为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
最近在做一个把 MySql 数仓往 TiDB 迁移的项目,在迁移跑报表的存储过程代码时遇到一个问题,发送代码到 TiDB 的客户端无法和 TiDB 维持长时间的连接,这导致无法判断已经发送(需要运行很长时间)的代码是否已经完成,不知道能否启动下一步的操作。
目前看来和 TiDB 的连接在无交互的情况下最多只能维持 10几分钟,但复杂报表的一些计算环节,耗时半个小时以上甚至几个小时都是正常的。
有什么办法解决么?
对了,命令行的方式我试过添加 --wait --reconnect --connect-timeout=43200 这些参数,
mysql -u user -px xxxxxxxxxxx --host=172.16.150.113 --port=4000 --wait --reconnect --connect-timeout=43200 testdb -e “xxxx”
但没有达到效果。
TiDB 中有 wait_timeout 和 interactive_timeout 参数用于控制空闲连接保持时长
另外可以检查一下 Linux 服务器内核参数中 tcp 超时时间的设置
嗯,TiDB 里的 wait_timeout 和 interactive_timeout 已经看过,是 2880000,应该不至于造成超时断开。
Linux 里的设置我看一下
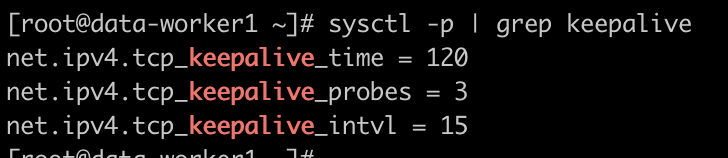
Linux 的 keep alive 设置看起来是这样的,
我看网上有介绍说这代表 120 秒后开始发送第一个 keep alive pocket,以后每隔 15秒发送一次,是这个意思么?
p.s. 客户端和服务器端的 linux 都是这个设置。
可以确认一下 TCP 连接的 keepalive 机制是否开了 sysctl -p | grep keepalive
https://blog.biezhi.me/2017/08/talk-tcp-keepalive.html
嗯,好像经过了 HAProxy,我绕开 HAProxy 直连一下看看。
直连后维持了挺长一段时间,有一个多小时,最后报这个异常退出了
ERROR 1105 (HY000) at line 2: conn1031317 txn takes too much time, txnStartTS: 415641585459134528, comm: 415642879323275302
从报错信息来看,报错的原因是超过《单个事务允许的最大执行时间:590 秒》,参考这里
swrd
(泰石)
13
这个单个事务允许的最大执行时间参数 max-txn-time-use,为什么要加这个限制
超时是常规的设计,防止单个事务长期占用资源不释放、系统资源耗尽导致系统崩溃
swrd
(泰石)
15
我知道数据库有很多超时的设置,像空闲连接超时,空闲事务连接超时,如果是空闲事务超时很好理解,但你这个是单纯的长事务时间长度设置,并不是专指空闲事务,那如果有很长的分析性的sql执行,需要提前调整这个参数是吗?
另外,有一个地方我不太明白,我用下面这样的查询想测一下它究竟能维持多长时间的连接,
mysql -u xxxxxxx -p******* --host=172.16.150.99 --port=4000 --wait --reconnect --connect-timeout=43200 mongo -e "select sleep(18000); – [long_sleep_test] " >> /d1/log/tmp/long_sleep_test.log 2>&1 &
但是它(客户端)挺快就退出了,(没有报错,服务器端仍在跑),可能最多也就 20~30 分钟,比我跑的那个实际的 insert ... select ... 时间短很多。
select sleep(18000); 这个 SQL 有什么特殊吗?
嗯,这个问题只是随口一问。不过我后来又做了尝试,这次跑了2个多小时还没断,看起来不错。
多谢支持!! 
system
(system)
关闭
20
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。