为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】:3.0.12
- 【问题描述】:
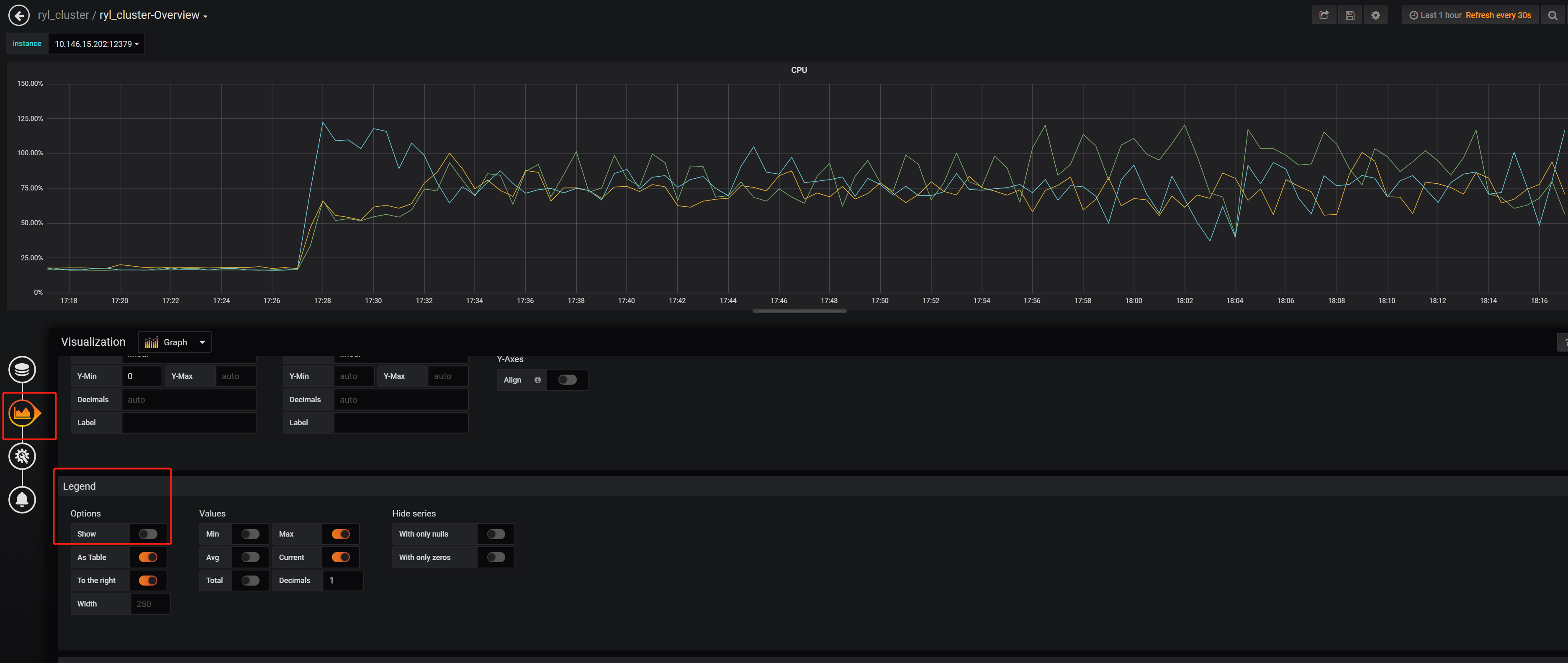
我采用的全新安装3.0.12,安装完了之后导入一批数据,查看监控是这样子的:
这负载是不是有点问题呢,其中一台region特别少,而且leader集中在1台。
为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
不知道您是使用的哪款浏览器,尝试用chrome是否能够正常显示? 在选择监控实例的时候,是否正确,可以调整,再检查edit里是不是关闭了show,打开看下
检查你的机器配置是否一样,每个tikv目录的可用空间是否一致,有没有被其他文件占用
我又重新删除数据开始迁移,这次还是一样,应该不是ie的原因。
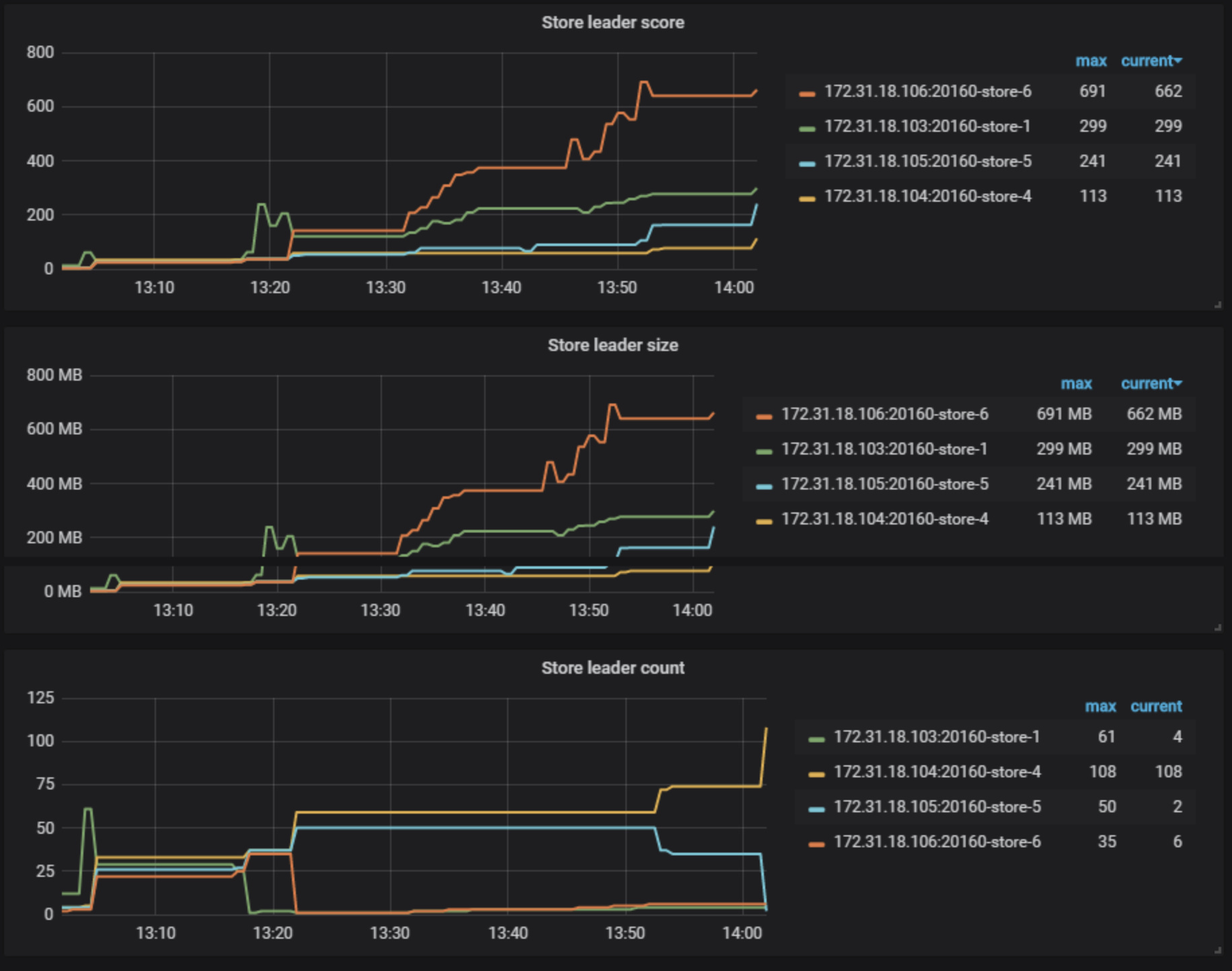
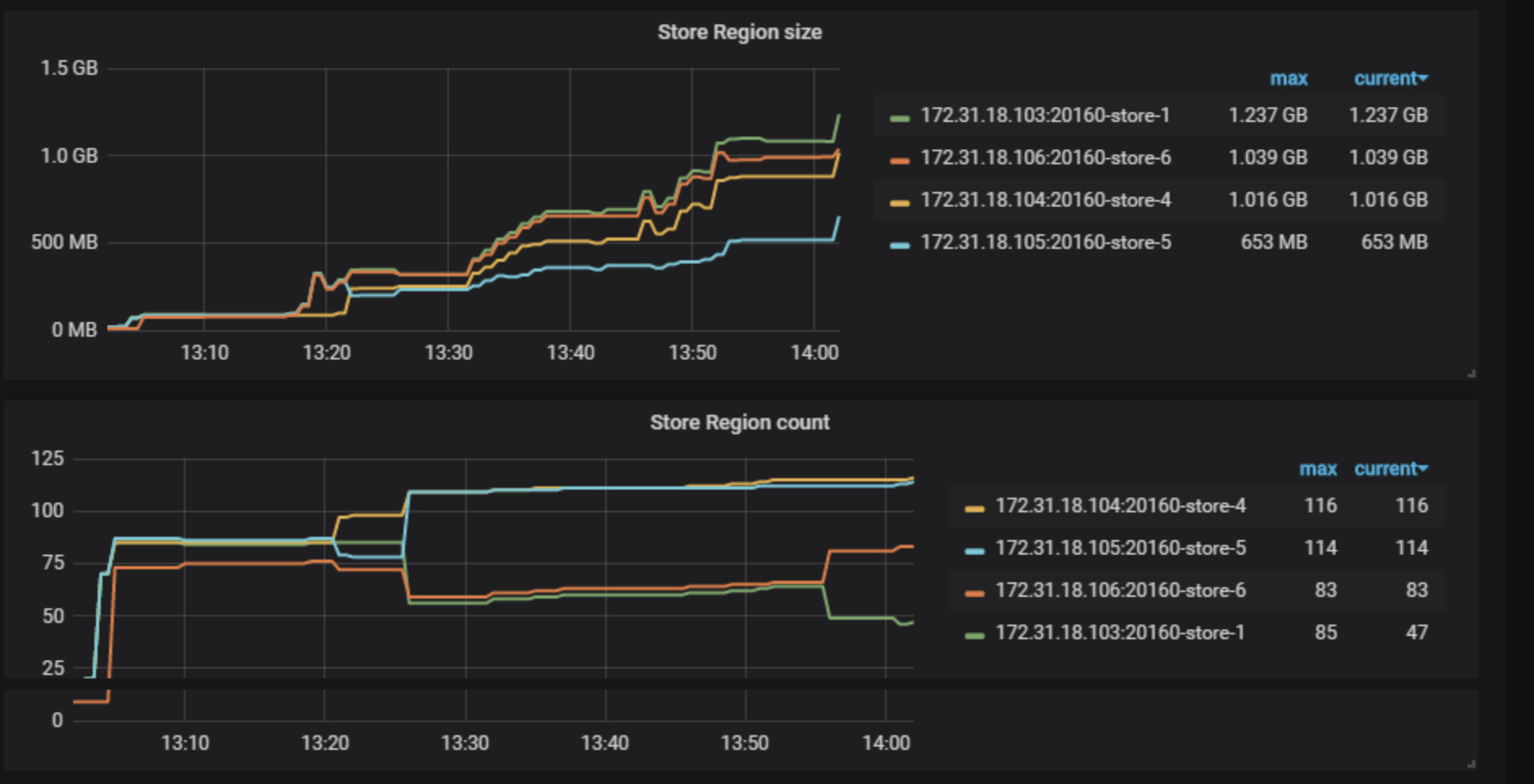
迁移的时候四台服务器leader一致,region数量一致,但是等一会儿开始,差别就比较大了。是ti自己调度的吗。
18:25-18:35在迁移数据
另外 我发现这两个指标异常的高。我在3.0.8做压测也没发现有这么高
我刚刚检查比较低的那台服务器,发现一些日志:
` [2020/03/26 19:22:54.010 +08:00] [INFO] [peer.rs:660] ["failed to schedule peer tick"] [err="sending on a disconnected channel"] [tick=PD_HEARTBEAT] [peer_id=1421] [region_id=324]
[2020/03/26 19:22:54.969 +08:00] [INFO] [peer.rs:660] ["failed to schedule peer tick"] [err="sending on a disconnected channel"] [tick=PD_HEARTBEAT] [peer_id=1450] [region_id=1447]
[2020/03/26 19:22:55.046 +08:00] [INFO] [peer.rs:660] ["failed to schedule peer tick"] [err="sending on a disconnected channel"] [tick=PD_HEARTBEAT] [peer_id=1454] [region_id=1451]
[2020/03/26 19:22:55.111 +08:00] [INFO] [peer.rs:660] ["failed to schedule peer tick"] [err="sending on a disconnected channel"] [tick=PD_HEARTBEAT] [peer_id=1455] [region_id=497]
`
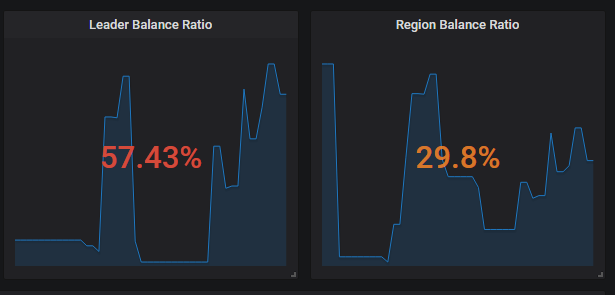
需要看下 pd 面板中的 balance 相关的监控信息来确认下
您好:
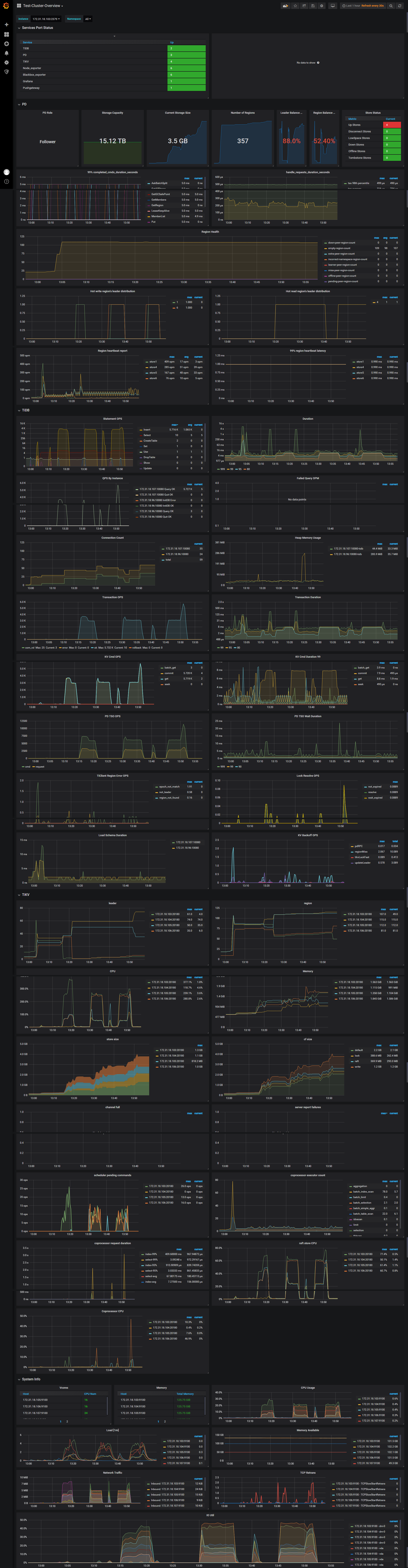
1. 请上传 detail-tikv, overview监控信息
(1)、chrome 安装这个插件https://chrome.google.com/webstore/detail/full-page-screen-capture/fdpohaocaechififmbbbbbknoalclacl
(2)、鼠标焦点置于 Dashboard 上,按 ?可显示所有快捷键,先按 d 再按 E 可将所有 Rows 的 Panels 打开,需等待一段时间待页面加载完成。
(3)、使用这个 full-page-screen-capture 插件进行截屏保存
2. 请使用pd-ctl 执行 store 命令输出信息
3. 从监控看当前总共只有400个region,在数量少的时候,根据您返回的信息我们再确认下。这个是store信息:
[tidb@iZm5eivn9mqkyla2lwxel4Z bin]$ ./pd-ctl store -u http://3.3.3.96:2379
{
"count": 4,
"stores": [
{
"store": {
"id": 1,
"address": "3.3.3.103:20160",
"version": "3.0.12",
"state_name": "Up"
},
"status": {
"capacity": "3.437TiB",
"available": "3.434TiB",
"leader_count": 12,
"leader_weight": 1,
"leader_score": 857,
"leader_size": 857,
"region_count": 54,
"region_weight": 1,
"region_score": 2778,
"region_size": 2778,
"start_ts": "2020-03-25T11:14:42+08:00",
"last_heartbeat_ts": "2020-03-27T10:16:55.095766627+08:00",
"uptime": "47h2m13.095766627s"
}
},
{
"store": {
"id": 4,
"address": "3.3.3.104:20160",
"version": "3.0.12",
"state_name": "Up"
},
"status": {
"capacity": "3.437TiB",
"available": "3.434TiB",
"leader_count": 9,
"leader_weight": 1,
"leader_score": 920,
"leader_size": 920,
"region_count": 289,
"region_weight": 1,
"region_score": 2692,
"region_size": 2692,
"start_ts": "2020-03-25T11:14:42+08:00",
"last_heartbeat_ts": "2020-03-27T10:16:54.897262869+08:00",
"uptime": "47h2m12.897262869s"
}
},
{
"store": {
"id": 5,
"address": "3.3.3.105:20160",
"version": "3.0.12",
"state_name": "Up"
},
"status": {
"capacity": "3.437TiB",
"available": "3.435TiB",
"leader_count": 271,
"leader_weight": 1,
"leader_score": 768,
"leader_size": 768,
"region_count": 304,
"region_weight": 1,
"region_score": 1908,
"region_size": 1908,
"start_ts": "2020-03-25T11:14:42+08:00",
"last_heartbeat_ts": "2020-03-27T10:16:55.020652038+08:00",
"uptime": "47h2m13.020652038s"
}
},
{
"store": {
"id": 6,
"address": "3.3.3.106:20160",
"version": "3.0.12",
"state_name": "Up"
},
"status": {
"capacity": "3.437TiB",
"available": "3.434TiB",
"leader_count": 25,
"leader_weight": 1,
"leader_score": 685,
"leader_size": 685,
"region_count": 304,
"region_weight": 1,
"region_score": 2312,
"region_size": 2312,
"start_ts": "2020-03-25T11:14:42+08:00",
"last_heartbeat_ts": "2020-03-27T10:16:55.975653277+08:00",
"uptime": "47h2m13.975653277s"
}
}
]
}上传了监控了
从监控上看, region score 和 leader score 有差异,但是这个应该是因为 region 和 leader 分布不均衡导致的
从前面的回复看 region 似乎有调度失败的情况
监控部分缺少了 PD->Operator->schdule operator finish 的情况,能手动帮忙截一下么
另外麻烦提供一下 PD Leader 节点的日志以及 105 这台节点的 tikv 日志
另外pd有三个节点 ,都要提供日志吗
leader 节点的日志就可以 pd-ctl 执行 member 可以查看当前 leader 是哪一个节点
在我们跑数据的时候就是均衡的,等我们跑完了 就开始变成有些很高,有些异常低
不过我们只有一张表数据量比较大,其他数据量都不大,很小
会不会是因为有很多空表,我们这次测试导入了很多空表,有数据的就那么几个表