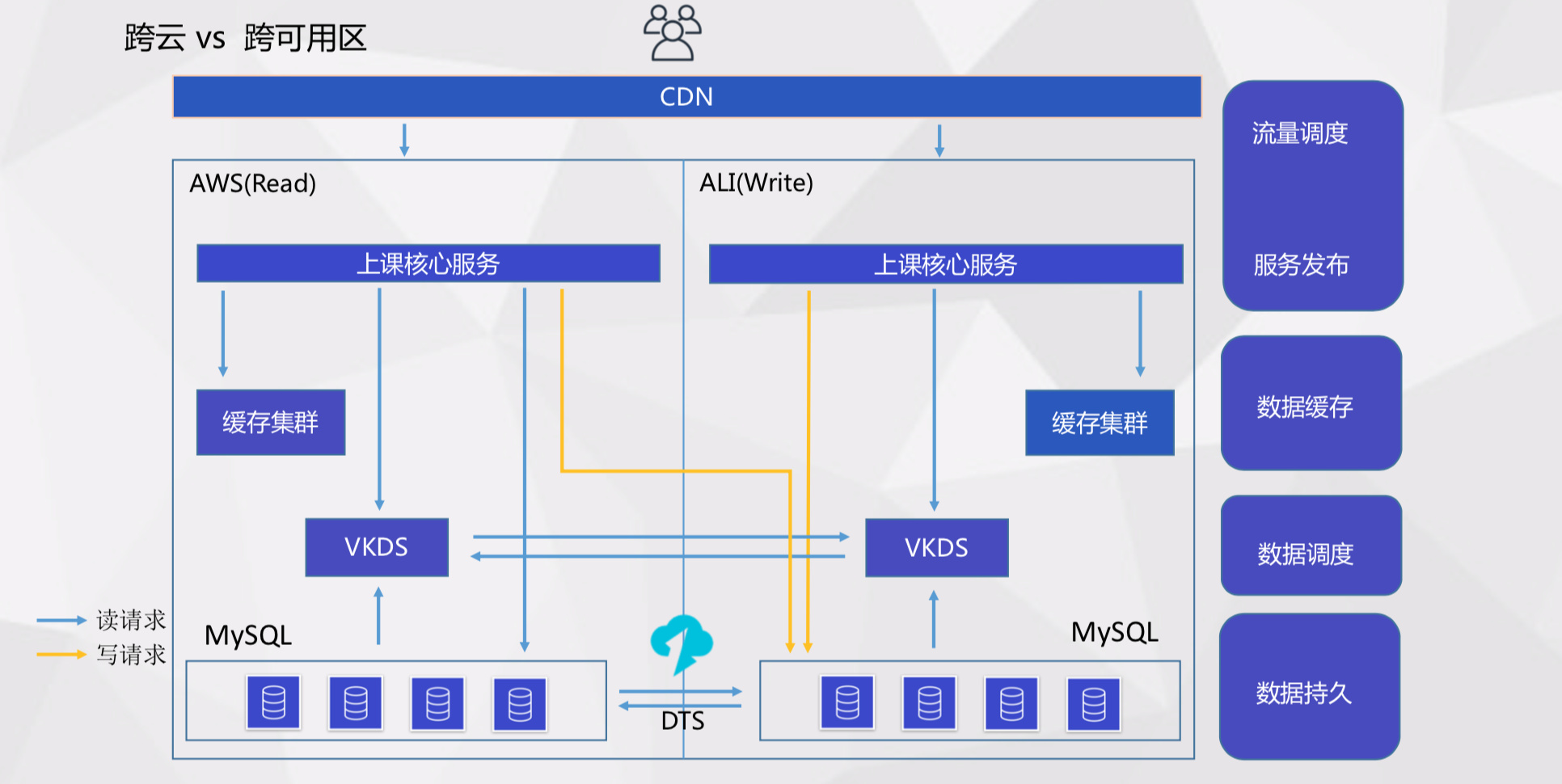
我们目前能承受的风险就是备云不可读。当 AWS 不可读时,我们可以把其上 50% 的流量全部调到阿里云;如果阿里云不可读也不可写,我们可以把所有流量调到 AWS。我们的核心服务支持降级,数据只要能读到就不会发生客损,DTS 短时的故障不会影响到我们的线上业务。如果其他组件出现故障,我们也可以快速切换到另外一个云。
虽然我们目前实现了双云架构,但依然还有一些问题需要优化:
- 缓存层无法同步。MySQL 支持双向同步,但缓存层不行,如果切换完以后,缓存就会击穿到我们的持久层,甚至会把下层的数据库压跨;
- 需要做到自动切换。现在不论是流量调配还是后端数据库切云操作,还需要人为判断和操作。未来,我们要进行智能切换,尽量避免人工操作。
- 最终目标是实现多活。不论是应用改造,还是通过 MHA 去实现,都是一个新的挑战。
TiDB 在 VIPKID 的应用和实践
TiDB 在 VIPKID 的使用情况
首先我们来看一下 TiDB 在 VIPKID 的使用情况。由于 TiKV 支持多副本,也支持高可用,我们就选择了阿里云的 ecs.i2g.2xlarg,本地高 I/O 盘。TiDB Server 和 PD 对磁盘性能要求不算太高,我们就直接用了普通的 r5.2xlarge。我们标准化集群就是 3 个存储节点(TiKV Server)和 3 个计算节点 (TiDB Server + PD Server)。VIPKID 现在一共有 5 套 TiDB 集群,集群最大数据量达 40 亿以上,单表是 2.5 亿,最大 QPS 平均 2.3 万左右,主要用于写入,另外还有 2 套单独的 DM 集群。

这是 VIPKID 的数据库架构简图 。左上角是抽象的 MySQL 线上集群,包括很多 DB/实例,其中有一些是分库分表的集群。具体到 BI 这块,在最开始时实时计算类似的场景我们是通过 MySQL 进行临时实现的,数据同步这块用的 Otter。但随着数据量暴增, MySQL 自身单机瓶颈的问题逐渐暴露,已无法继续承载服务。又经过了一次次业务调优和 SQL 调优,MySQL 还是无法继续再满足业务需求,于是我们进行了新的存储选型,进而引入了 TiDB。
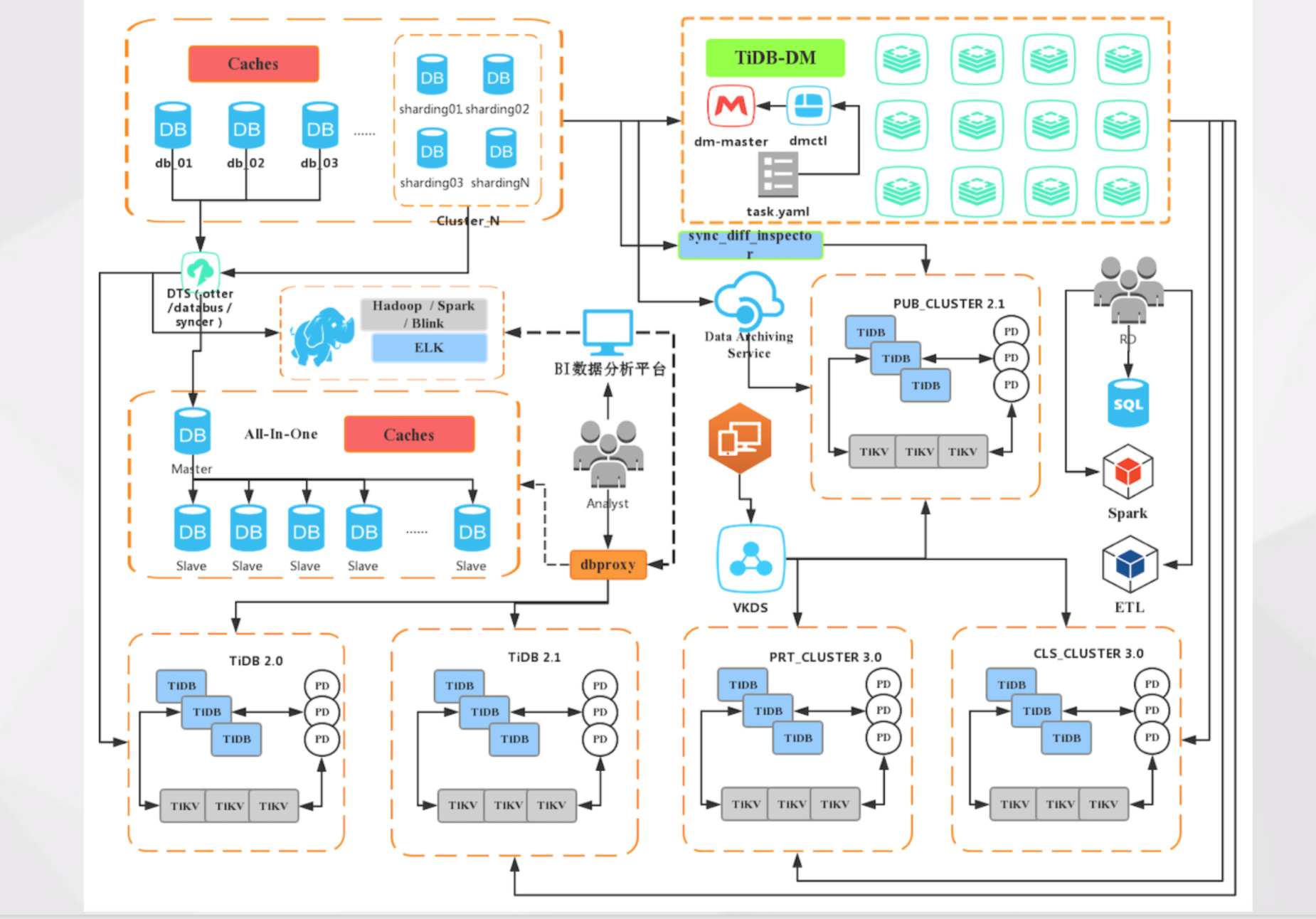
TiDB 在 VIPKID 的使用场景
引入 TiDB 解决了我们的哪些问题?在回答这个问题之前我们先来简单看一下 TiDB 架构图。
TiDB 主要有 3 个组件:
● 底层分布式存储 TiKV;
● 无状态计算节点 TiDB (可以进行 SQL 解析、优化等工作);
● 还有一个负责整体集群调度管理的 PD。
除此之外,TiDB 还对 OLAP 业务提供了 TiSpark 这个大数据计算组件。
TiDB 有以下几个优势:
- 首先,高度兼容 MySQL,线上业务可以进行平滑迁移,不需要进行过多改动;并且,可以沿用很多 MySQL 的开源或公司自研工具;
- 其次,它自身支持高可用,并且可以做到强一致;
- 最后,它可以支持水平扩展,计算和 I/O 能力瓶颈时可以通过增加节点来增加集群的负载能力。
在VIPKID,我们主要将 TiDB 应用在三个场景中:
- 数据归档/冷热数据分离。归档这块我们之前尝试过很多方式,遇到的最大问题就是线上表和历史归档表之间的融合,比如线上表增加或删减字段,历史表也都需要做对应操作,成本很高。但是 TiDB 可以解决这个问题,它通过实现了 F1 的在线异步 schema 变更算法,避免了历史表的 rebuild 操作,变更表结构,不影响之前的数据,加减字段成本很低。
- 线上复杂查询。众所周知,MySQL 在数据量达到一定程度后就会出现单机瓶颈的问题。并且,默认的 InnoDB 存储引擎也并不适合 AP 业务。对于以上两点,TiDB 根据自身特性做了很多优化:一方面, TiDB 中数据可以均匀分布在多个存储节点;另一方面,TiDB 支持 Join 和聚合算子的并行优化。
- 分库分表聚合。MySQL 面对大数据量大并发场景的常规玩法很统一,就是进行分库分表。但是对应的会加大维护难度、业务复杂度以及下游业务的查询难度。所以我们对于一些在线或离线的业务通过 DM 进行分库分表合并,再放到 TiDB 里,就可以支持一些多维度复杂查询,并且很多下游的统计逻辑也不需要变更。
下图展示了 DM 的整体架构,首先是 DM Worker,其拉取对应 MySQL 的 Binlog,并且进行解析然后消费到下游 TiDB 集群。DM Master 负责管理集群,同时也负责管理 Sharding DDL,可以通过 dmctl 工具与其进行交互。比如可以通过 dmctl 向 DM Master 发送一个 task,DM Master 解析调用后,把相应任务发给对应的 DM Worker,DM Worker 再将任务拆成多个子任务。
dm-worker 的子任务/处理单元:
DM Worker 进行数据同步的处理单元有 relay log、dump、load 和 sync。
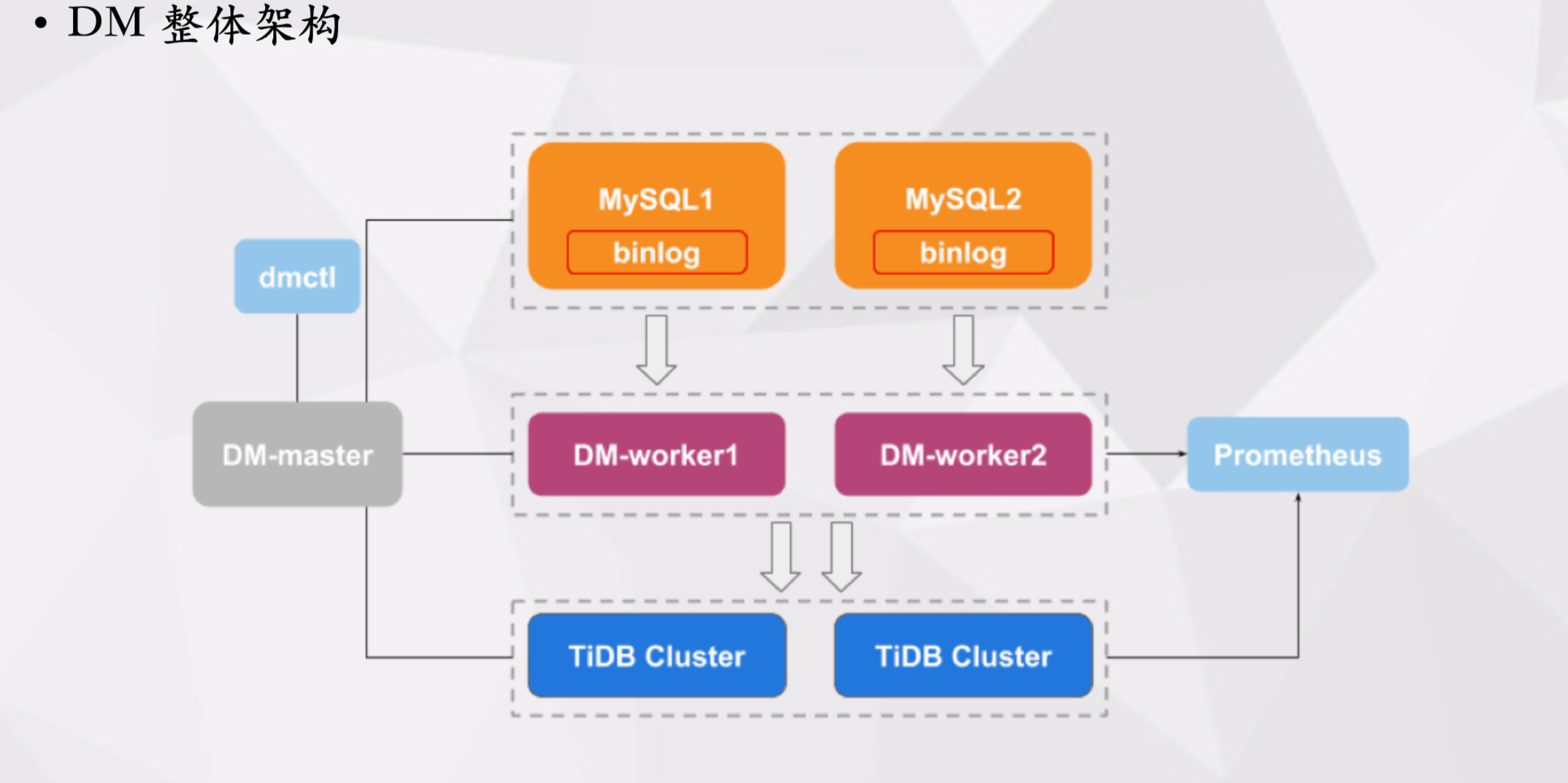
DM 使用经验
简单分享一下我们的分库分表合并的实践。下面是一个完整分库分表合并任务的配置文件:
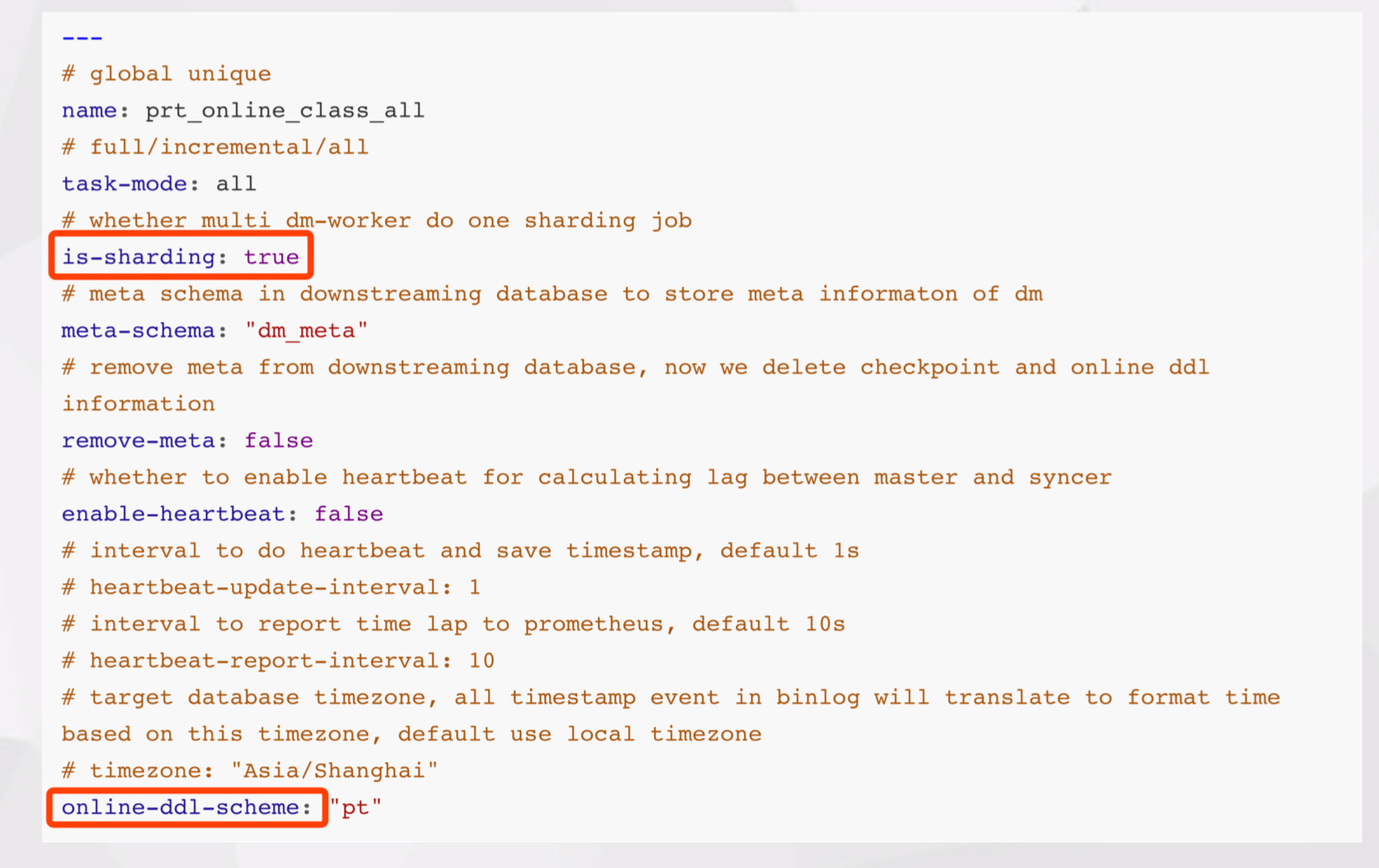
- 最开始是全局配置,其中 name 部分是全局唯一的。但这个全局唯一并不是说在 DM 整个集群里全局唯一,它只是判断在同一个 DM Worker 里是不是唯一。如果分库分表,需要把 is-sharding 打开。还有 online-ddl-schema 配置线上建议也配置上,目前 1.0.2 版本的默认配置文件中并不包含此项。
-
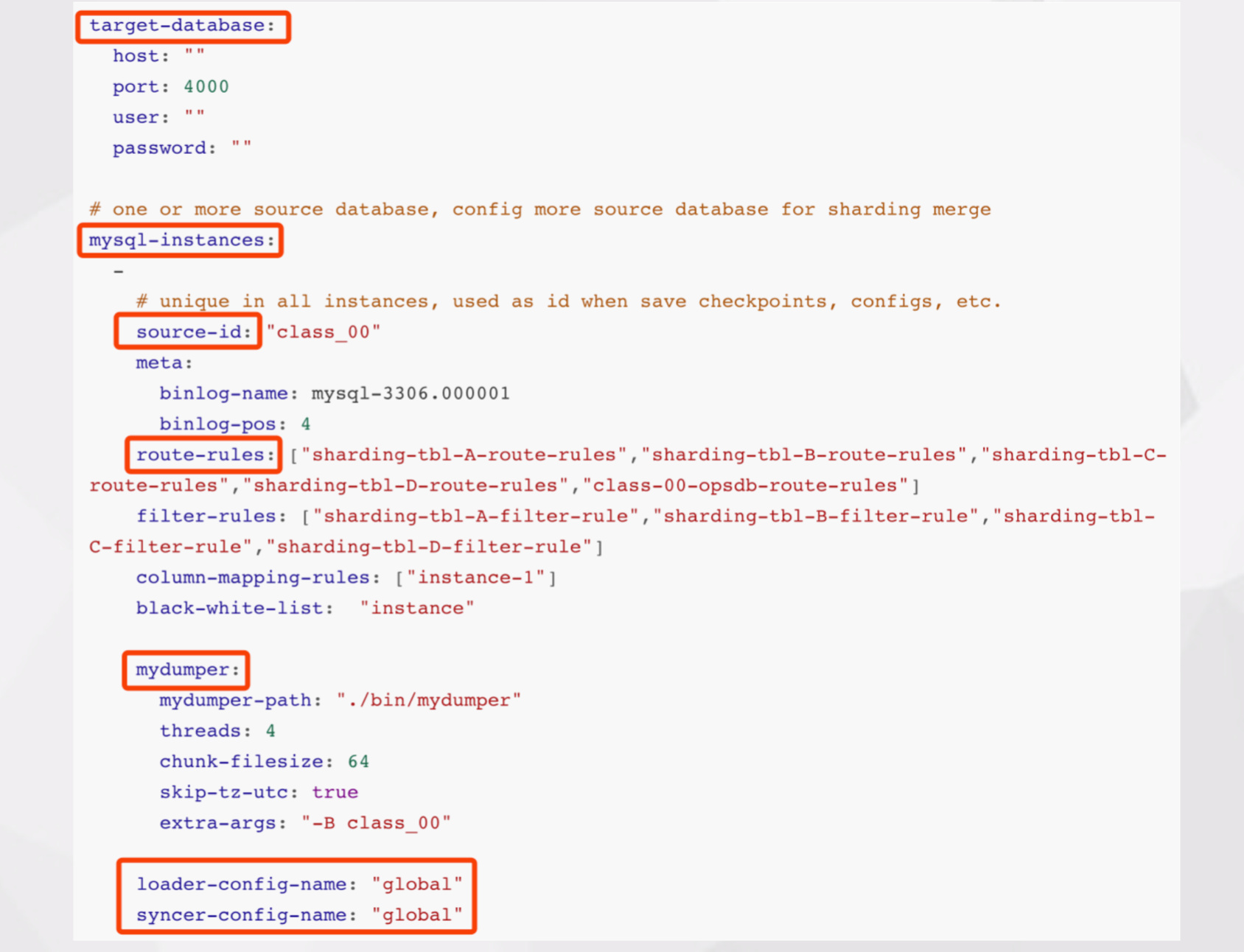
第二部分是下游 TiDB 的连接配置信息;
-
再下面就是对应每个 dm-worker 的 task 配置信息。包括对应上游 MySQL 实例的信息,比如
- source-id 以用来定位/映射到具体的 dm-worker;
- meta 只做增量同步时的点位配置信息;
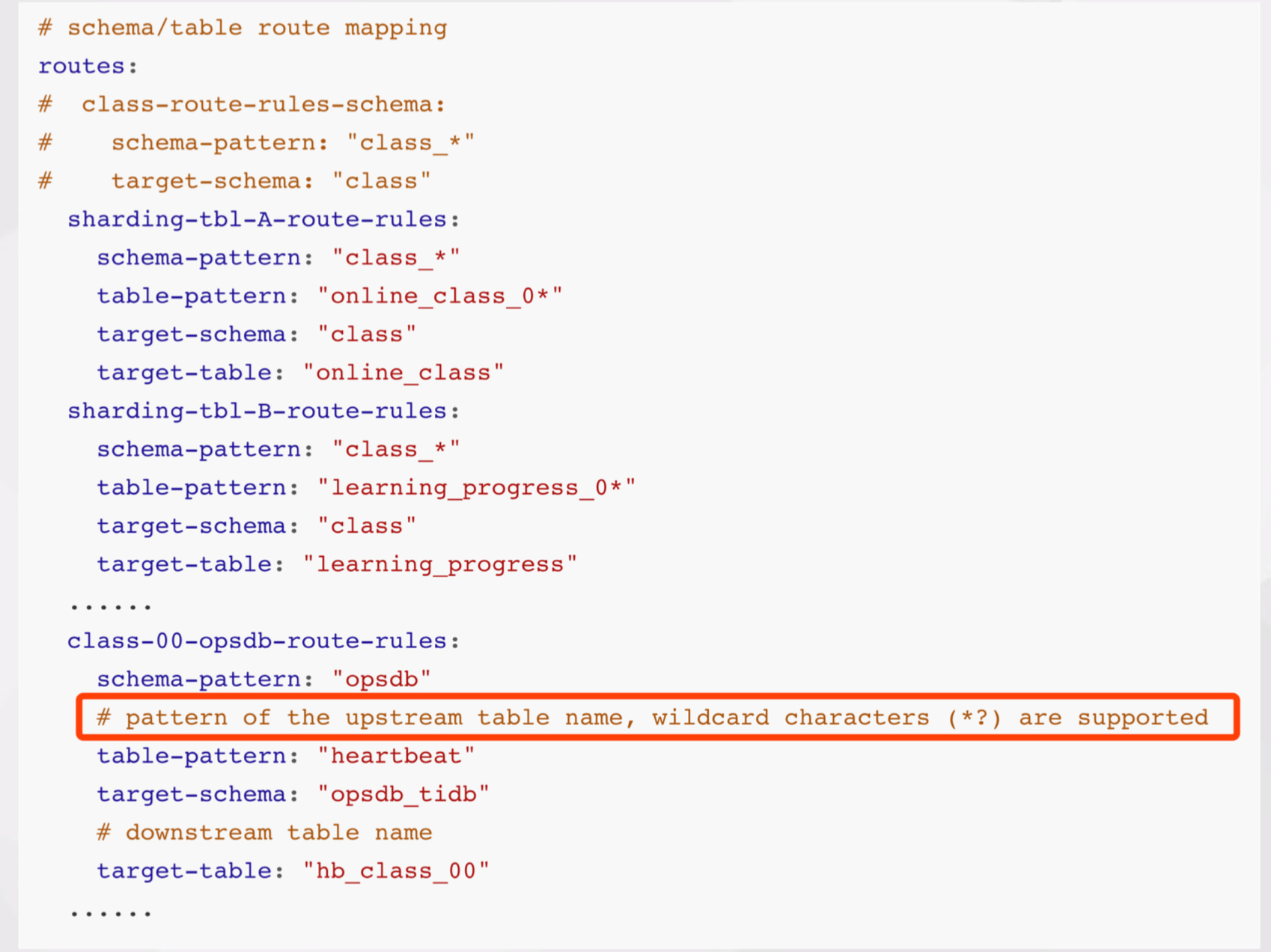
- route-rules 库表同步路由配置信息,分库分表的实现,就依赖这个功能;
- filter-rules 库表过滤规则配置信息;
- black-white-list 数据同步黑白名单配置。
每个 instance 也可以有一个自定义的 Dumper 和 Loader 配置,实际上 Dumper、Loader、Syncer 也可以通用全局配置。之前我们在进行分库分表合并时有过一个 tidb-server 节点由于 loader 阶段压力过大挂掉的情况,这种情况下可以通过调整 loader 的并发参数限速,虽然 loader 阶段速度可能会变慢,但可以大大减少任务失败的概率。也支持调整 Syncer 阶段的同步速率。还有 safe-mode 模式,开启后可以把线上的 insert/update 替换成 replace。


这是我们改造之后的 DM 同步延迟监控,通过原有线上监控体系中的 MySQL 心跳机制,也同步到下游来监控同步延迟。可以看到,目前分库分表合并同步延时基本可以维持在 200 毫秒以内。

当然在使用 DM 的过程中我们也遇到了一些问题,比如:
- 对上游 MySQL 大事务兼容的问题。有这么一个 case,因为上游 MySQL 在一个事务中进行了大批量的删除操作,将一个 Binlog 撑到了 7G +;而 DM-Woker 在写 relay log 时需要依据 binlog position 及文件大小对 event 进行验证,并且需要保存同步的 Binlog Position 信息作为 checkpoint。但是 MySQL Binlog Position 官方定义使用 uint32 存储,所以超过 4G 部分的 Binlog Position 的 offset 值会溢出。解决方法如下:

- 上游 MySQL 中表的数量超过了 5000,增量同步任务阶段,任务本身未显示异常,但实际同步不再往前推进。主要是因为虽然需要分库分表合并的表的数量只有 1024 个,但上游 MySQL 中总共有 7600 + 张表。当前的版本中,更新 dm-meta 中的元数据信息时时对应总表的数量,所以触发了 stmt-count-limit 的限制。可以通过临时调整指定 TiDB-Server 的 stmt-count-limit 配置(默认:5000,→ 8000)解决。

- sql-skip 不生效。可以通过如下方式解决:

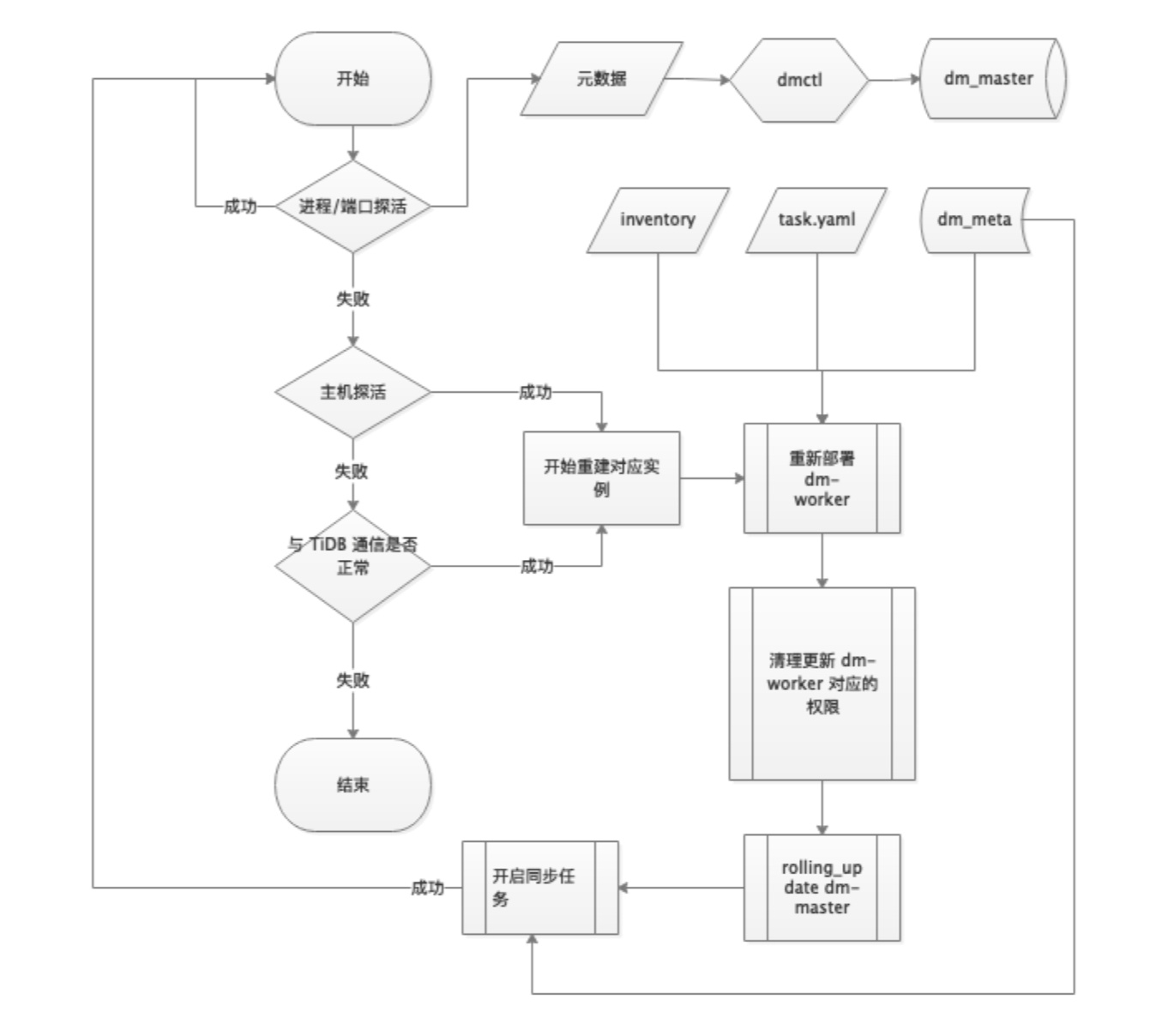
最后,因为后续 TiDB 要承载更多的线上流量/服务,所以对 DM 同步的稳定性、实时性等就要更加的严格了,所以我们对 DM 也做了一些高可用探索。主要还是通过利用 DM 持久化数据和在备机上自动重新部署故障组件的方式实现高可用,大家可以参考下下面整理的一些思路: