在安装tidb 集群4.0 版本的时候,tikv 主机上面有两个硬盘目录为/data01 /data02,每个盘上部署一个tikv 实例,inventory.ini 配置tikv 如下图:

整个集群部署成功,但是在启动集群的时候tidb 节点hang 住不动,通过查看ansible日志
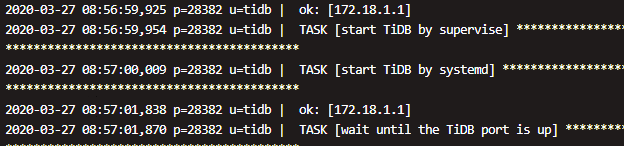
通过去查看tidb主机的日志

这里tidb仍然使用tikv 默认的端口号,tidb 实例起不来,不知是不是在安装时候没有使用默认端口问题,也去
在安装tidb 集群4.0 版本的时候,tikv 主机上面有两个硬盘目录为/data01 /data02,每个盘上部署一个tikv 实例,inventory.ini 配置tikv 如下图:
整个集群部署成功,但是在启动集群的时候tidb 节点hang 住不动,通过查看ansible日志
通过去查看tidb主机的日志
这里tidb仍然使用tikv 默认的端口号,tidb 实例起不来,不知是不是在安装时候没有使用默认端口问题,也去
上面就是tidb的日志,我们想把软件目录和部署的数据目录分开,所以会有上面的配置
麻烦提供一下之前执行的 ansible-playbook 命令步骤以及 {tidb_ansible}/log 目录下的 ansible.log 以及 fail.log 我们确认一下之前步骤执行的结果
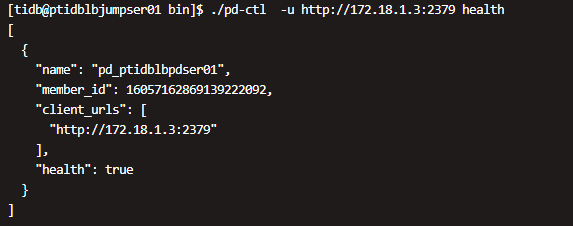
麻烦提供一下完整的 inventory.ini 配置,从 pd 日志中看可能有 label 配置的问题
[2020/03/26 20:05:18.462 +08:00] [WARN] [cluster.go:872] ["not found the key match with the store label"] [store="id:5001 address:\"172.18.1.8:20171\" labels:<key:\"host\" value:\"172.18.1.8\" > version:\"4.0.0-beta.2\" status_address:\"172.18.1.8:20181\" git_hash:\"7908f6e6699239fff23daa444961b5a47ff659da\" start_timestamp:1585224318 binary_path:\"/tidb/tikv1/bin/tikv-server\" "] [label-key=host]
[2020/03/26 20:05:18.463 +08:00] [INFO] [grpc_service.go:233] ["put store ok"] [store="id:5001 address:\"172.18.1.8:20171\" labels:<key:\"host\" value:\"172.18.1.8\" > version:\"4.0.0-beta.2\" status_address:\"172.18.1.8:20181\" git_hash:\"7908f6e6699239fff23daa444961b5a47ff659da\" start_timestamp:1585224318 binary_path:\"/tidb/tikv1/bin/tikv-server\" "]
另外的话,看到 PD 有重启的情况,请问这几个时间点是重启了集群尝试么?
看 tikv 日志中是有重复的节点地址:
[2020/03/27 02:01:01.014 -04:00] [ERROR] [util.rs:355] ["request failed"] [err="Grpc(RpcFailure(RpcStatus { status: RpcStatusCode(2), details: Some(\"duplicated store address: id:7007 address:\\\"172.18.1.9:20171\\\" labels:<key:\\\"host\\\" value:\\\"172.18.1.9\\\" > version:\\\"4.0.0-beta.2\\\" status_address:\\\"172.18.1.9:20181\\\" git_hash:\\\"7908f6e6699239fff23daa444961b5a47ff659da\\\" start_timestamp:1585288861 binary_path:\\\"/data01/tikv1/bin/tikv-server\\\" , already registered by id:5008 address:\\\"172.18.1.9:20171\\\" labels:<key:\\\"host\\\" value:\\\"172.18.1.9\\\" > version:\\\"4.0.0-beta.2\\\" status_address:\\\"172.18.1.9:20181\\\" git_hash:\\\"7908f6e6699239fff23daa444961b5a47ff659da\\\" start_timestamp:1585270452 binary_path:\\\"/tidb/tikv1/bin/tikv-server\\\" last_heartbeat:1585278853703280193 \") }))"]
重新安装的时候有清理 PD 内容吗?
建议按照以下步骤重新安装:
另外看 inventory.ini 中 location_labels 配置前面有空格,可以注意一下格式,去掉这个空格

我前面是和上面安装步骤一样,除了步骤2里面,没有确认所有进程都停掉,那我再试一下,去掉空格部署一遍
[tidb@ptidblbjumpser01 tidb-ansible-4.0.0-beta.2]$ ansible-playbook stop.yml [tidb@ptidblbjumpser01 tidb-ansible-4.0.0-beta.2]$ ansible -i hosts.ini all -m shell -a “ps -ef |grep tidb” -u tidb -b [tidb@ptidblbjumpser01 tidb-ansible-4.0.0-beta.2]$ ansible -i hosts.ini all -m shell -a “rm -rf /home/tidb/.ansible/tmp” -u tidb -b
[tidb@ptidblbjumpser01 tidb-ansible-4.0.0-beta.2]$ ansible -i hosts.ini all -m shell -a “rm -rf /data01/tikv” -u tidb -b [tidb@ptidblbjumpser01 tidb-ansible-4.0.0-beta.2]$ ansible -i hosts.ini all -m shell -a “rm -rf /data02/tikv” -u tidb -b
[tidb@ptidblbjumpser01 tidb-ansible-4.0.0-beta.2]$ ansible -i hosts.ini all -m shell -a “rm -rf /data02/tikv” -u tidb -b
[tidb@ptidblbjumpser01 tidb-ansible-4.0.0-beta.2]$ ansible -i hosts.ini all -m shell -a “ls -l /tidb” -u tidb -b
我又部署了一遍,还是上面的错误,我把 inventory.ini 中 location_labels 配置前面有空格 去掉了
看清理数据的步骤,没有清理 pd 的目录
可以用 ansibe-playbook unsafe_cleanup.yml 一起清理 pd 数据后重新部署
ansible-playbook unsafe_cleanup.yml 这个步骤是有操作的,上面贴的时候忘记贴了。而且很确定,因为每次贴完,都要回车一下,才会执行
ansible-playbook unsafe_cleanup.yml 这个步骤执行完后,确实pd 目录没有清理
可以将 /data/pd 目录清理后重新部署,pd 数据没有清理的话,会包含上次部署的节点信息,所以会有冲突
unsafe_cleanup 没有清理 pd 目录是因为 unsafe_cleanup 操作清理的是 deploy_dir 目录下,因为你单独指定了 pd_data_dir 和 tikv_data_dir 并不包含在 deploy_dir 下,所以没有清理成功。
可以用 unsafe_cleanup_data.yml 操作清理数据目录
有一个问题,是在配置tikv 集群的参数问题,
(1)我的tikv 机器上配置了两个tikv 实例,主机上有两个 1.9T的盘 /data01 /data02 ,在ansible 配置参数的时候 需要修改 tidb-ansible/conf/tikv.yml
raftstore:
capacity: 0
这个参数是要配置成 1.92T嘛 ,还是不用配置
(2) tidb-ansible/conf/tikv.yml 下面是按照公式:TiKV 实例数量 * 参数值 = CPU 核心数量 * 0.8
readpool:
coprocessor:
# Notice: if CPU_NUM > 8, default thread pool size for coprocessors
# will be set to CPU_NUM * 0.8.
# high-concurrency: 8
# normal-concurrency: 8
# low-concurrency: 8
CPU 核心数量 ,这个是cpu的core 的数据量,还是包括超线程 cat /proc/cpuinfo |grep process |wc -l 的值
第一点,如果是多实例部署在同一块磁盘上需要修改,否则不需要,按照默认即可
第二点,4.0 版本中因为引入了 unify-read-pool 线程池替代了 readpool,所以部署 4.0 集群时 readpool.coprocessor 相关参数可以默认