编译好组件,并启动tidb集群运行中,第二天上班发现出现pd,tikv挂断的情况,我想了解一下挂断的原因,通常什么情况会出现single1的错误?是因为内存不足或者其他什么原因?
- 自己编译的组件,不知道是否正确.
- 可以检查目录下的tidb.log和tikv.log信息
- single1只有这个看不出来信息.
- 请安装标准的步骤安装软件,多谢.
具体的日志信息,在我的旧帖里有发,我也问了,但是工作人员回到后面就没回消息了,所以才重新开个贴看看,关于tidb在arm上部署 。前面是问的编译,最后问的这个问题
编译的组件,应该是正确的,现在也比较稳定,对接到环境之后各个功能也是正常,没出现挂断的情况了,但是我想了解之前挂断的原因
目录下的log信息,只是说了因为tikv收到了single1才关闭,并没有说明是什么原因
这是tidb部分的日志
[client_batch.go:324] [“batchRecvLoop fails when receiving, needs to reconnect”] [error=“rpc error: code = Internal desc = stream terminated by RST_STREAM with error code: INTERNAL_ERROR”]
这是tikv的日志,查看日志好像是kv先挂的,但是不知道是什么原因
[2020/03/24 09:06:38.969 +08:00] [INFO] [signal_handler.rs:21] [“receive signal 1, stopping server…”]
[2020/03/24 09:06:38.969 +08:00] [INFO] [mod.rs:374] [“stoping worker”] [worker=snap-handler]
[2020/03/24 09:06:38.972 +08:00] [ERROR] [kv.rs:732] [“KvService::batch_raft send response fail”] [err=RemoteStopped]
- tidb部分stream terminated by RST_STREAM with error code: INTERNAL_ERROR看起来是grpc的报错
- tikv部分receive signal 1, stopping server, 我感觉可能是操作系统层面的错误,建议查一下/var/log/message日志,看看是否有OOM或者其他报错,可能把tikv进程kill了。
messages里好像这里有点问题,显示和本地断开连接,但是我早上并没有做连接或断开的操作
Mar 24 09:06:38 host-10-33-4-24 sshd[18250]: Connection closed by 10.32.6.18 port 62505
Mar 24 09:06:38 host-10-33-4-2 sshd[18250]: Close session: user root from 10.32.6.18 port 62505 id 0
Mar 24 09:06:38 host-10-33-4-2 sshd[18250]: Transferred: sent 47472, received 52984 bytes Mar 24 09:06:38 host-10-33-4-2 sshd[18250]: Closing connection to 10.32.6.18 port 62505
Mar 24 09:06:38 host-10-33-4-2 systemd-logind[3822]: Session 195 logged out. Waiting for processes to exit.
Mar 24 09:06:38 host-10-33-4-2 systemd-logind[3822]: Removed session 195.
您这边能看出messages这显示的是什么回事吗?多谢
从日志中无法判断出具体原因
- 看 TiDB 监控的话,tikv pd 异常挂掉之前集群有什么现象吗?
- pd 挂掉,有 pd 相关的日志可以看么
- 挂掉之前,有没有做一些操作,可以通过慢日志看到当时时刻点有没有一些异常的 SQL 情况
这是tidb的日志,您这边可以帮忙看下,多谢了。。。没有生成慢日志
[2020/03/24 09:02:37.900 +08:00] [INFO] [gc_worker.go:274] ["[gc worker] starts the whole job"] [uuid=5c41d85b5400004] [safePoint=415501164953468928] [concurrency=3]
[2020/03/24 09:02:37.900 +08:00] [INFO] [gc_worker.go:771] ["[gc worker] start resolve locks"] [uuid=5c41d85b5400004] [safePoint=415501164953468928] [concurrency=3]
[2020/03/24 09:02:37.900 +08:00] [INFO] [range_task.go:90] [“range task started”] [name=resolve-locks-runner] [startKey=] [endKey=] [concurrency=3]
[2020/03/24 09:02:37.904 +08:00] [INFO] [range_task.go:199] [“range task finished”] [name=resolve-locks-runner] [startKey=] [endKey=] [“cost time”=4.110806ms] [“completed regions”=21]
[2020/03/24 09:02:37.904 +08:00] [INFO] [gc_worker.go:792] ["[gc worker] finish resolve locks"] [uuid=5c41d85b5400004] [safePoint=415501164953468928] [regions=21]
[2020/03/24 09:03:37.869 +08:00] [INFO] [gc_worker.go:243] ["[gc worker] there’s already a gc job running, skipped"] [“leaderTick on”=5c41d85b5400004]
[2020/03/24 09:04:17.910 +08:00] [INFO] [gc_worker.go:580] ["[gc worker] start delete"] [uuid=5c41d85b5400004] [ranges=0]
[2020/03/24 09:04:17.910 +08:00] [INFO] [gc_worker.go:599] ["[gc worker] finish delete ranges"] [uuid=5c41d85b5400004] [“num of ranges”=0] [“cost time”=560ns]
[2020/03/24 09:04:17.911 +08:00] [INFO] [gc_worker.go:622] ["[gc worker] start redo-delete ranges"] [uuid=5c41d85b5400004] [“num of ranges”=0]
[2020/03/24 09:04:17.911 +08:00] [INFO] [gc_worker.go:641] ["[gc worker] finish redo-delete ranges"] [uuid=5c41d85b5400004] [“num of ranges”=0] [“cost time”=620ns]
[2020/03/24 09:04:17.915 +08:00] [INFO] [gc_worker.go:928] ["[gc worker] sent safe point to PD"] [uuid=5c41d85b5400004] [“safe point”=415501164953468928]
[2020/03/24 09:06:38.971 +08:00] [INFO] [client_batch.go:324] [“batchRecvLoop fails when receiving, needs to reconnect”] [target=10.33.11.82:20160] [error=“rpc error: code = Internal desc = stream terminated by RST_STREAM with error code: INTERNAL_ERROR”]
[2020/03/24 09:06:38.971 +08:00] [INFO] [client_batch.go:324] [“batchRecvLoop fails when receiving, needs to reconnect”] [target=10.33.11.82:20160] [error=“rpc error: code = Internal desc = stream terminated by RST_STREAM with error code: INTERNAL_ERROR”]
[2020/03/24 09:06:38.971 +08:00] [INFO] [client_batch.go:324] [“batchRecvLoop fails when receiving, needs to reconnect”] [target=10.33.11.82:20160] [error=“rpc error: code = Internal desc = stream terminated by RST_STREAM with error code: INTERNAL_ERROR”]
[2020/03/24 09:06:38.971 +08:00] [INFO] [client_batch.go:290] [“batchRecvLoop re-create streaming success”] [target=10.33.11.82:20160]
[2020/03/24 09:06:38.971 +08:00] [INFO] [client_batch.go:324] [“batchRecvLoop fails when receiving, needs to reconnect”] [target=10.33.11.82:20160] [error=“rpc error: code = Internal desc = stream terminated by RST_STREAM with error code: INTERNAL_ERROR”]
[2020/03/24 09:06:38.971 +08:00] [INFO] [client_batch.go:324] [“batchRecvLoop fails when receiving, needs to reconnect”] [target=10.33.11.82:20160] [error=“rpc error: code = Internal desc = stream terminated by RST_STREAM with error code: INTERNAL_ERROR”]
[2020/03/24 09:06:38.971 +08:00] [INFO] [client_batch.go:324] [“batchRecvLoop fails when receiving, needs to reconnect”] [target=10.33.11.82:20160] [error=“rpc error: code = Internal desc = stream terminated by RST_STREAM with error code: INTERNAL_ERROR”]
[2020/03/24 09:06:38.971 +08:00] [INFO] [client_batch.go:324] [“batchRecvLoop fails when receiving, needs to reconnect”] [target=10.33.11.82:20160] [error=“rpc error: code = Internal desc = stream terminated by RST_STREAM with error code: INTERNAL_ERROR”]
[2020/03/24 09:06:38.971 +08:00] [INFO] [client_batch.go:324] [“batchRecvLoop fails when receiving, needs to reconnect”] [target=10.33.11.82:20160] [error=“rpc error: code = Internal desc = stream terminated by RST_STREAM with error code: INTERNAL_ERROR”]
[2020/03/24 09:06:38.971 +08:00] [INFO] [client_batch.go:324] [“batchRecvLoop fails when receiving, needs to reconnect”] [target=10.33.11.82:20160] [error=“rpc error: code = Internal desc = stream terminated by RST_STREAM with error code: INTERNAL_ERROR”]
[2020/03/24 09:06:38.971 +08:00] [INFO] [client_batch.go:324] [“batchRecvLoop fails when receiving, needs to reconnect”] [target=10.33.11.82:20160] [error=“rpc error: code = Internal desc = stream terminated by RST_STREAM with error code: INTERNAL_ERROR”]
[2020/03/24 09:06:38.971 +08:00] [INFO] [client_batch.go:324] [“batchRecvLoop fails when receiving, needs to reconnect”] [target=10.33.11.82:20160] [error=“rpc error: code = Internal desc = stream terminated by RST_STREAM with error code: INTERNAL_ERROR”]
[2020/03/24 09:06:38.971 +08:00] [INFO] [client_batch.go:290] [“batchRecvLoop re-create streaming success”] [target=10.33.11.82:20160]
[2020/03/24 09:06:38.971 +08:00] [INFO] [client_batch.go:324] [“batchRecvLoop fails when receiving, needs to reconnect”] [target=10.33.11.82:20160] [error=“rpc error: code = Unavailable desc = transport is closing”]
[2020/03/24 09:06:38.971 +08:00] [INFO] [client_batch.go:324] [“batchRecvLoop fails when receiving, needs to reconnect”] [target=10.33.11.82:20160] [error=“rpc error: code = Unavailable desc = transport is closing”]
[2020/03/24 09:06:38.971 +08:00] [INFO] [client_batch.go:324] [“batchRecvLoop fails when receiving, needs to reconnect”] [target=10.33.11.82:20160] [error=“rpc error: code = Internal desc = stream terminated by RST_STREAM with error code: INTERNAL_ERROR”]
[2020/03/24 09:06:38.971 +08:00] [INFO] [client_batch.go:324] [“batchRecvLoop fails when receiving, needs to reconnect”] [target=10.33.11.82:20160] [error=“rpc error: code = Internal desc = stream terminated by RST_STREAM with error code: INTERNAL_ERROR”]
[2020/03/24 09:06:38.971 +08:00] [INFO] [client_batch.go:324] [“batchRecvLoop fails when receiving, needs to reconnect”] [target=10.33.11.82:20160] [error=“rpc error: code = Internal desc = stream terminated by RST_STREAM with error code: INTERNAL_ERROR”]
- tidb.log 中的日志信息应该是由于 tikv 挂掉引起的,是结果
- tikv.log 中提示节点是 receive signal 1 信号停止进程的,Linux 中信号量 1 表示终端挂起或者控制进程终止,确认一下你是以什么方式启动 tikv 的?systemd 还是 supervise ?
- 部署集群是通过 tidb-ansible 进行部署的吗?
我是使用脚本命令方式启动的
nohup ${G_TIDB_BINARY_DIR}/tikv-server --pd="${KV_PDS}" --addr="${TIDB_LOCALHOST}:${KV_PORT}" --data-dir=${G_TIDB_DATA_DIR}/${KV_NAME} --log-file=${G_TIDB_LOG_DIR}/tikv.log &
部署集群并没有通过tidb-ansible
之前也尝试过部署tidb-ansible,不过因为某些原因放弃使用了
这个挂断的问题就上次出现了一次,我重新部署增加PD节点之后就没有出现过了,但是因为领导重视挂断的这种情况,所以我想要了解一下产生这种情况的原因
[2020/03/24 08:34:17.908 +08:00] [INFO] [grpc_service.go:713] [“updated gc safe point”] [safe-point=415500693094268928]
[2020/03/24 08:44:17.914 +08:00] [INFO] [grpc_service.go:713] [“updated gc safe point”] [safe-point=415500850393776128]
[2020/03/24 08:54:17.917 +08:00] [INFO] [grpc_service.go:713] [“updated gc safe point”] [safe-point=415501007680176128]
[2020/03/24 09:04:17.914 +08:00] [INFO] [grpc_service.go:713] [“updated gc safe point”] [safe-point=415501164953468928]
[2020/03/24 09:06:38.974 +08:00] [INFO] [main.go:121] [“Got signal to exit”] [signal=hangup]
[2020/03/24 09:06:38.974 +08:00] [INFO] [server.go:266] [“closing server”]
[2020/03/24 09:06:38.974 +08:00] [INFO] [leader.go:164] [“server is closed, exit etcd leader loop”]
[2020/03/24 09:06:38.974 +08:00] [INFO] [server.go:346] [“server is closed, exit metrics loop”]
[2020/03/24 09:06:38.974 +08:00] [INFO] [leader.go:309] [“server is closed”]
[2020/03/24 09:06:38.974 +08:00] [INFO] [coordinator.go:443] [“scheduler has been stopped”] [scheduler-name=label-scheduler] [error=“context canceled”]
[2020/03/24 09:06:38.974 +08:00] [INFO] [coordinator.go:146] [“drive push operator has been stopped”]
[2020/03/24 09:06:38.974 +08:00] [INFO] [coordinator.go:103] [“patrol regions has been stopped”]
[2020/03/24 09:06:38.974 +08:00] [INFO] [coordinator.go:443] [“scheduler has been stopped”] [scheduler-name=balance-region-scheduler] [error=“context canceled”]
[2020/03/24 09:06:38.974 +08:00] [INFO] [coordinator.go:443] [“scheduler has been stopped”] [scheduler-name=balance-leader-scheduler] [error=“context canceled”]
[2020/03/24 09:06:38.974 +08:00] [INFO] [cluster.go:677] [“background jobs has been stopped”]
[2020/03/24 09:06:38.974 +08:00] [INFO] [coordinator.go:443] [“scheduler has been stopped”] [scheduler-name=balance-hot-region-scheduler] [error=“context canceled”]
[2020/03/24 09:06:38.974 +08:00] [INFO] [server.go:103] [“region syncer has been stopped”]
[2020/03/24 09:06:38.974 +08:00] [INFO] [cluster.go:170] [“coordinator is stopping”]
[2020/03/24 09:06:38.974 +08:00] [INFO] [cluster.go:166] [“coordinator has been stopped”]
[2020/03/24 09:06:38.974 +08:00] [INFO] [leader.go:223] [“exit campaign leader”]
[2020/03/24 09:06:38.975 +08:00] [INFO] [leader.go:82] [“server is closed, return leader loop”]
之前听 rongyilong-PingCAP这位分析说,是grpc报的错,我看日志里pd stop之前,grpc有在更新什么,这个会导致kv和pd挂吗
正常运行的时候 TiDB 与 TiKV 通信都是通过 rpc 方式通信的,如果 tikv 挂掉,那可能会通信报错。
tikv pd 异常挂掉的原因可能与 nohup 挂载方式有关
nohup 启动进程,终端异常退出
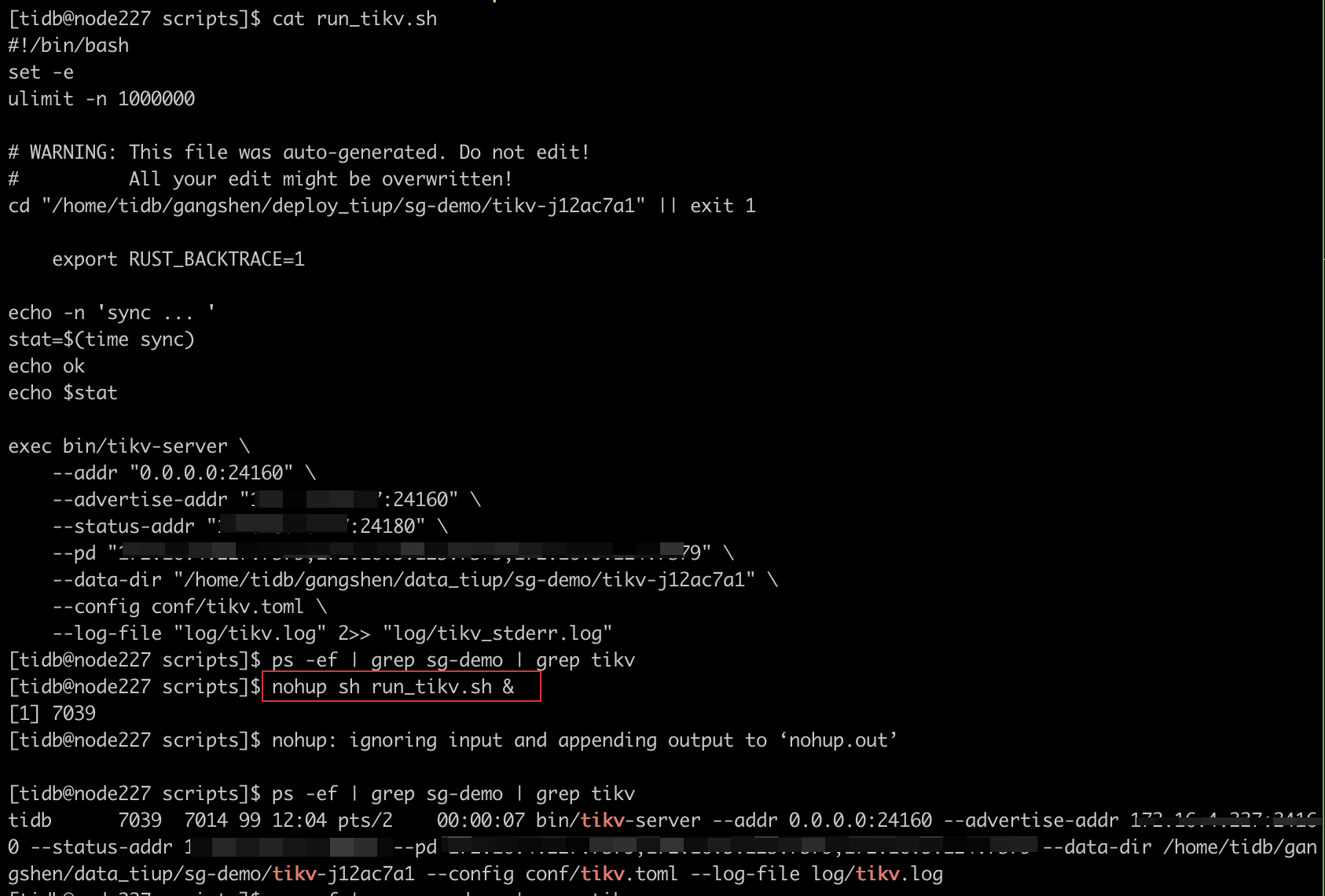
- 通过 nohup 方式启动进程,查看进程正常启动
- 直接关闭终端
- 查看 /var/log/message 日志
- 重新登陆机器并查看 tikv 进程,发现 tikv 进程退出


nohup 启动进程,终端 exit 退出
- 通过 nohup 方式启动进程,查看进程正常启动
- exit 方式退出终端
- 查看 /var/log/messages,没有 remove session 的信息
- 重新登陆机器并检查进程,进程正常存在




另外在终端异常退出时会发送 SIGHUP 的信号,这应该就是 tikv 日志中打印 receive signal 1,stopping server 信息的原因。可以考虑使用 systemd 的方式启动进程或者在 nohup 挂载进程之后,通过 setsid 命令将父进程切换到主进程 1 上。
好的,多谢您,我听懂了您大概的意思,是指因为终端异常退出,导致tikv挂断,这也验证我之前的猜测。十分感谢![]()
不客气,后续如果有其他问题,可以及时反馈
您好,之前的集群1tidb,1pd,3tikv的时候终端异常关闭,的确有时候pd和tikv会挂断,但是昨天我在我新部署的1tidb,3pd,3tikv集群下按照您的步骤操作了一遍,两种情况下,集群都是正常的,并没有产生挂断的情况,并且我在网上查询了一些信息,也表示nohup和&配合来启动程序: 可以同时免疫SIGINT和SIGHUP信号
您这边可以看一下 https://www.jb51.net/article/166305.htm
https://my.oschina.net/moooofly/blog/489521
所以想请教一下是否并不是因为nohup启动的原因,而是有其他原因导致kv异常挂断?
从 tikv 日志看到是 receive signal 1 信号停止进程,这个一般都是操作系统层面导致的,所以建议用 systemd 方式启动进程,这样当进程异常退出的时候,也会被尝试重新拉起进程。
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。