为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
【TiDB 版本】:tidb 4.0
【问题描述】:
1、有个大表,数据量在四千万,数据量还在不断增加,目前压测环境
2、存在热点索引
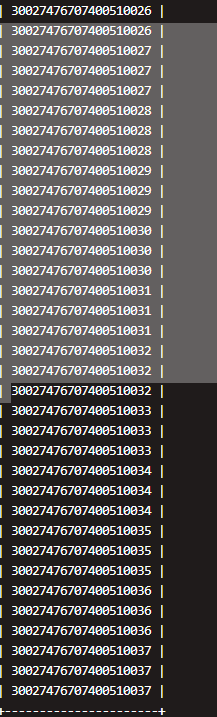
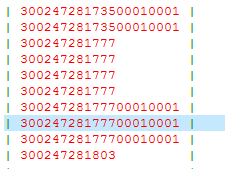
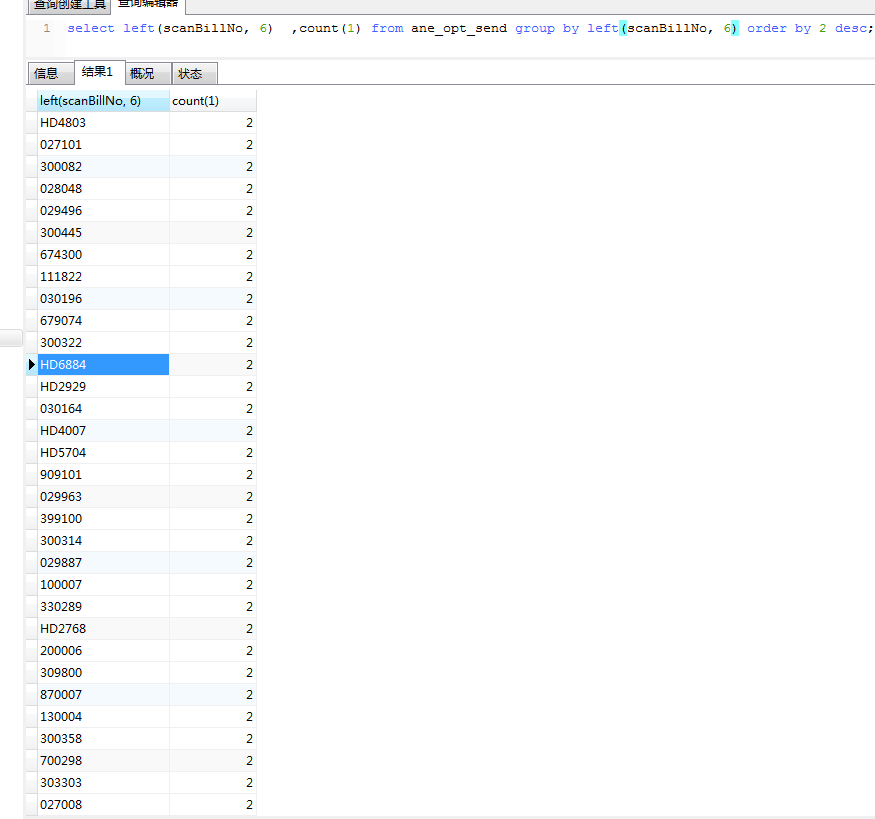
通过查看索引值 cola列 是varchar(30),并且值由大量的重复值,里面插入的是数值还有字符类型的数据
| 30024728173500010001 |
| 30024728173500010001 |
| 300247281777 |
| 300247281777 |
| 300247281777 |
| 300247281777 |
| 30024728177700010001 |
| 30024728177700010001 |
| 30024728177700010001 |
| 300247281803 |
±---------------------+
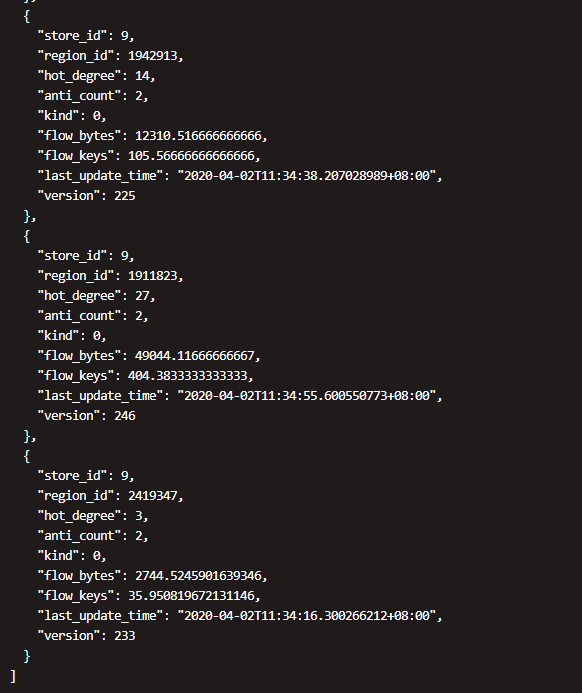
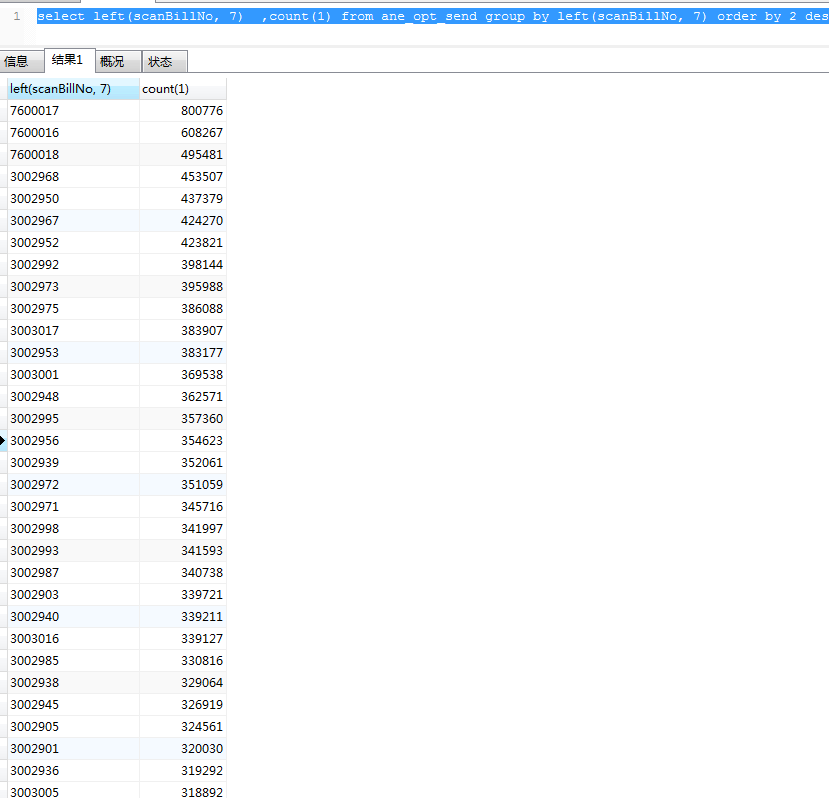
3、通过查询表TIDB_HOT_REGIONS,这个索引有40个 热点写region
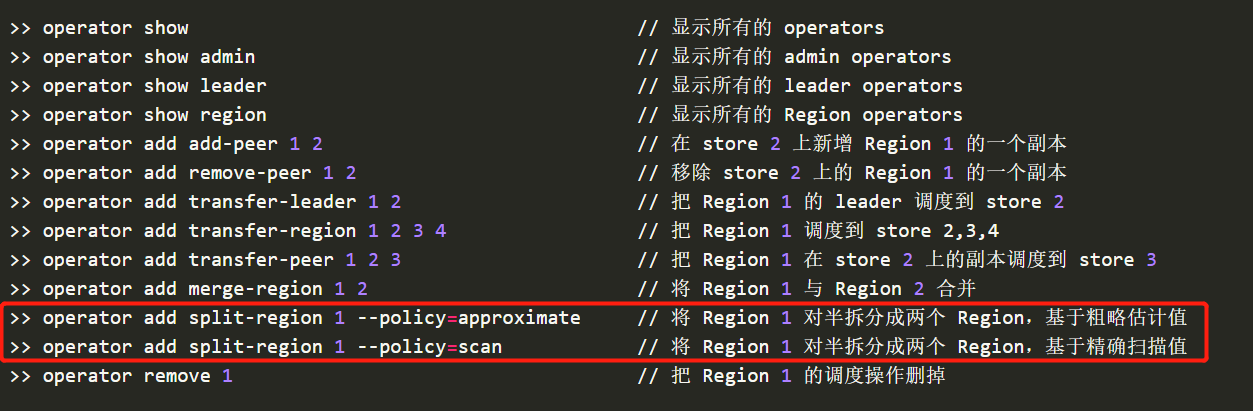
4、通过split region方式并没有解决热点块
pd-ctl -u http://172.18.1.3:2379 operator add split-region 2419158 --policy=approximate
5、官方文档通过这个方式拆分,但是列是字符类型的,存储的是数值类型或者字符类型,不知道如何拆分,而且存在很多重复的数据
SPLIT TABLE table_name [INDEX index_name] BETWEEN (lower_value) AND (upper_value) REGIONS region_num
问题,这个写热点如何解决
若提问为性能优化、故障排查 类问题,请下载脚本 运行。终端输出打印结果,请务必全选 并复制粘贴上传。
建表使用了参数 shard_row_id_bits=4 pre_split_regions =3,目前是索引存在大量热点
yilong
2020 年4 月 2 日 03:54
3
就是因为看了文档,不知道split 怎么拆分,范围不好确认,大部分是数值,列的类型却是varchar 类型的,很少部分是HD9897873 类型的
yilong
2020 年4 月 2 日 04:35
5
在varchar里这不是数值,是字符串,不知道你们的这些值有没有规律,是否都是这么多位数,那么你也可以参考a-z,这样划分一下 30000xxx 3000001xx 3000002xx 之类的,看下是否可行。
我对拆分这块的疑问:
1、由于对region拆分原理不懂,如果index 按照 a-z 这种类型的拆分,,由于数据量分布不均匀,拆分后仍然有数据倾斜,某个段的数据仍然有很多,怎么处理
2、index拆分后,某一个段的region满了以后,会自动拆分成更多的region吧
对于这种varchar 类型,但是里面是存放的数字的,而且一直是递增的值,索引热点如何解决,在现有有业务的情况下,我可以拆分一次,过半年,最后面哪个又变成热点,因为里面存放的数值一直递增,后期如何做
yilong
2020 年4 月 2 日 08:04
10
这个索引如果是单调递增的,并且持续并发写入那么应该集中到一个region上。
但是从你开始的答复可以看到,这个索引有40个 热点写region, 所以还是比较分散的。你应该可以按照递增的值把他们分散开, 并且以后新增的值也应该是预知的吧, 那么可以提取分散region,参考这个文档.
https://pingcap.com/docs-cn/stable/reference/best-practices/high-concurrency/#热点产生的实例
递增的号码,是由业务部门控制,对于数据量多少未知,无法做到未来1-2年从业务角度拆分索引
1、如果只想了索引的拆分,有没有那个地方可以看出索引已经拆分,按照什么规则拆分;
2、如果在建表的时候,做索引的拆分,会预先拆分region出来,在建完表以后,表中进去大量数据后,再进行索引拆分,没有感觉,热点索引也没有减少,有没有什么地方可以观测的。
yilong
2020 年4 月 6 日 09:42
14
这些都看过了,我的问题是split 索引后, split TABLE t INDEX idx 后,从哪里可以看到我是否已经做过索引的拆分, 就是索引拆分范围
2、如果通过对于已经拆分的索引( split TABLE t INDEX idx 后),发现效果不佳,如果删除这个split 索引的操作,表比较大,上亿的数据量了