为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】:3.0.7
- 【问题描述】:系统中突然出现大量慢sql,持续一段时间后,又恢复正常。请问需要如何定位呢。
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出打印结果,请务必全选并复制粘贴上传。
为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出打印结果,请务必全选并复制粘贴上传。
(1)、chrome 安装这个插件https://chrome.google.com/webstore/detail/full-page-screen-capture/fdpohaocaechififmbbbbbknoalclacl
(2)、鼠标焦点置于 Dashboard 上,按 ?可显示所有快捷键,先按 d 再按 E 可将所有 Rows 的 Panels 打开,需等待一段时间待页面加载完成。
(3)、使用这个 full-page-screen-capture 插件进行截屏保存
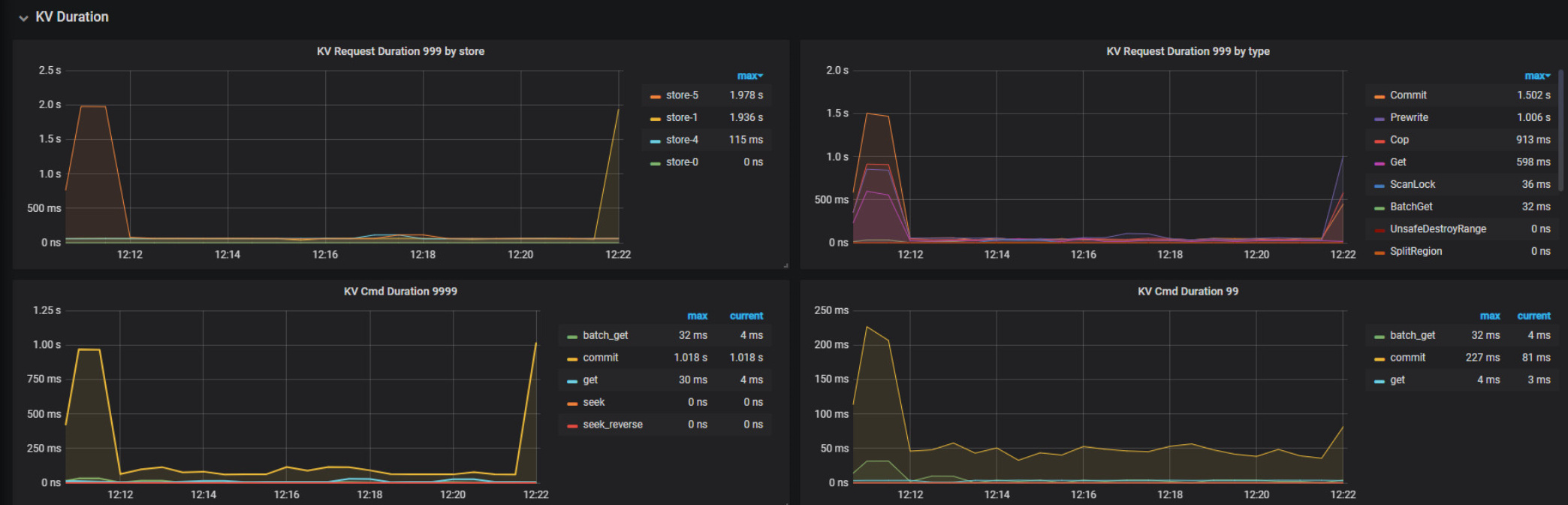
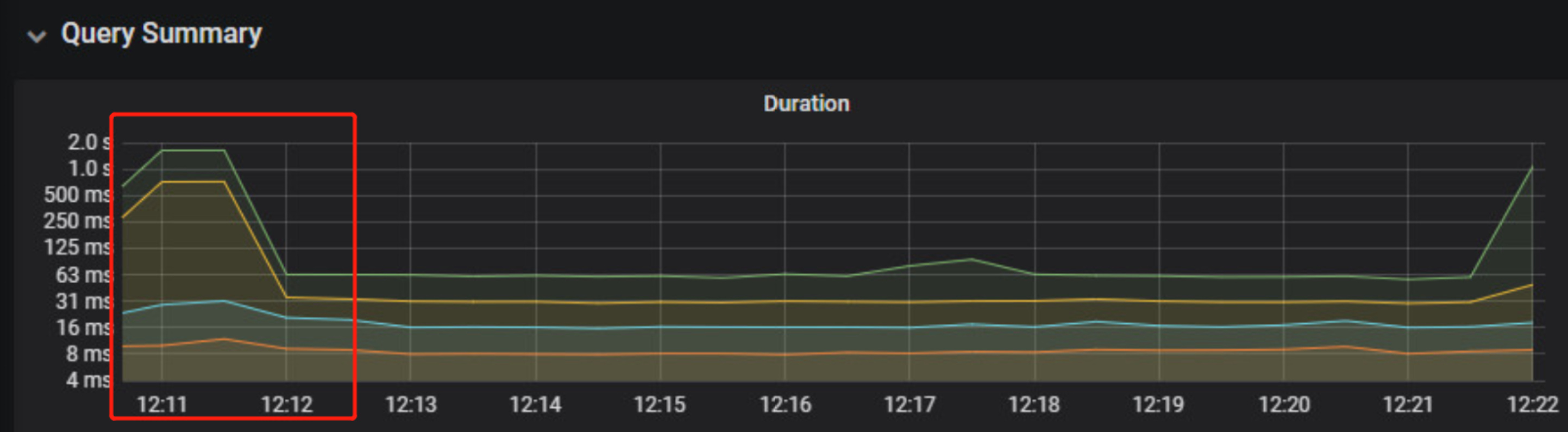
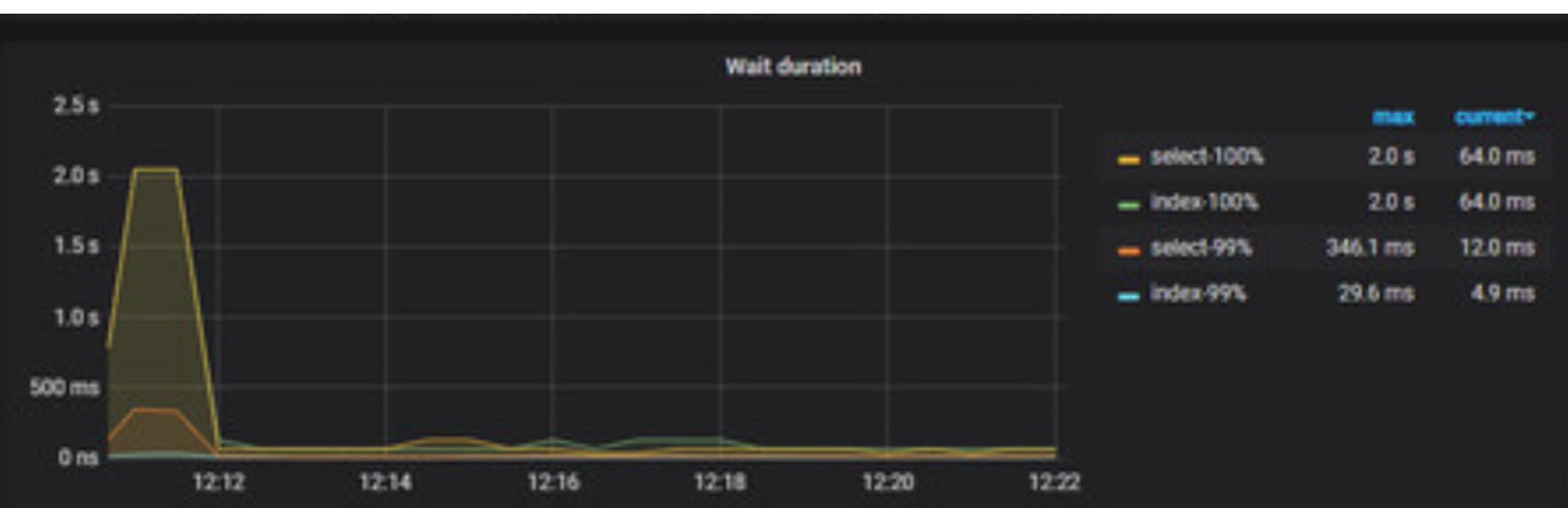
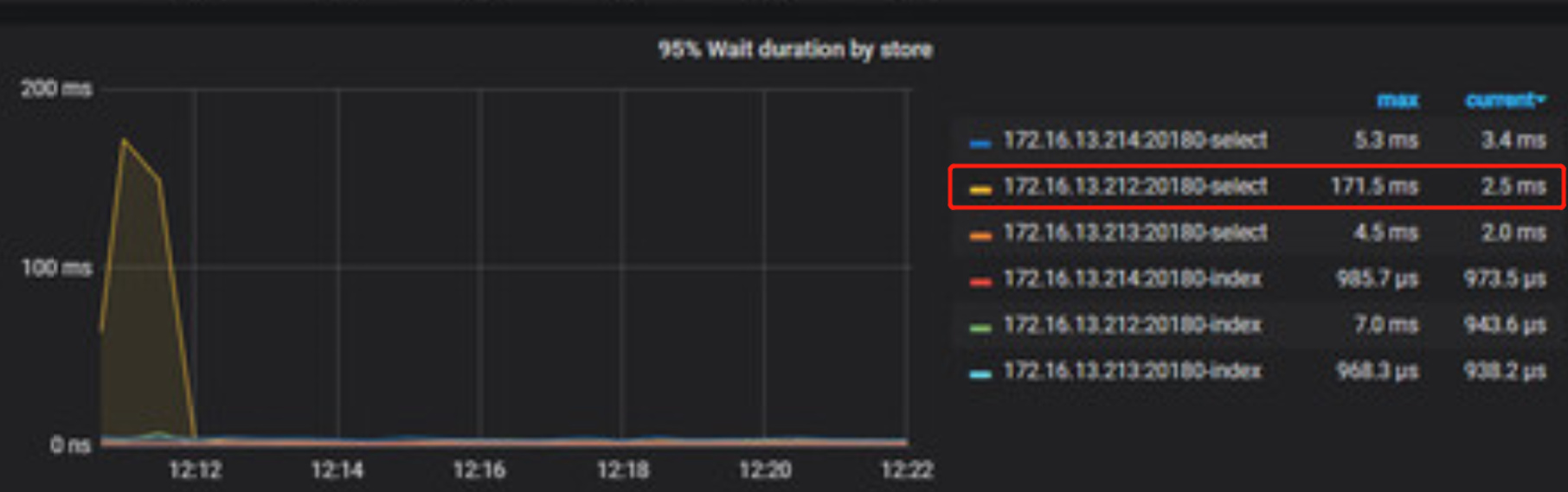
从duration看主要是12:11 到12:12 duration升高
查看kv duration
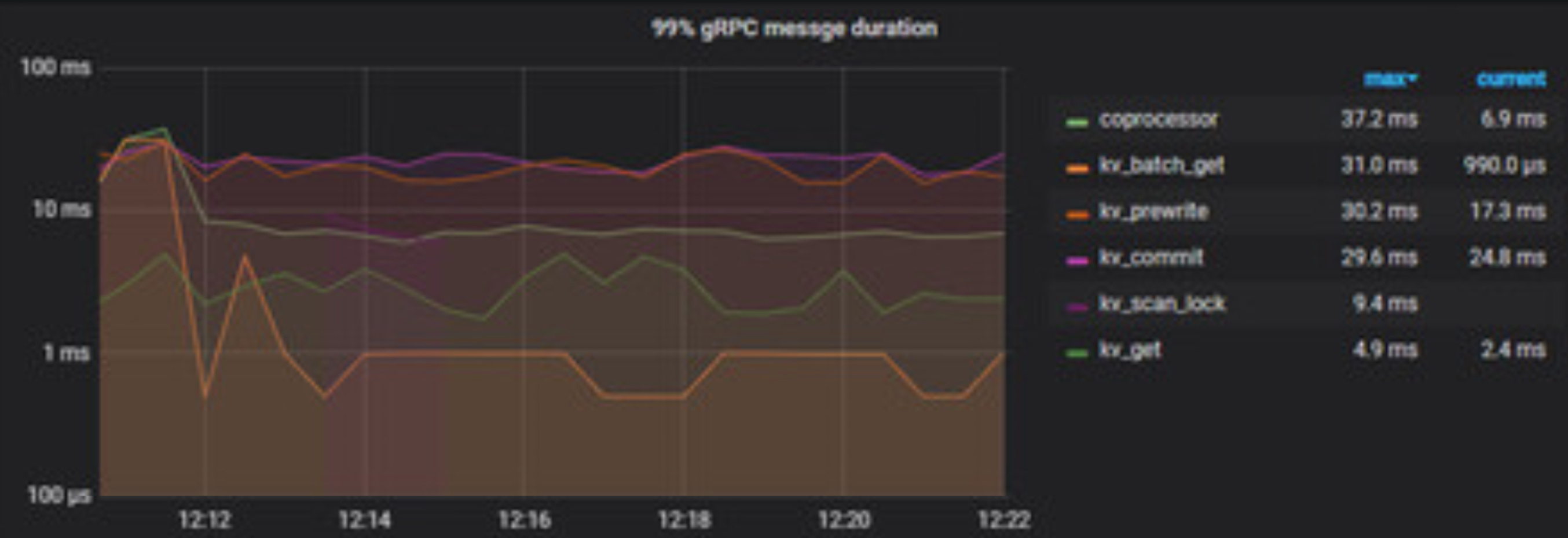
查看tikv duration在30ms左右
感觉有可能是有一些批量的操作造成了热点。之前的监控时间对不上,麻烦上传下over-view的监控信息和12:11-12:12的slow日志。 也可以查一下,当时业务上是否有什么批量操作
[下步计划]
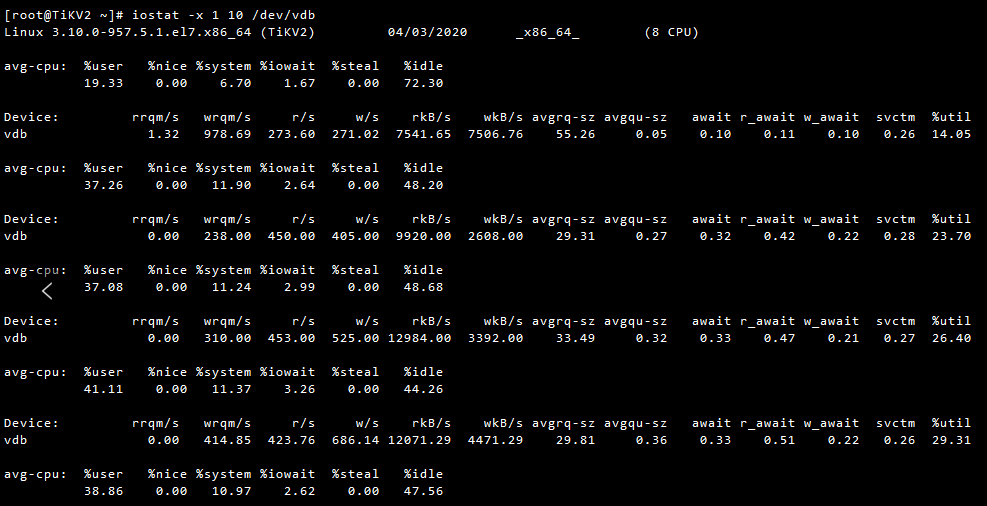
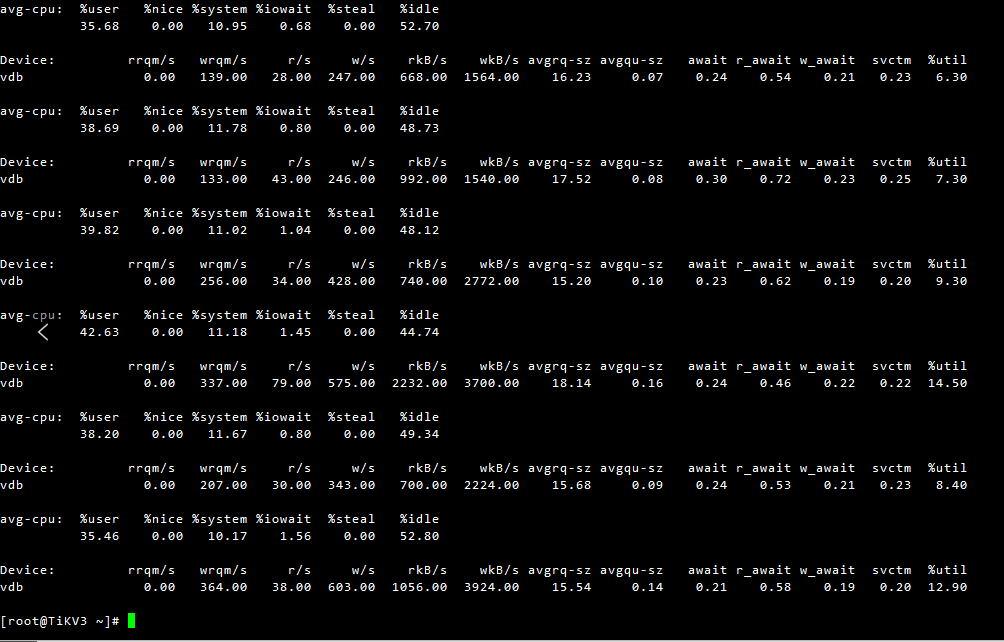
先来看一下这个store的IO,我有一点疑惑,一直是100%?
这个节点一直是100%,找阿里云定位都找不出原因来,但是测试磁盘IO性能,是正常的,以前的帖子,有发过fio测试报告
阿里云替换磁盘后,212节点的io util正常
但是还是偶尔会出现慢SQL的情况,麻烦再帮忙看看
慢sql时间是16:10~16:40
监控数据比较大,上传到网盘的
提取码6f4s
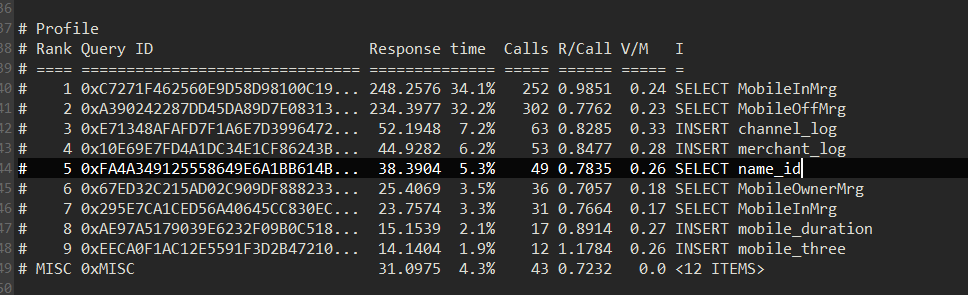
对应时间段的慢sql分析
slow0410.rar (4.0 KB)
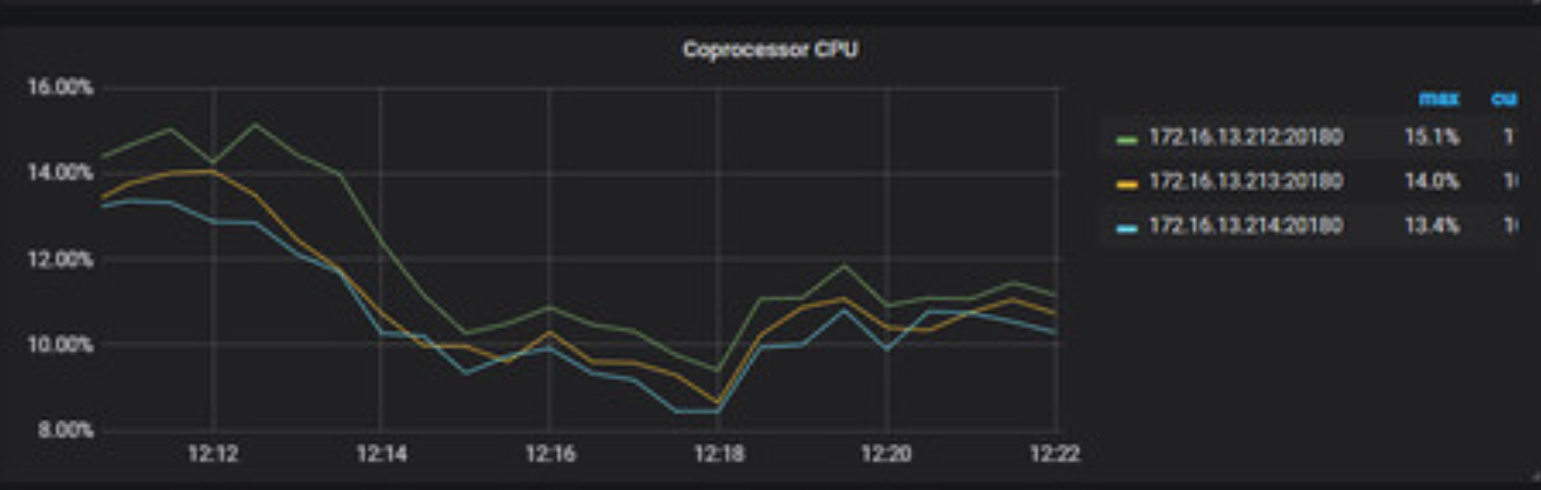
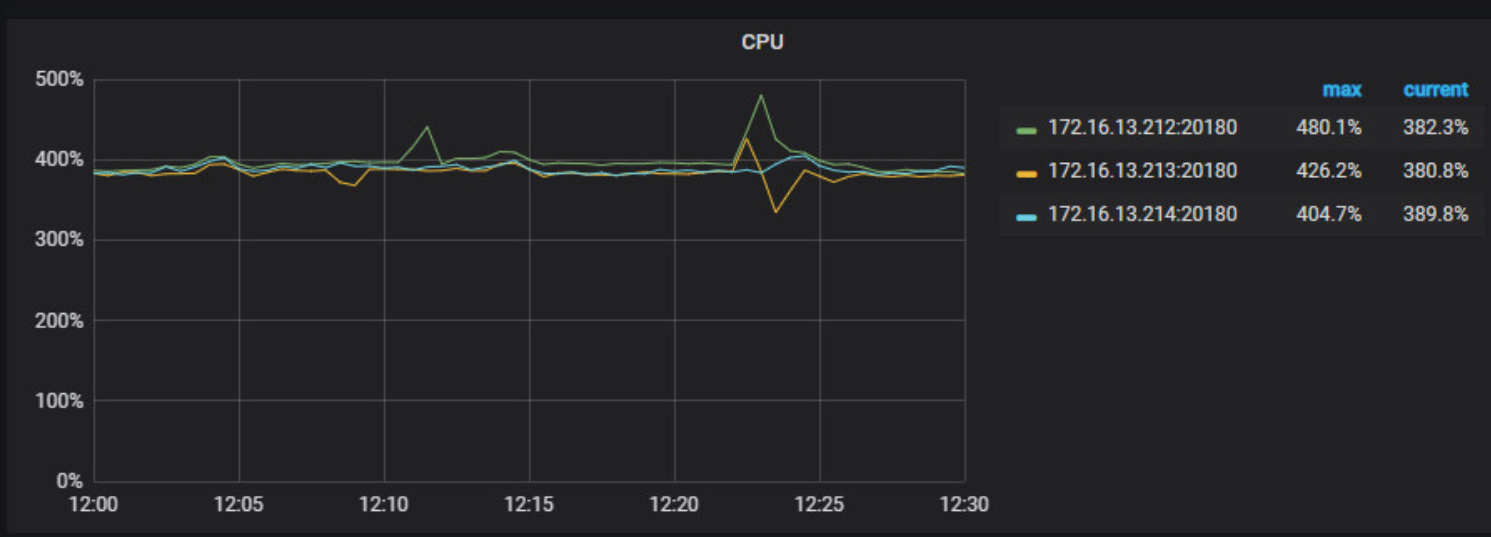
根据监控以及日志信息,在16:10~16:40 时间区间内,读流量很高,确认下是否业务在这个时间段有大流量进来导致查询变慢,其次 coprocessor 面板 handle duration 中每个 store 时间都偏高,coprocessor CPU 没有到达瓶颈,考虑从语句侧看下是否有优化空间。参考文档: