为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】:3.0.12
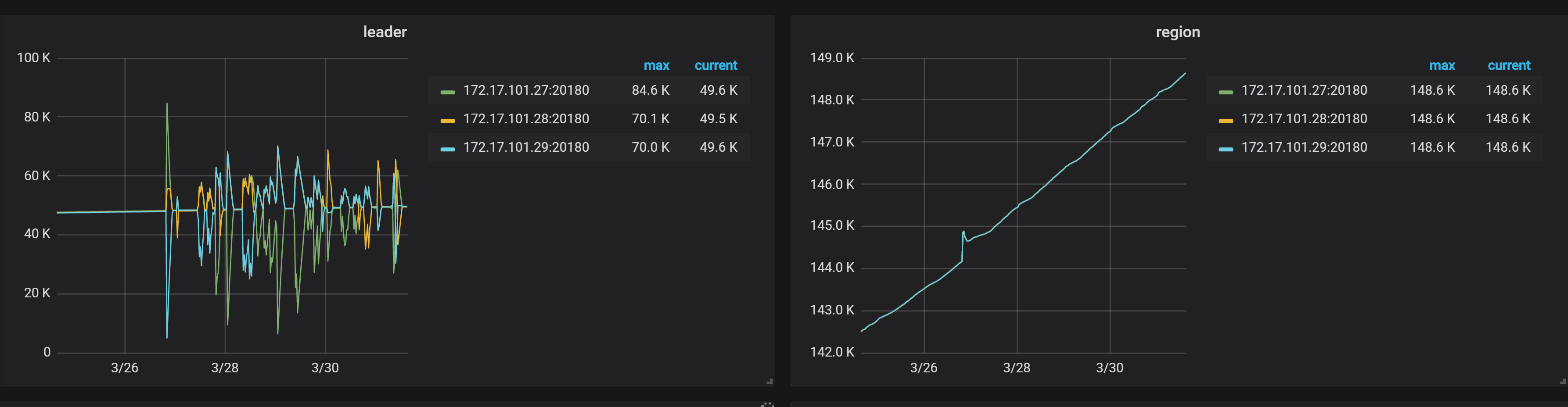
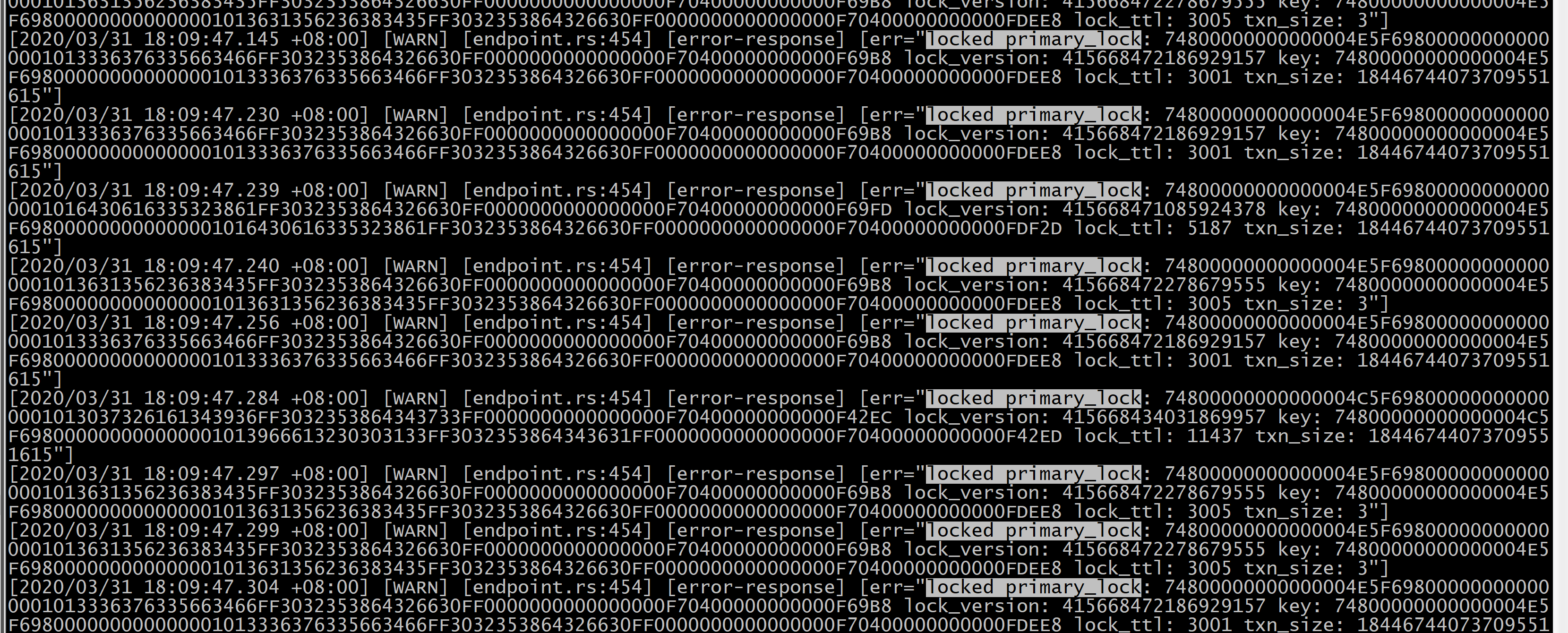
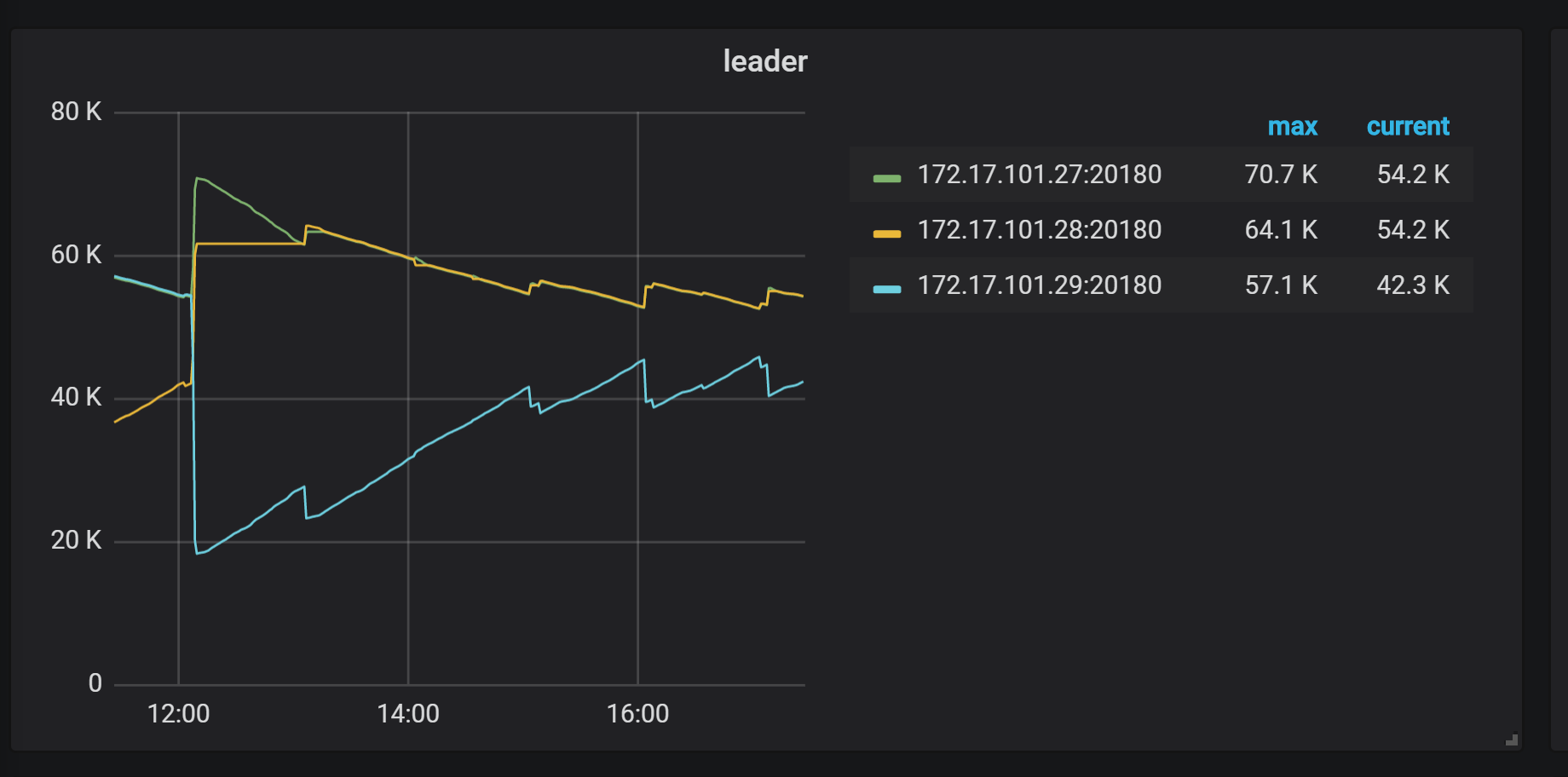
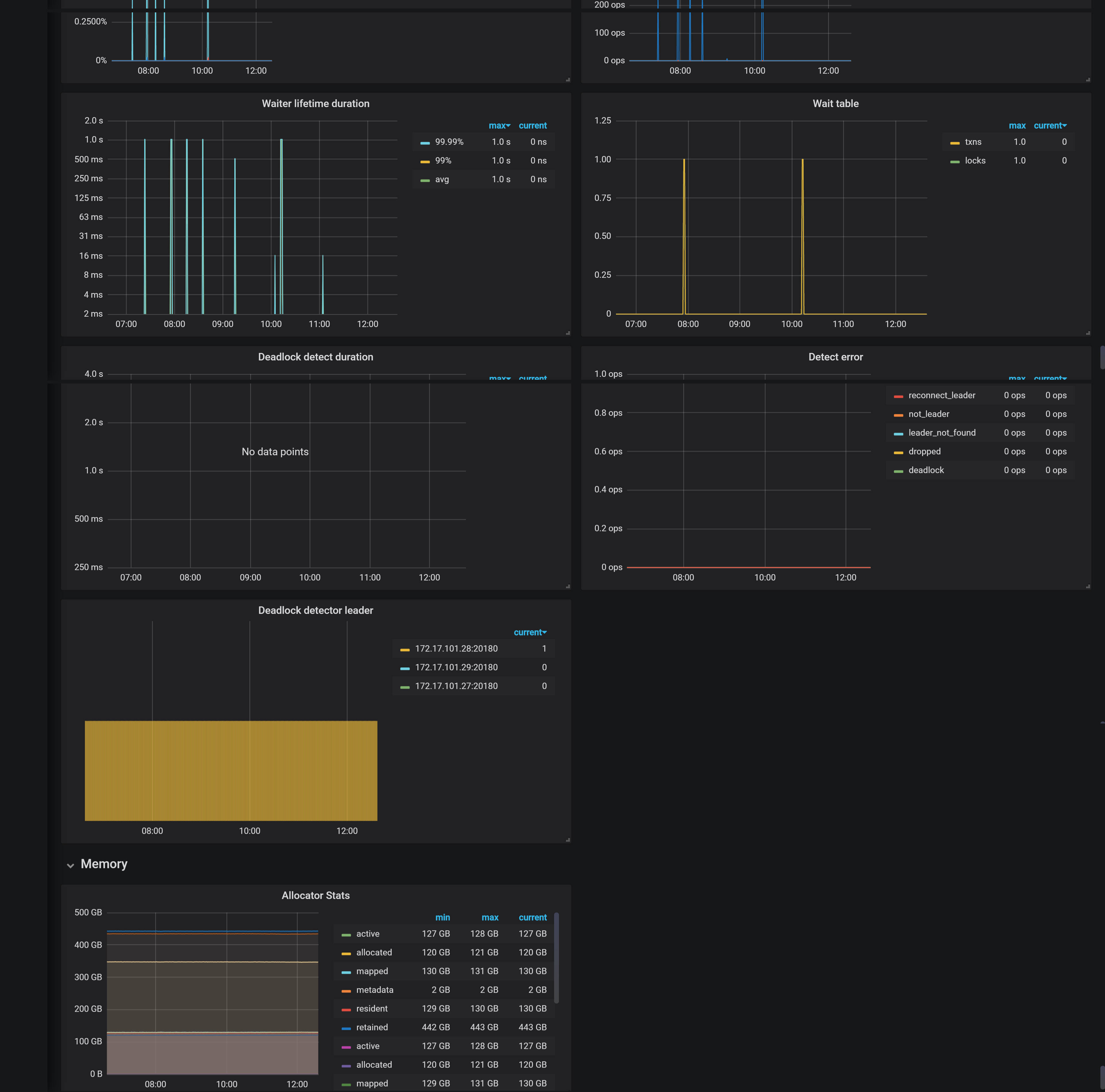
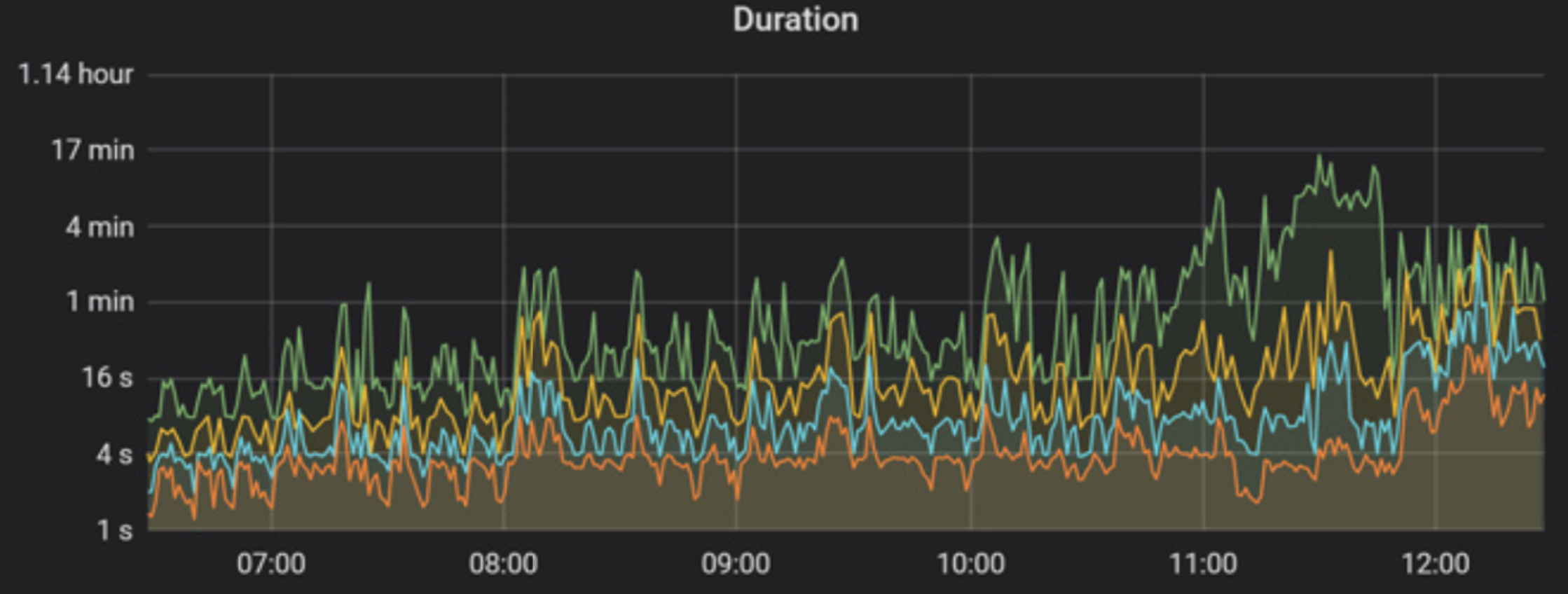
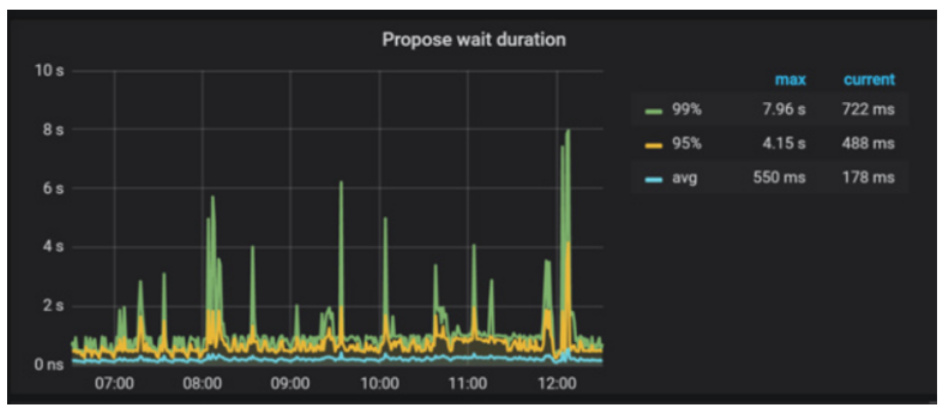
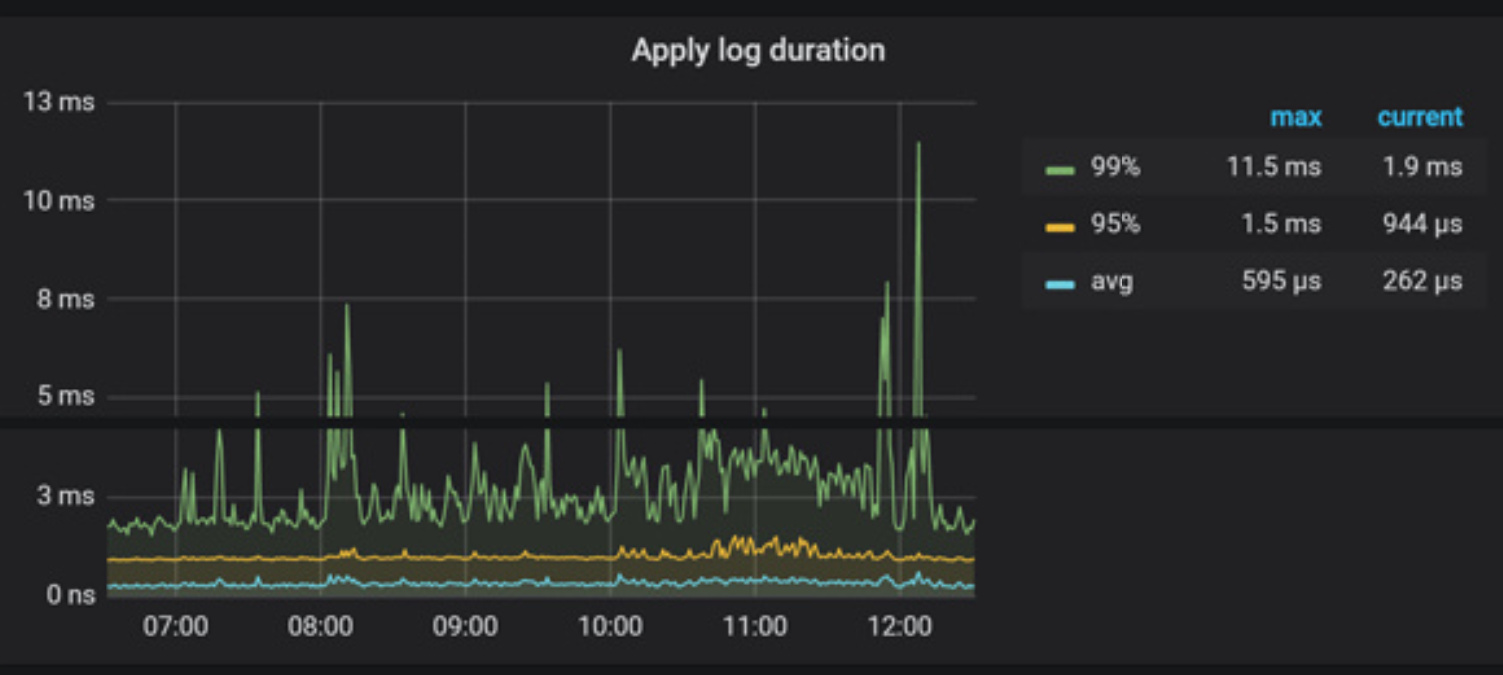
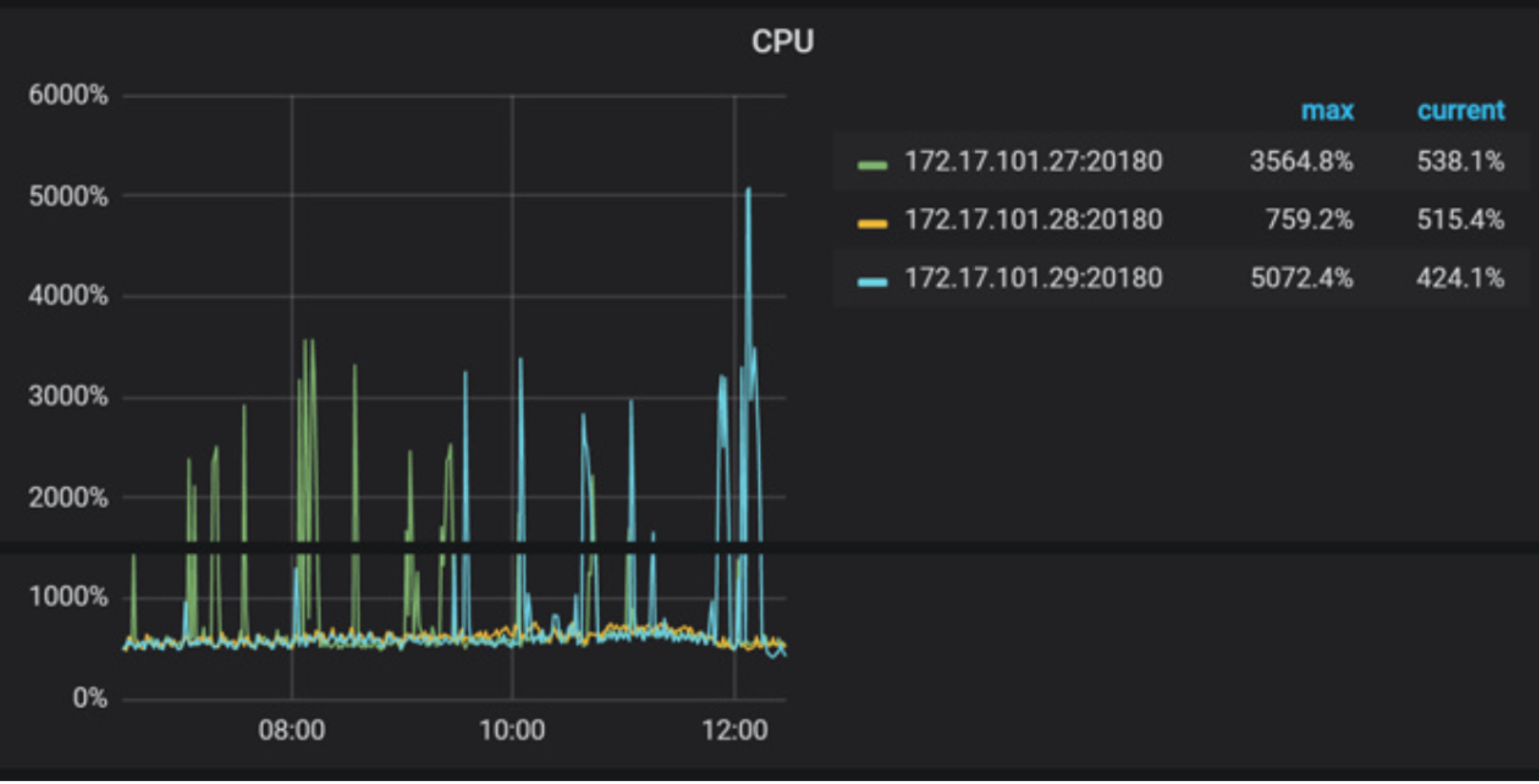
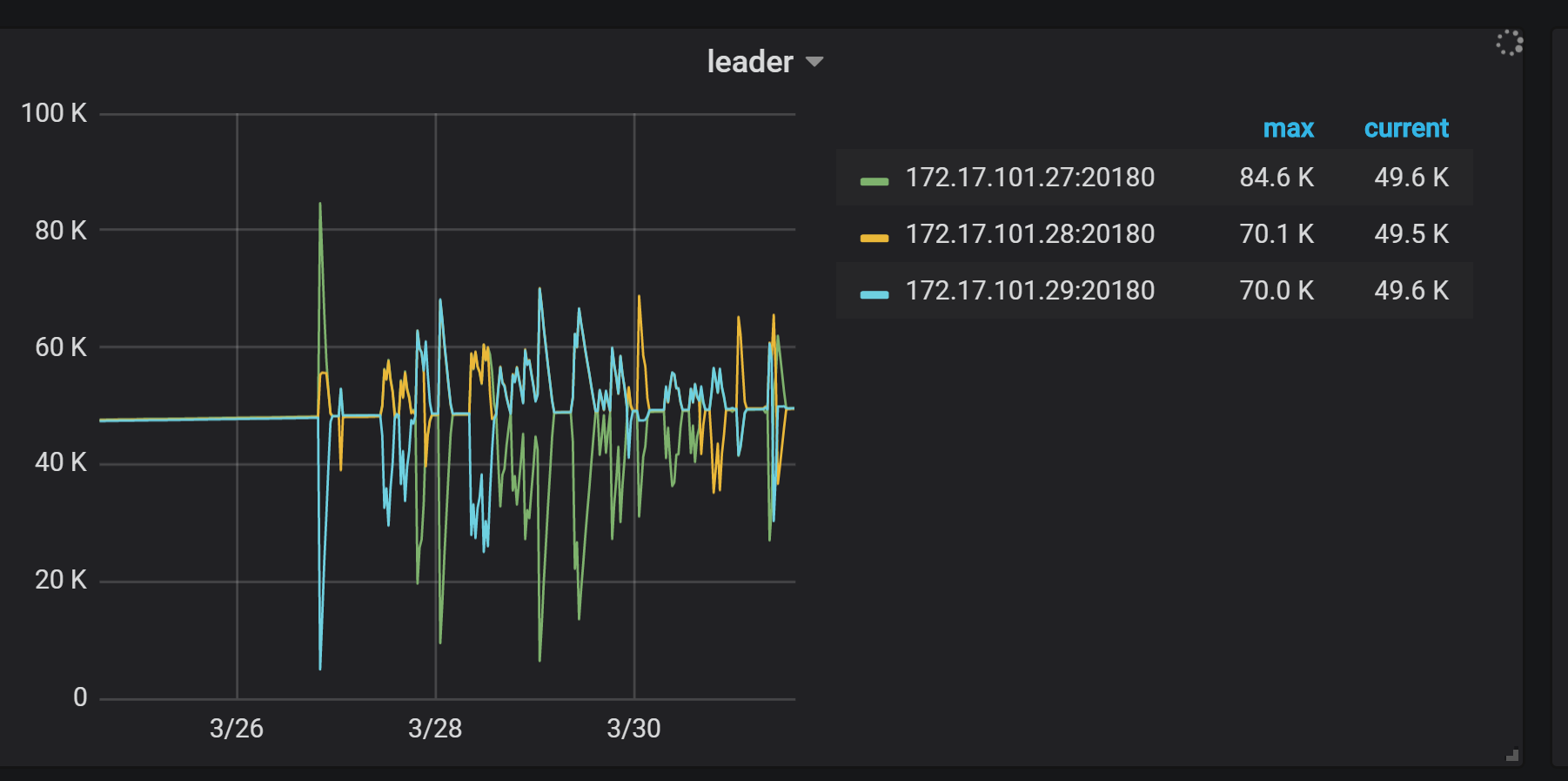
- 【问题描述】: tidb升级3.0.12后,leader数量迁移明显,有大量notleader报错。

{‘tidb_log_dir’: ‘{{ deploy_dir }}/log’, ‘dummy’: None, ‘tidb_port’: 4000, ‘tidb_status_port’: 10080, ‘tidb_cert_dir’: ‘{{ deploy_dir }}/conf/ssl’}
系统信息
+---------------------+-----------------------+
| Host | Release |
+---------------------+-----------------------+
| tidb-online-pd | 3.10.0-862.el7.x86_64 |
| tidb-online-tidb-01 | 3.10.0-862.el7.x86_64 |
| tidb-online-tidb-02 | 3.10.0-862.el7.x86_64 |
| tidb-online-tikv-01 | 3.10.0-862.el7.x86_64 |
| tidb-online-tikv-02 | 3.10.0-862.el7.x86_64 |
| tidb-online-tikv-03 | 3.10.0-862.el7.x86_64 |
| i-1luxw7bi | 3.10.0-862.el7.x86_64 |
| i-dvw3wqe7 | 3.10.0-862.el7.x86_64 |
| i-now7d8gg | 3.10.0-862.el7.x86_64 |
+---------------------+-----------------------+
TiDB 集群信息
+---------------------+--------------+------+----+------+
| TiDB_version | Clu_replicas | TiDB | PD | TiKV |
+---------------------+--------------+------+----+------+
| 5.7.25-TiDB-v3.0.12 | 3 | 3 | 3 | 3 |
+---------------------+--------------+------+----+------+
集群节点信息
+------------+-------------+
| Node_IP | Server_info |
+------------+-------------+
| instance_6 | pd |
| instance_7 | pd |
| instance_0 | tikv |
| instance_1 | tidb |
| instance_2 | tidb |
| instance_3 | tidb |
| instance_8 | pd |
| instance_4 | tikv |
| instance_5 | tikv |
+------------+-------------+
容量 & region 数量
+---------------------+-----------------+--------------+
| Storage_capacity_GB | Storage_uesd_GB | Region_count |
+---------------------+-----------------+--------------+
| 6899.65 | 4231.30 | 445917 |
+---------------------+-----------------+--------------+
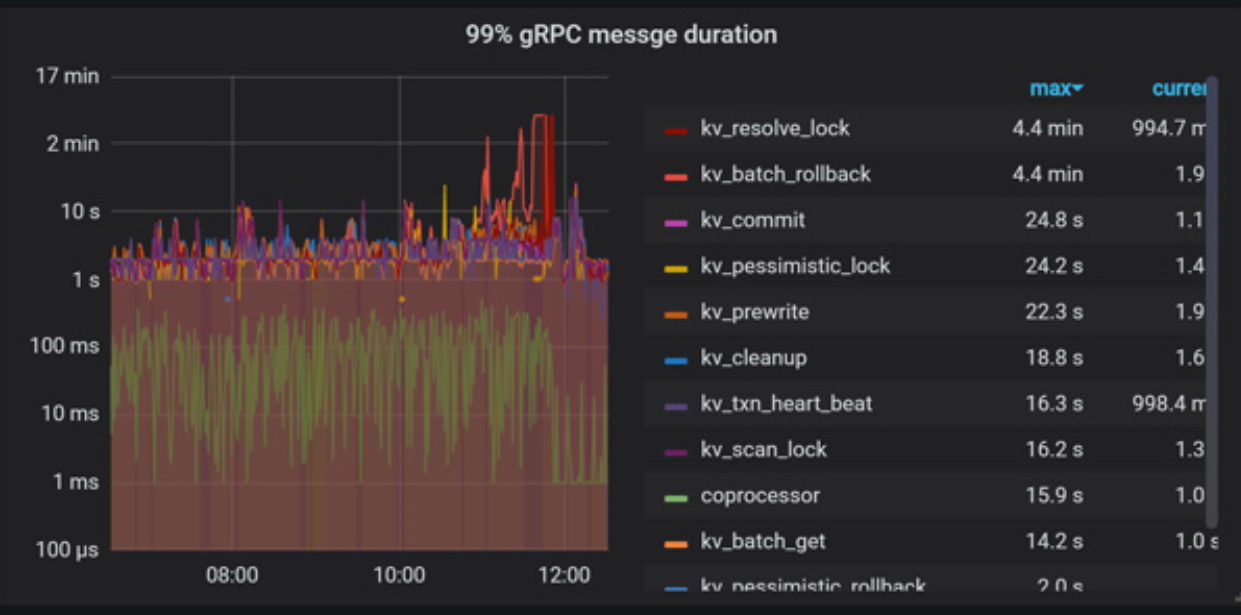
QPS
+---------+----------------+-----------------+
| Clu_QPS | Duration_99_MS | Duration_999_MS |
+---------+----------------+-----------------+
| 338.24 | 47131.31 | 283028.14 |
+---------+----------------+-----------------+
热点 region 信息
+---------+----------+-----------+
| Store | Hot_read | Hot_write |
+---------+----------+-----------+
| store-1 | 0 | 7 |
| store-5 | 0 | 5 |
| store-4 | 0 | 7 |
+---------+----------+-----------+
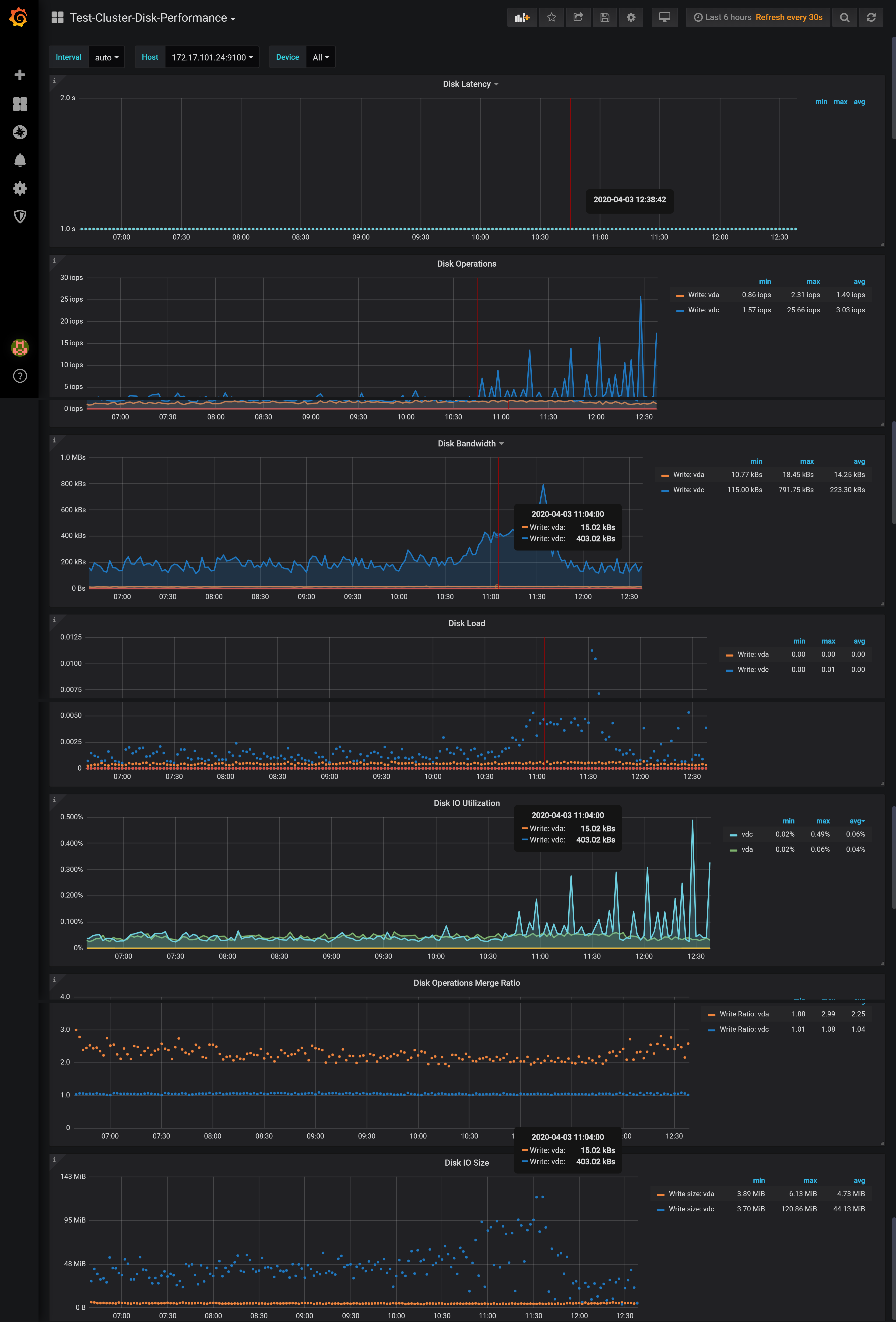
磁盘延迟信息
+--------+------------+-------------+--------------+
| Device | Instance | Read_lat_MS | Write_lat_MS |
+--------+------------+-------------+--------------+
| dm-0 | instance_3 | nan | 1.58 |
| dm-0 | instance_2 | nan | 7.23 |
| dm-0 | instance_1 | nan | nan |
| dm-0 | instance_0 | 0.43 | 0.76 |
| dm-0 | instance_5 | 0.46 | 3.59 |
| dm-0 | instance_4 | 0.97 | 0.64 |
| dm-0 | instance_6 | nan | 0.28 |
| dm-0 | instance_7 | nan | 0.31 |
| dm-0 | instance_8 | nan | 0.40 |
| vda | instance_3 | nan | 0.28 |
| vda | instance_2 | nan | nan |
| vda | instance_1 | nan | nan |
| vda | instance_0 | nan | nan |
| vda | instance_5 | nan | nan |
| vda | instance_4 | nan | nan |
| vda | instance_6 | nan | nan |
| vda | instance_7 | nan | nan |
| vda | instance_8 | nan | nan |
| vdb | instance_3 | nan | nan |
| vdb | instance_2 | nan | nan |
| vdb | instance_1 | nan | nan |
| vdb | instance_0 | nan | nan |
| vdb | instance_5 | nan | nan |
| vdb | instance_4 | nan | nan |
| vdb | instance_6 | nan | nan |
| vdb | instance_7 | nan | nan |
| vdb | instance_8 | nan | nan |
| vdc | instance_3 | nan | 1.58 |
| vdc | instance_2 | nan | nan |
| vdc | instance_1 | nan | nan |
| vdc | instance_0 | 0.39 | 0.13 |
| vdc | instance_5 | 0.36 | 0.13 |
| vdc | instance_4 | 0.39 | 0.20 |
| vdc | instance_6 | nan | 0.26 |
| vdc | instance_7 | nan | 0.29 |
| vdc | instance_8 | nan | 0.42 |
| vdd | instance_2 | nan | 7.23 |
| vdd | instance_0 | 0.30 | 0.19 |
| vdd | instance_5 | 0.34 | 0.19 |
| vdd | instance_4 | 1.35 | 0.14 |
| vde | instance_0 | 0.44 | 0.09 |
| vde | instance_5 | 0.44 | 0.09 |
| vde | instance_4 | 0.86 | 0.22 |
| vdf | instance_0 | 0.39 | 0.19 |
| vdf | instance_5 | 0.36 | 0.19 |
| vdf | instance_4 | 0.99 | 0.10 |
| vdg | instance_0 | 0.52 | 0.64 |
| vdg | instance_5 | 0.58 | 3.64 |
| vdg | instance_4 | 0.94 | 0.49 |
+--------+------------+-------------+--------------+
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。