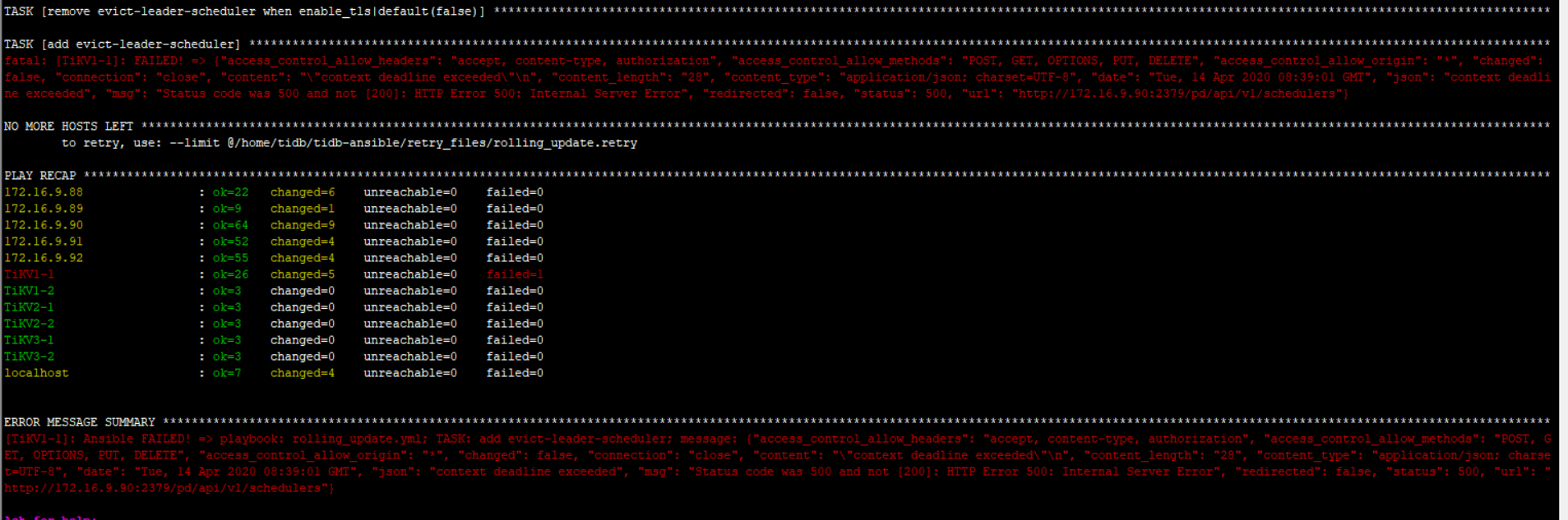
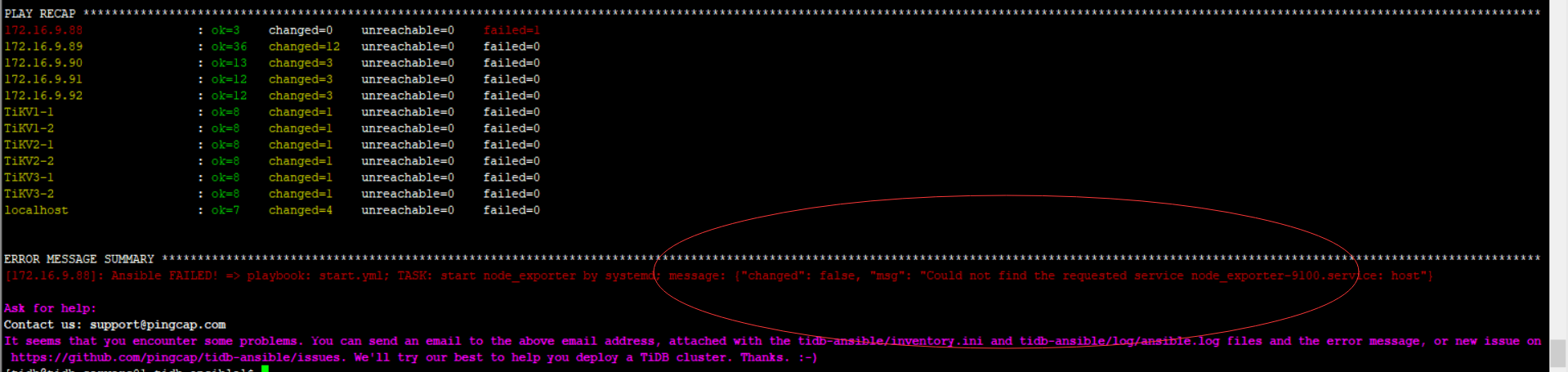
TASK [wait until the PD port is down] *********************************************************************************************************************************************************************************
fatal: [172.16.9.90]: FAILED! => {“changed”: false, “elapsed”: 300, “msg”: “the PD port 2379 is not down”}
NO MORE HOSTS LEFT ****************************************************************************************************************************************************************************************************
to retry, use: --limit @/home/tidb/tidb-ansible/retry_files/excessive_rolling_update.retry
PLAY RECAP ************************************************************************************************************************************************************************************************************
172.16.9.88 : ok=22 changed=6 unreachable=0 failed=0
172.16.9.89 : ok=9 changed=1 unreachable=0 failed=0
172.16.9.90 : ok=42 changed=6 unreachable=0 failed=1
172.16.9.91 : ok=17 changed=1 unreachable=0 failed=0
172.16.9.92 : ok=17 changed=1 unreachable=0 failed=0
TiKV1-1 : ok=15 changed=5 unreachable=0 failed=0
TiKV1-2 : ok=3 changed=0 unreachable=0 failed=0
TiKV2-1 : ok=3 changed=0 unreachable=0 failed=0
TiKV2-2 : ok=3 changed=0 unreachable=0 failed=0
TiKV3-1 : ok=3 changed=0 unreachable=0 failed=0
TiKV3-2 : ok=3 changed=0 unreachable=0 failed=0
localhost : ok=7 changed=4 unreachable=0 failed=0
ERROR MESSAGE SUMMARY *************************************************************************************************************************************************************************************************
[172.16.9.90]: Ansible FAILED! => playbook: excessive_rolling_update.yml; TASK: wait until the PD port is down; message: {“changed”: false, “elapsed”: 300, “msg”: “the PD port 2379 is not down”}
Ask for help:
Contact us: support@pingcap.com
It seems that you encounter some problems. You can send an email to the above email address, attached with the tidb-ansible/inventory.ini and tidb-ansible/log/ansible.log files and the error message, or new issue on https://github.com/pingcap/tidb-ansible/issues. We’ll try our best to help you deploy a TiDB cluster. Thanks. ![]() pd.rar (3.3 MB)
pd.rar (3.3 MB)
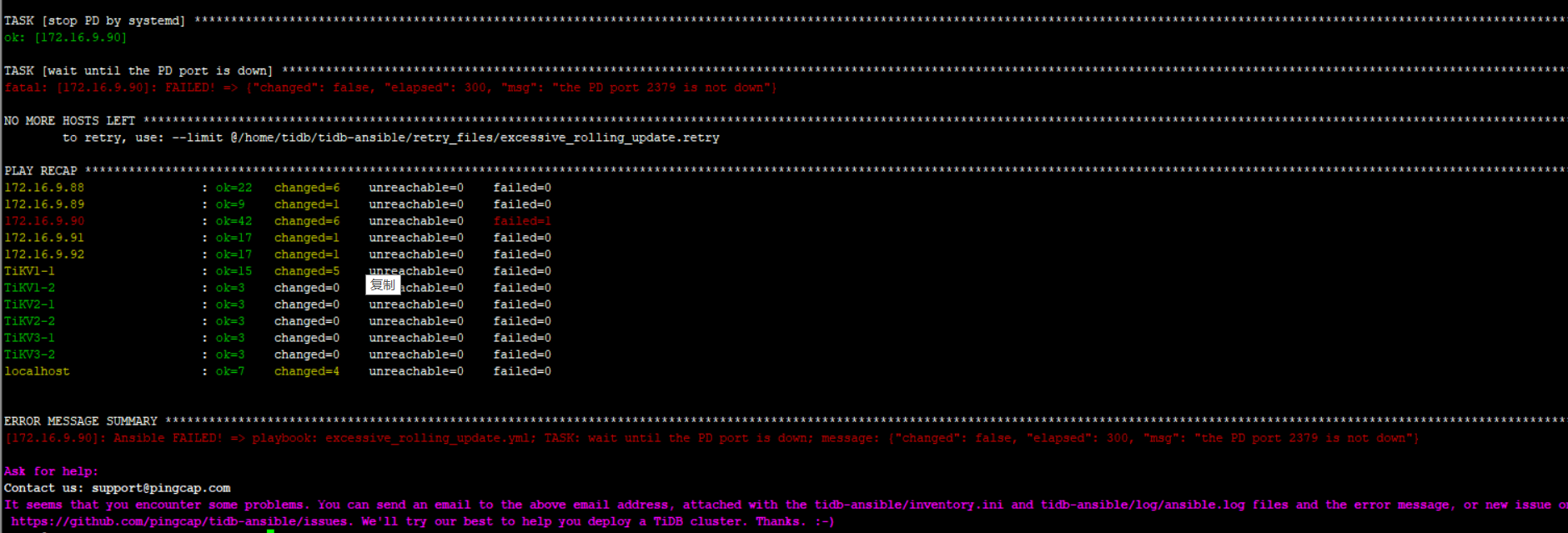


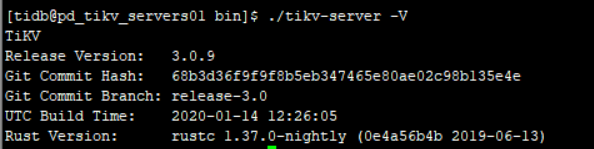
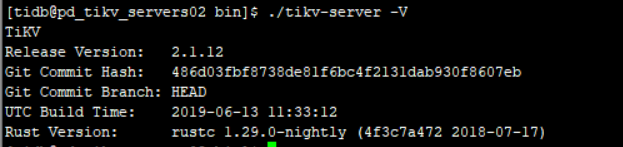
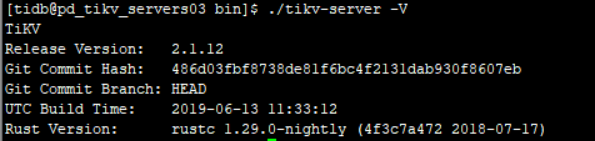
 三个版本都是这个
三个版本都是这个