###【TiDB 版本】:
3.0.11
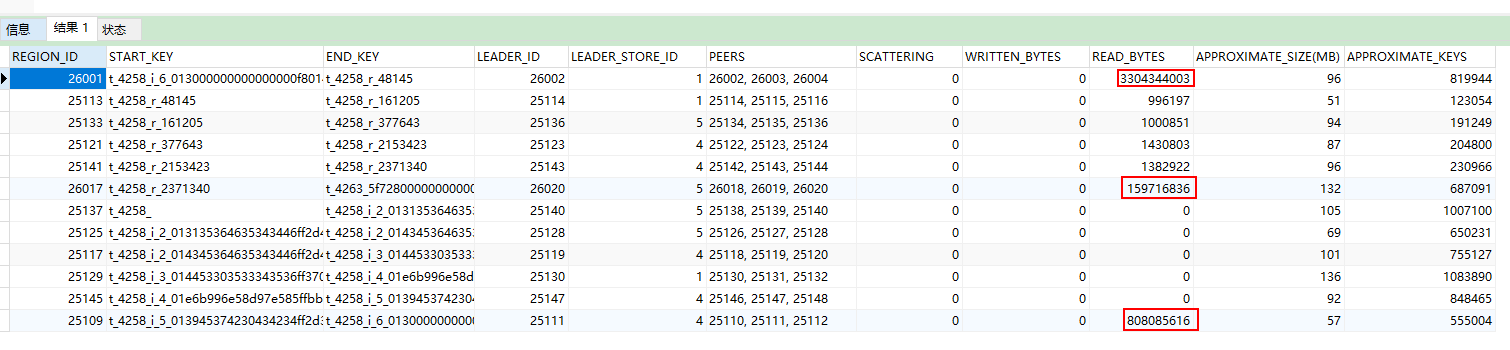
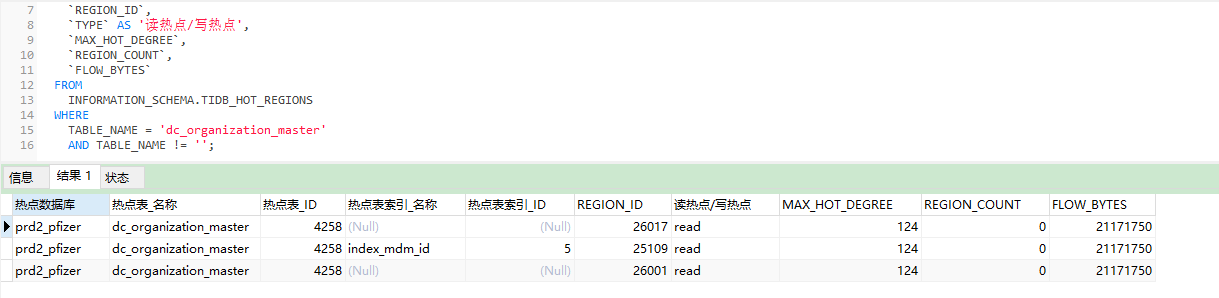
从图中可以看出是 REGION_ID: 26001 这个索引有大量的读热点发生,但是看完官方文档还是不理解应该如何去选择打散的方式
[root@test1 ~]# curl http://192.168.192.31:10080/regions/26001
{
"region_id": 26001,
"start_key": "dIAAAAAAABCiX2mAAAAAAAAABgEwAAAAAAAAAPgBRFMwMjA4MTj/MQAAAAAAAAD4ATMAAAAAAAAA+AOAAAAAAAA3hw==",
"end_key": "dIAAAAAAABCiX3KAAAAAAAC8EQ==",
"frames": [
{
"db_name": "prd2_pfizer",
"table_name": "dc_organization_master",
"table_id": 4258,
"is_record": false,
"index_name": "index_1",
"index_id": 6,
"index_values": [
"0",
"DS0208181",
"3",
"14215"
]
},
{
"db_name": "prd2_pfizer",
"table_name": "dc_organization_master",
"table_id": 4258,
"is_record": true,
"record_id": 48145
}
]
}[root@test1 ~]#
yilong
2020 年4 月 3 日 05:51
3
老师我直接输入这个值就可以吗?
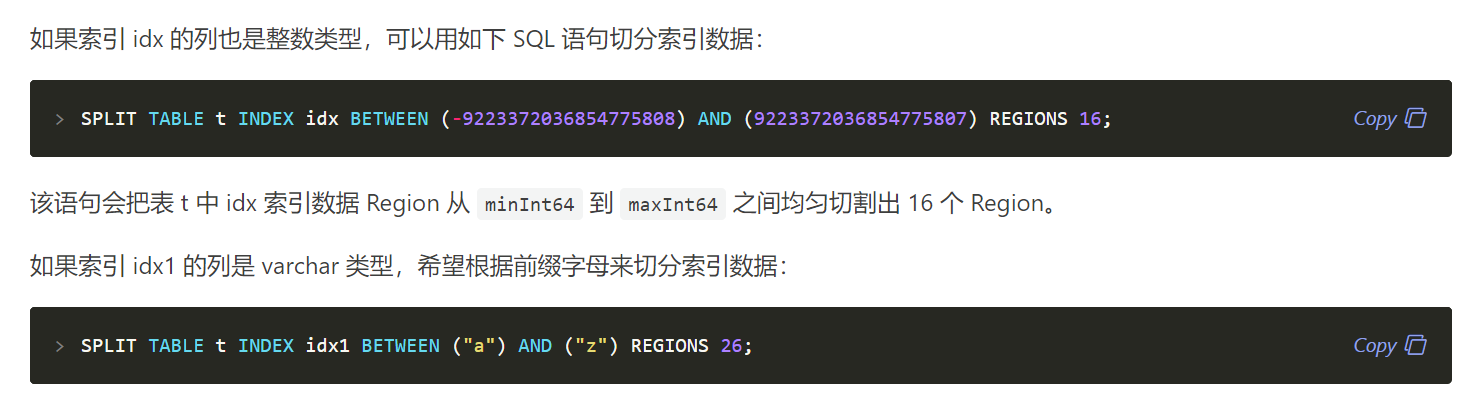
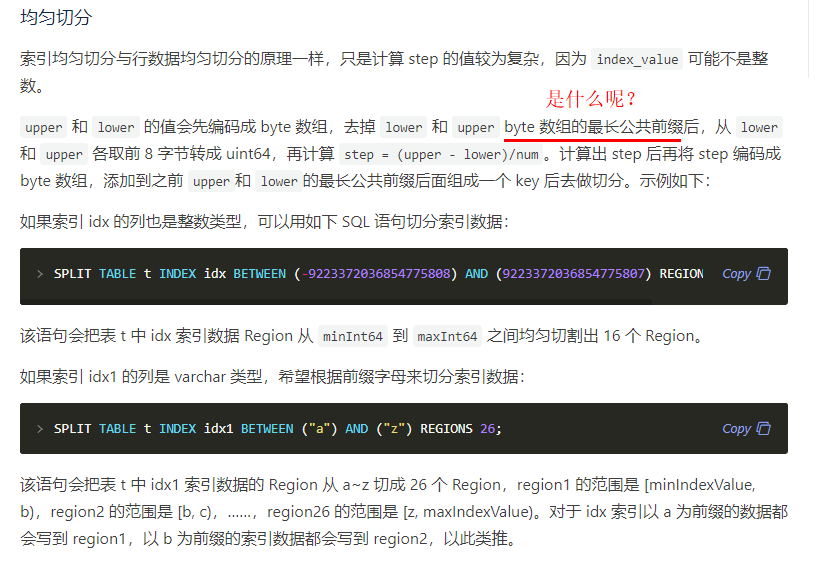
BETWEEN (-9223372036854775808) AND (9223372036854775807)
如果我的索引列是UUID的 就使用这种? BETWEEN ("a") AND ("z")
那REGION 的数据我应该写多少呢?根据什么算出来的 REGIONS 16; REGIONS 26;?
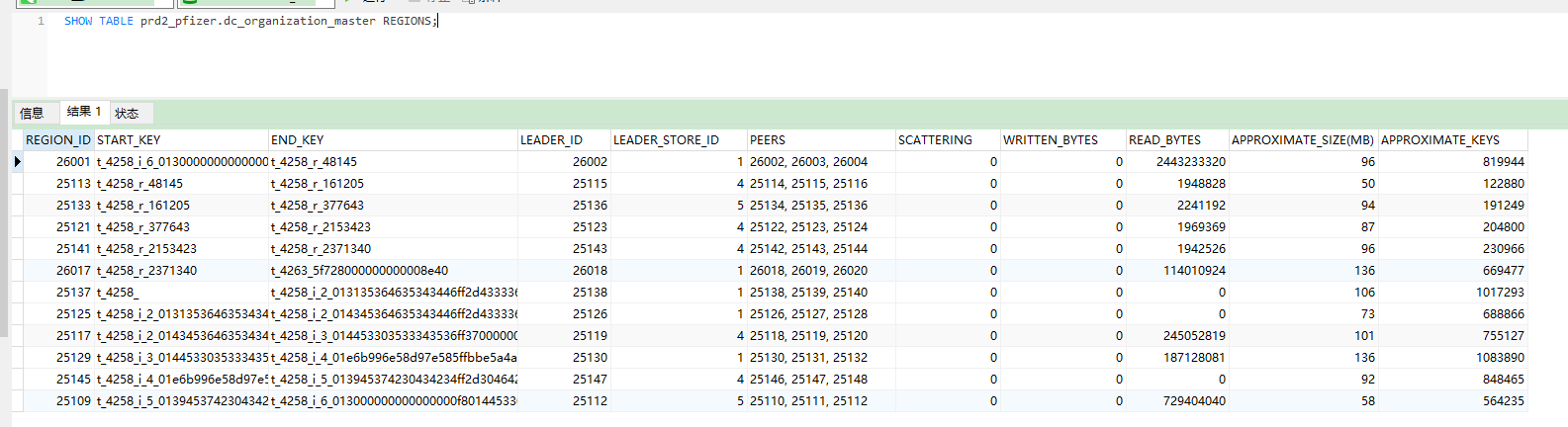
可不可以麻烦老师,就下面这两个完整的 key 给解释一下呢?
START_KEY: t_4258_i_5_013945374230434234ff2d304642382d4539ff31312d393431322dff3030353035363831ff3946454200000000fb03800000000000a315
END_KEY: t_4258_i_6_013000000000000000f8014453303230383138ff3100000000000000f8013300000000000000f8038000000000003787
您好,能否提供表结构,或者想要打散的索引类型,及其覆盖的范围?
...省略
`mdm_id` varchar(200) DEFAULT NULL COMMENT 'MDMID',
...省略
PRIMARY KEY (`paas_id`),
KEY `geography_id_fk_index` (`geography_id`),
KEY `codeName_index` (`organ_code`,`organ_name`,`paas_is_del`),
KEY `organ_name` (`organ_name`),
KEY `index_mdm_id` (`mdm_id`),
KEY `index_1` (`paas_is_del`,`organ_code`,`status`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='机构主数据';
额,抱歉,之前我的同事误认为您是要解决写入热点。上面的文档是用来解决写入热点的。对于读热点,目前我们支持基于读流量的热点调度,后台会根据您的访问流量自动去调度,不需要您做任何介入。
老师,我现在很不理解啊,我这个读热点的问题,感觉一直都没有变化呢,始终是那一台机器压力很大,而且一直是 这个 26001 REGION 的压力大,其它的都没有什么压力啊,压力并没有被均匀的平分到空闲的机器上,难道以后遇到的 读热点都不需要人为去解决了吗?
如果您只是这个单一 Region 形成热点,而且长期没有被打散。。。比如大量请求频繁 scan 一个小表,这个可以从业务角度或者 metrics 统计的热点信息看出来。由于单 Region 热点现阶段无法使用打散的手段来消除,需要确认热点 Region 后手动添加 split-region 调度将这样的 Region 拆开。
具体文档,请等我一下出来。。或者你可以用 pd-ctl help 可以先看一下。。
这个表 里面有 100万数据数据量不大, 是主数据表, 但是很多业务都会使用这个表中的数据来做数据校验匹配,查询相当的频繁,目前采用了临时方案,将这个表中的数据抽取到 elasticsearch 中, 不过我还将希望寄托在TiDB上了
yilong
2020 年4 月 3 日 08:24
12
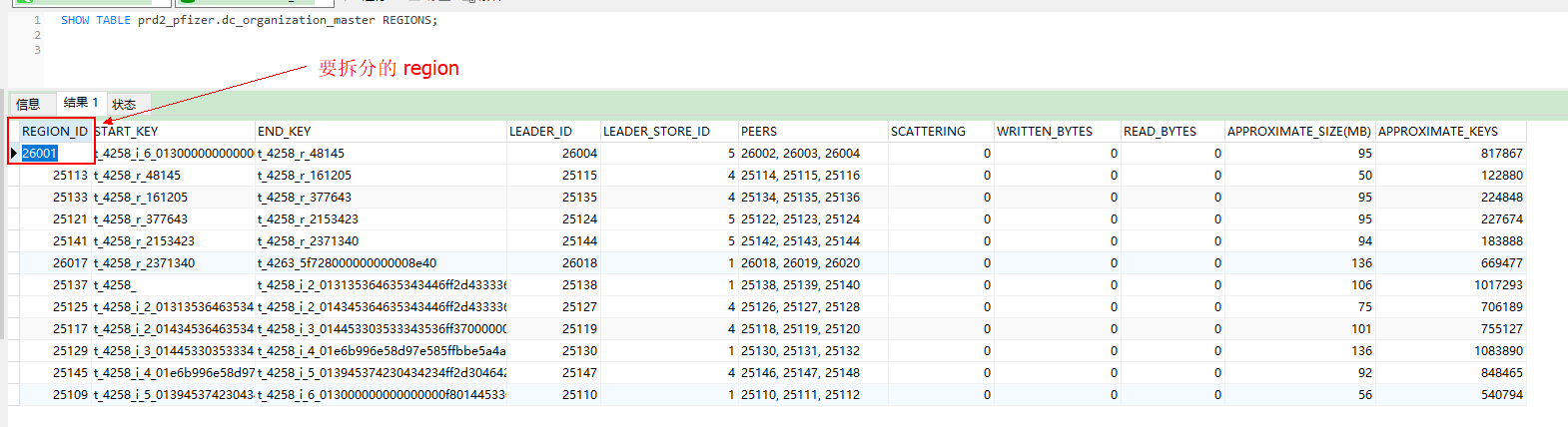
可以用这个命令把固定的region先一分为2.
https://pingcap.com/docs-cn/stable/reference/tools/pd-control/#operator-show--add--remove
>> operator add split-region 1 --policy=approximate // 将 Region 1 对半拆分成两个 Region,基于粗略估计值
>> operator add split-region 1 --policy=scan // 将 Region 1 对半拆分成两个 Region,基于精确扫描值
1 个赞
operator add split-region 1 --policy=approximate 这个命令吗?
[tidb@back-paas bin]$ pwd
/home/tidb/tidb-ansible/resources/bin
[tidb@back-paas bin]$
[tidb@back-paas bin]$ ./pd-ctl -u http://192.168.192.31:2379 operator add split-region 26001 --policy=approximate
yilong
2020 年4 月 3 日 08:56
14
是的,region id写你想要分的region id就行
system
2022 年10 月 31 日 19:15
15
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。