为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】:3.0.7
- 【问题描述】:
使用的tidb-enterprise-tools-latest-linux-amd64,版本为
mydumper 0.9.5 (ba3946edc087e87bba7cb2728bc2407f6dbd0a8b), built against MySQL 5.7.24
[root@qydataali19 bin]# ./loader -V
Release Version: v1.0.0-78-g6aea485
Git Commit Hash: 6aea4851bb0c6e599c64b5c952ce257863c21586
Git Branch: master
UTC Build Time: 2019-12-18 04:25:49
Go Version: go version go1.13 linux/amd64
使用mydumper导出数据,280G,耗时90分钟。
使用loader导入数据就巨慢,从晚上11点开始,导入到第二天早上8点,就只能导入70G数据左右,开的是单线程,导入过程中,cpu、IO各种资源占用非常高,根本不敢开更多的多线程导入,影响正常业务访问
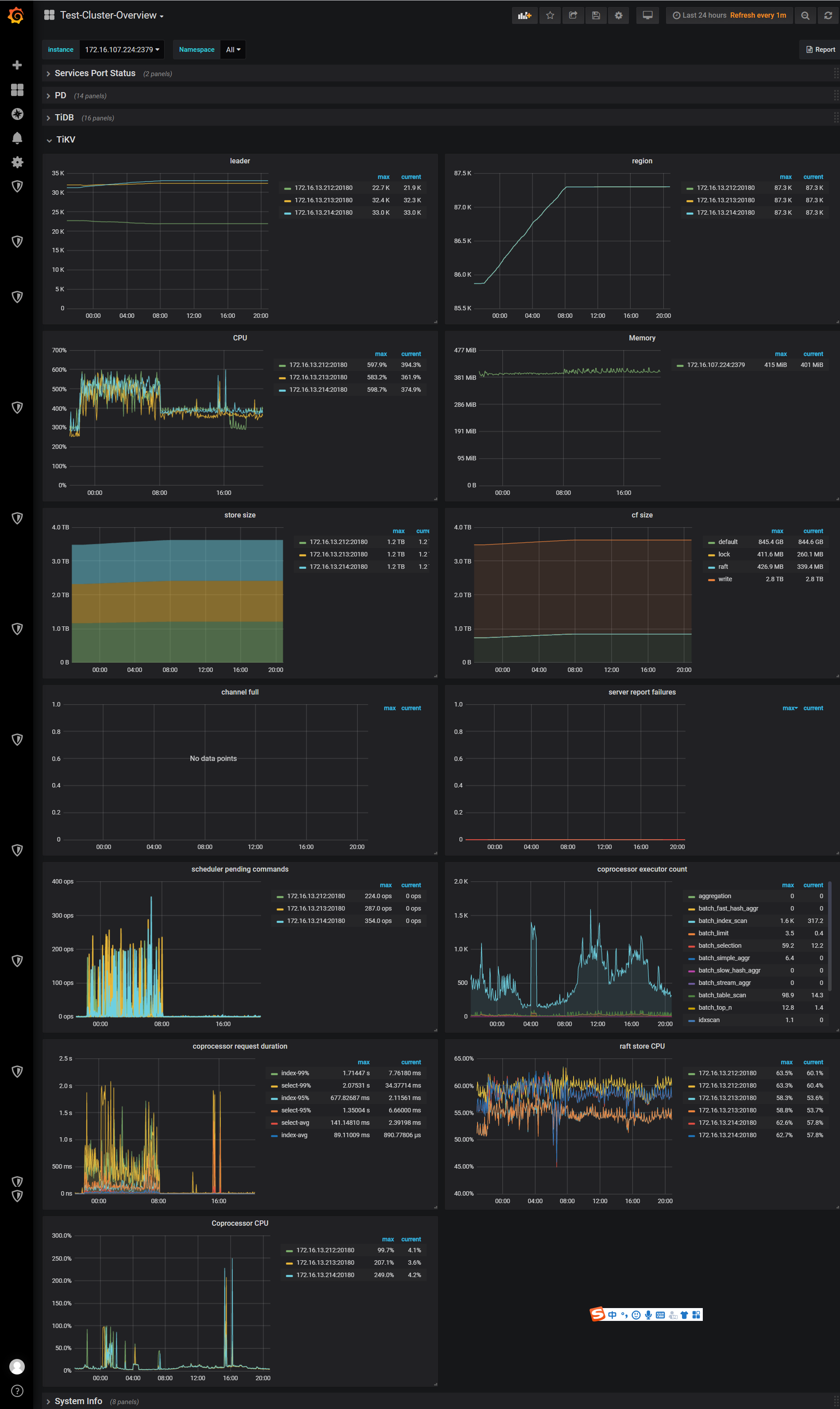
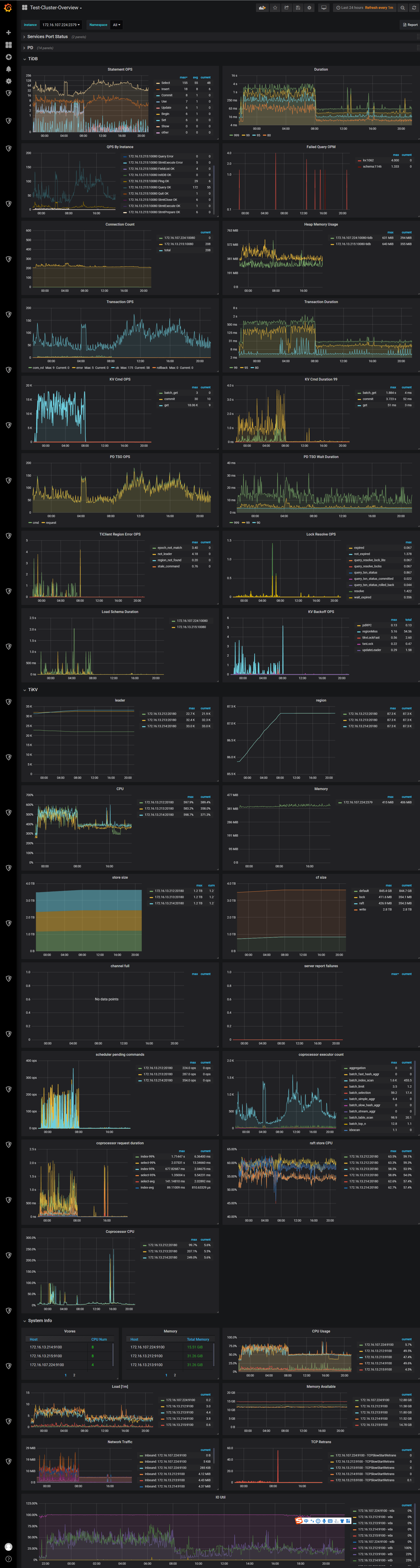
导入过程中tikv的资源占用情况,下面波峰部分,是导入数据的时间段
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。
1、性能截图
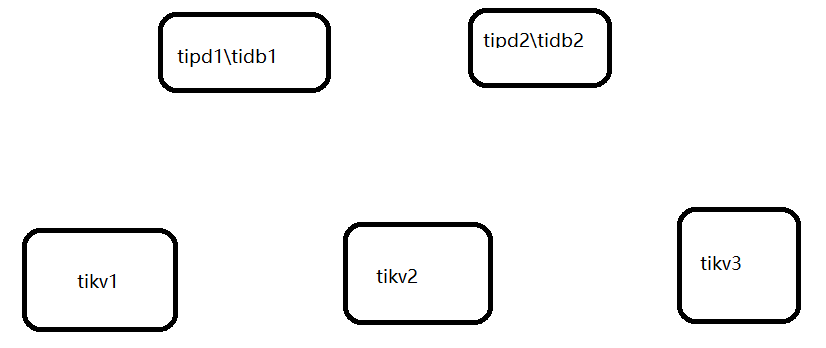
2、拓扑结构
3、机器配置
tidb和tipd服务器是8C16G,阿里云的ESSD磁盘
tikv是8C32G,阿里云的ESSD磁盘
4、mydumper文件是单独的一台服务器,并没有放在tidb集群的服务器上面
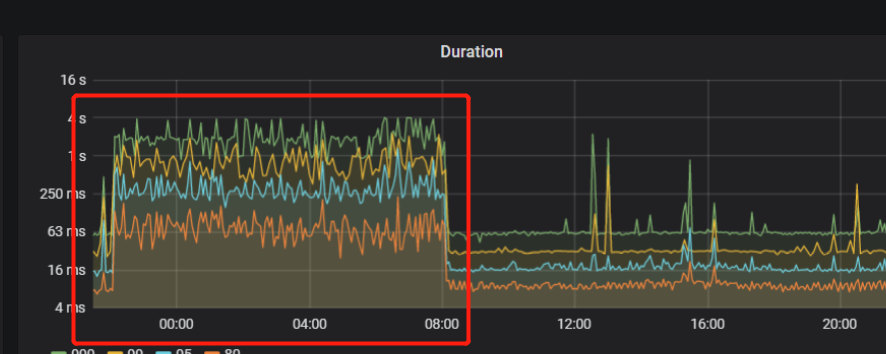
1、导入数据时间段duration比较高,表示什么意思呢
2、配置发了,tidb和tipd是8C16G,tikv是8C32G,loader文件存放的服务器配置是8C64G
3、监控文件
4、slow log
slow41.rar (14.3 KB)
yilong
(yi888long)
8
[问题澄清]
TiDB 集群版本 : v3.0.7
问题描述 :在 00 : 00 - 08 : 00 使用 MyLoader 导入时集群变慢
拓扑结构 :
[问题分析]
- 判断读慢还是写慢,用户反馈都慢,查看慢日志统计pt-query-digest,读写都有
- 大部分时间消耗在 wait time
- 查看监控 Duration ,在导入时间内延时大幅增加
- 查看 TiKV 99 message duraiton , 在 TiKV 读写都慢
- 按照写流程查看,storage async write duration , 99% 达到 1.6s
- 查看 Propose wait duration : 1.4s 以上 , 这是后说明是 raft store 繁忙 , 原因是 append log 速度慢 , 或者 raft store cpu 高
- 查看 raft store append log 和 apply log 速度都不慢 ,查看.9999也不是很慢
- 查看 raft store cpu,达到了120% 多 , 这里参考排查Map,应当是到达 85% *2 =170%才算高 ,但是注意,当 IO 满的时候, CPU 打不上去了. 或者 总体 CPU 满
- rocksdb kv 监控里面的 get 和 write 在导数期间的变化
- 先排查总体 CPU , 8c 的配置,并没有打满, 但是可以看到没有导数据的时候也有将近 400% 的 CPU , 这里需要怀疑, 是不是 region 太多了心跳开销导致 raftstore 和 grpc cpu 高
- 查看 Load
- 查看 node export 监控中的 cpu usage 中存在 iowait 并且 3 个tikv 实例达到 3.x ,4.x,5.x ,说明 IO 压力大 .
- 查看 IO 使用率还是很高
[下步计划]
- https://github.com/tikv/tikv/blob/master/etc/config-template.toml#L458
[rocksdb]
rate-bytes-per-sec = “100MB”
[raftdb]
rate-bytes-per-sec = “50MB”
这两个参数能限制 kvdb 和 raftdb 的写盘峰值,平滑写盘压力。一般盘比较差的时候能缓解抖动问题
- 开启静默region
注意: 如果修改ansible的conf文件,参数是 :,如果是tikv下的参数,是=
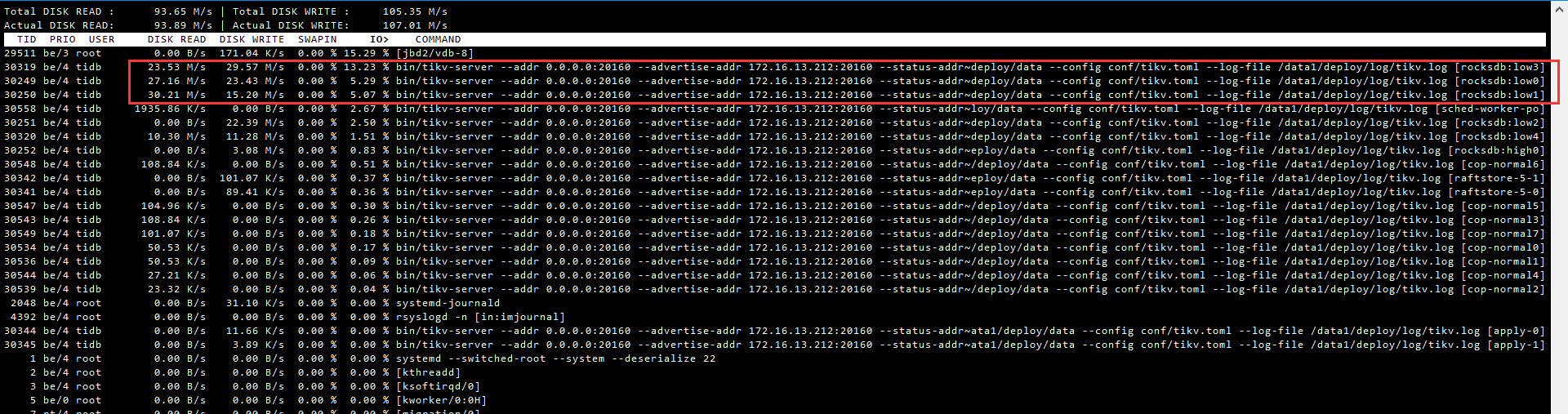
有问题的tikv节点磁盘已替换,目前看来没有再出现ioutil 持续100%的情况,但是有个疑问,为什么只有替换了磁盘的节点,IO读写量很大,其他两个节点正常
之前没有问题的两台没有gc-work进程,占用io正常
yilong
(yi888long)
10
麻烦提交个新问题吧,这个和之前的问题没关系了。 可以先反馈下pd-ctl的store信息,监空信息麻烦也按照上面的都反馈下。 另外,是给你换了性能更高的盘了吗? 怎么读写这么多,IO占用还不高。