为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】:v3.1.0-beta.2
- 【问题描述】:tidb写入延时比较高,看起来是由于binlog导致的,有没有办法避免这个问题。
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出打印结果,请务必全选并复制粘贴上传。
为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
刚看了看配置文件,binlog没有开![]()
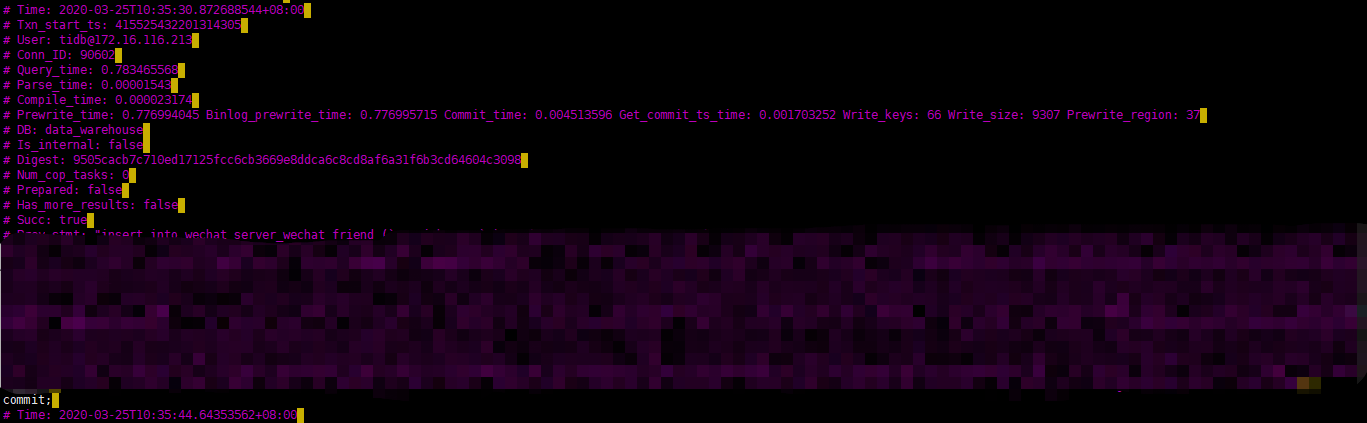
抱歉,binlog_prewrite_time 在没有开启 binlog 还是会打印的问题,是已知的问题。在后续版本会 Fix 掉。另外slowlog 麻烦确认一下以下几个方面:
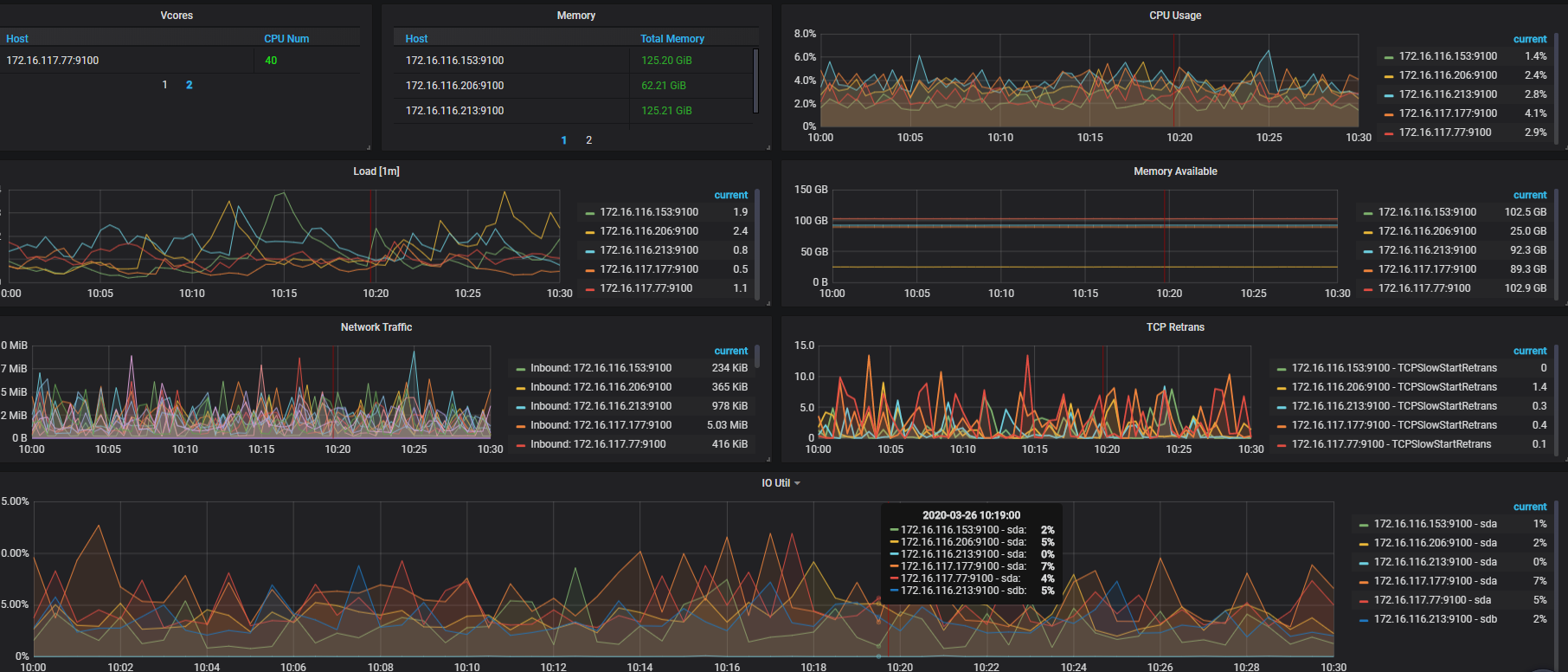
那有可能是某一时间段的 duration 较高,集群 TiKV 的机器磁盘 IO wait 是否也出现波动,另外,在 slowlog 出现的方便的话麻烦挑选一个 insert 慢日志较多的时间段(30 min 即可),导出一下具体的监控用作进一步分析。导出方法:
1)使用 chrome 浏览器,安装Full Page Screen Capture插件。
2)展开grafana 监控的 “cluster-name-overview” 的所有 dashboard (先按 d 再按 E 可将所有 Rows 的 Panels 打开,需等待一段时间待页面加载完成)
3)使用插件导出 pdf
screencapture-172-16-116-213-3000-d-eDbRZpnWk-tidb-cluster-overview-2020-03-25-16_32_50.rar (4.1 MB)
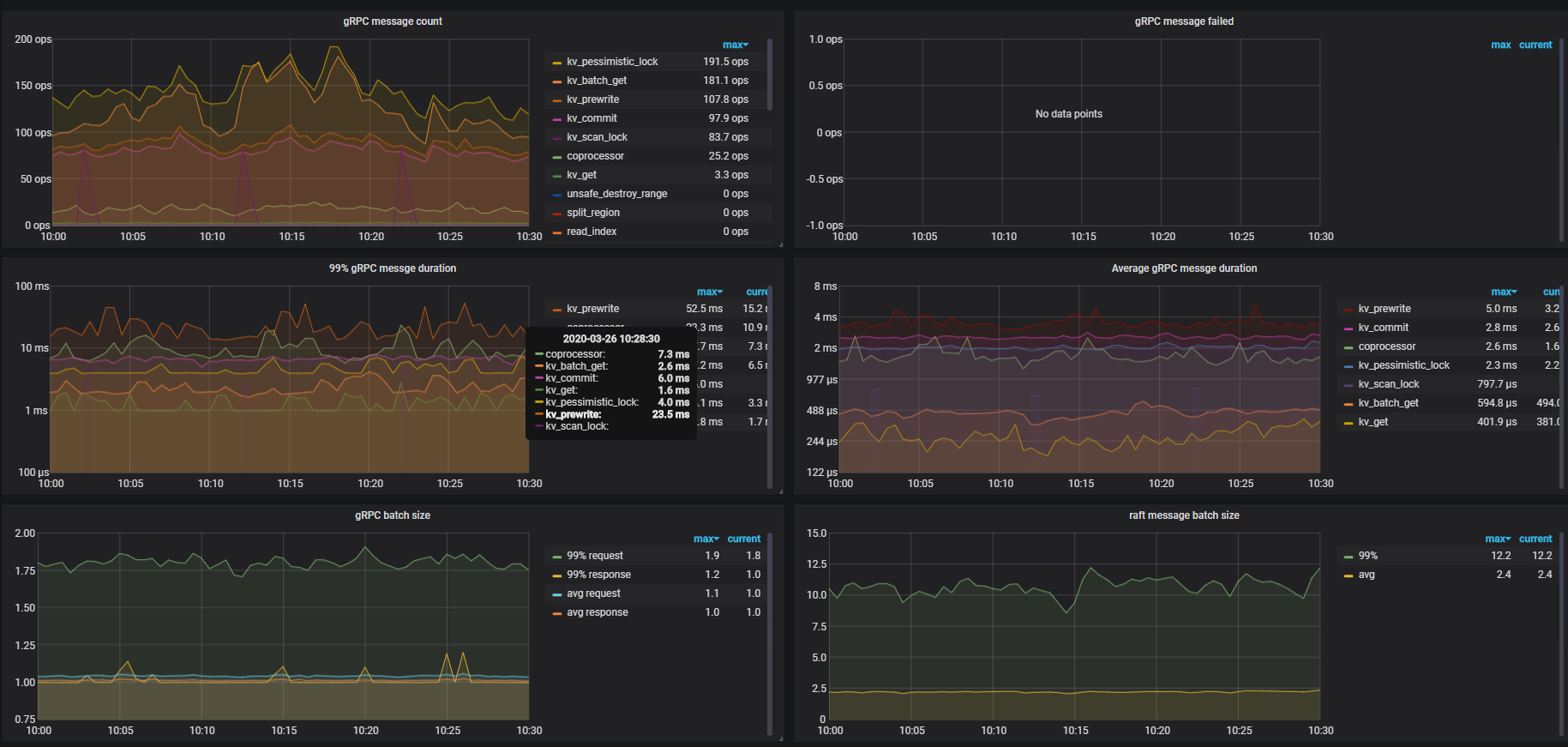
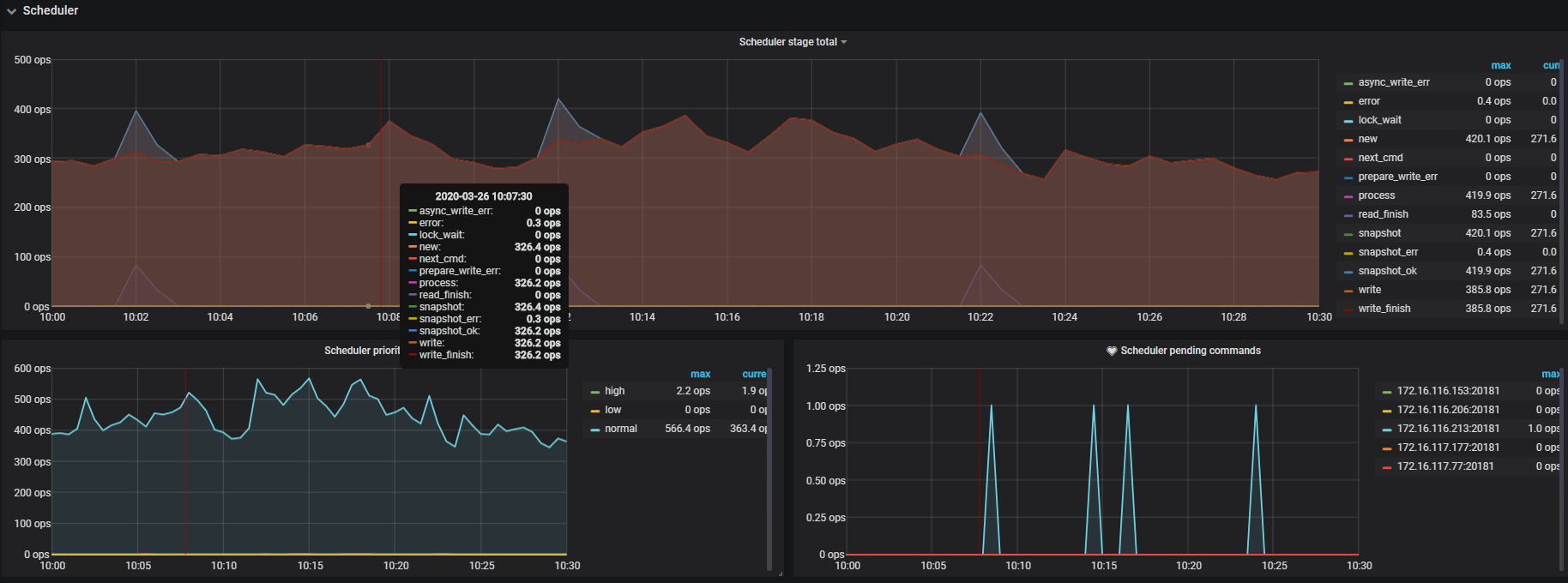
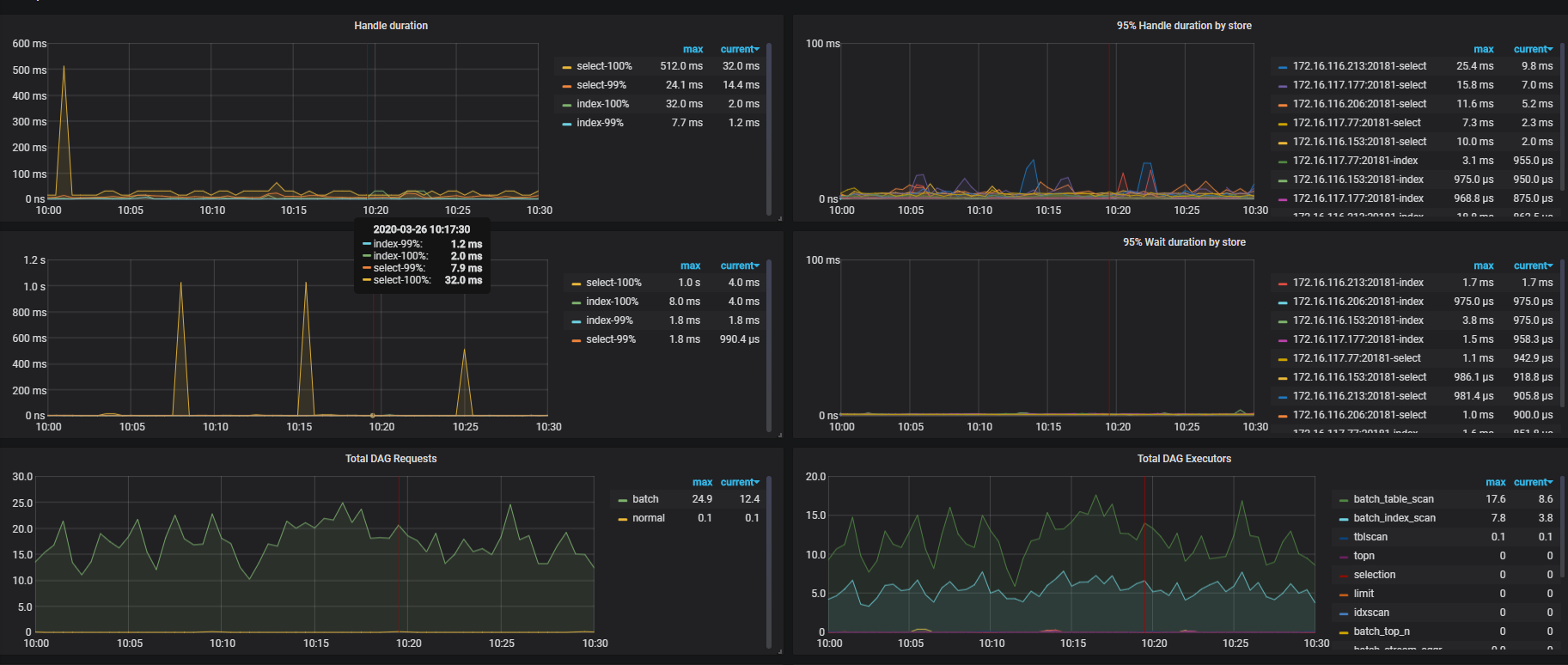
pt-query-digest --since --until 汇总一下看看)可以在 tikv-detail 的监控面板中,查下 scheduler , grpc , coprocessor 相关的监控,来辅助定位当时 duration 升高的原因。
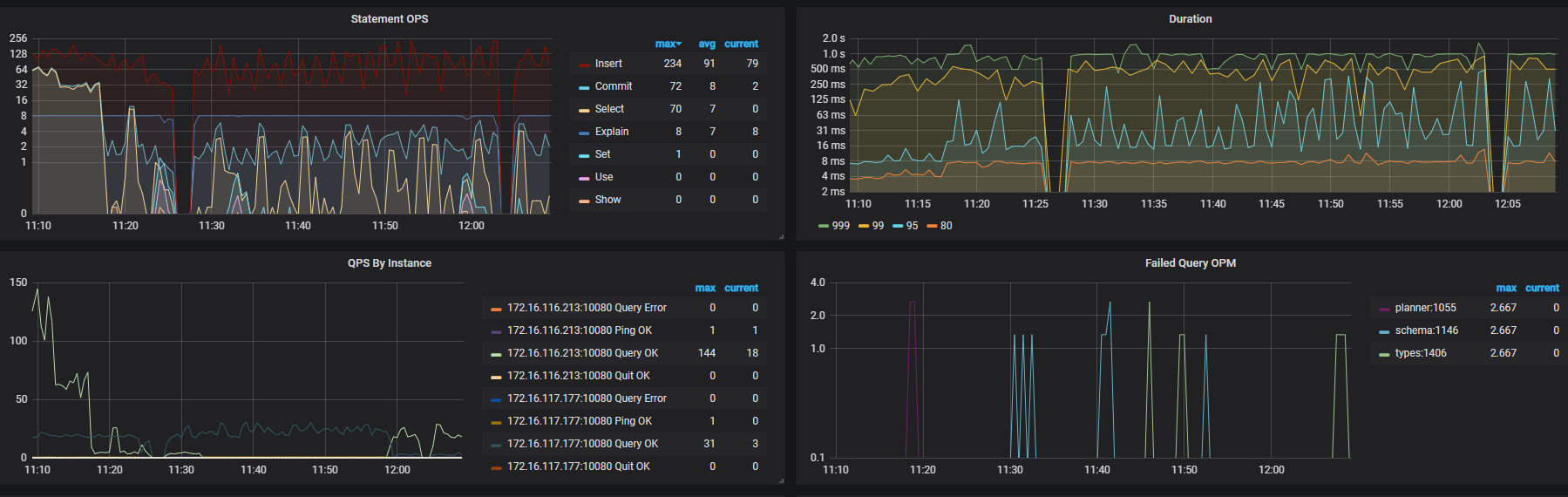
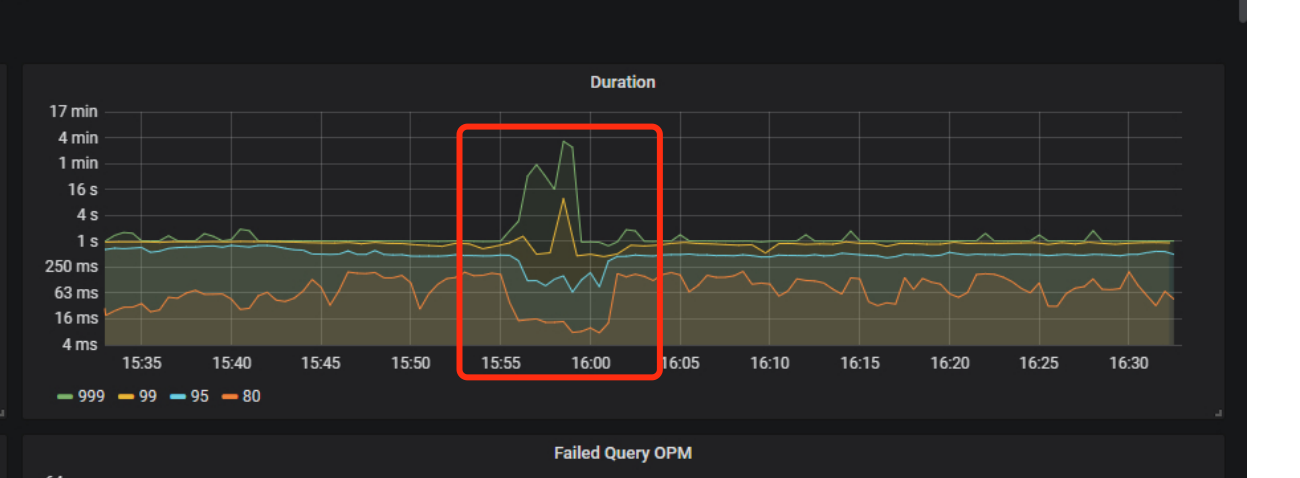
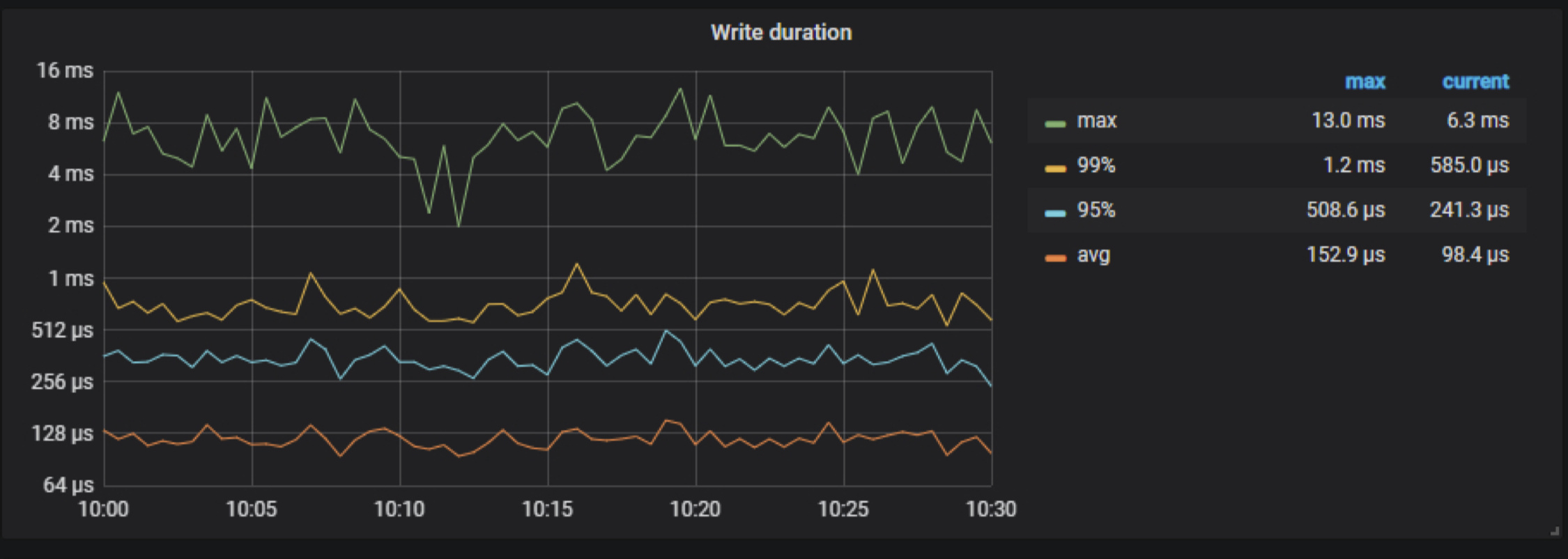
查看集群 Duration 监控,999 耗时在 500ms 左右
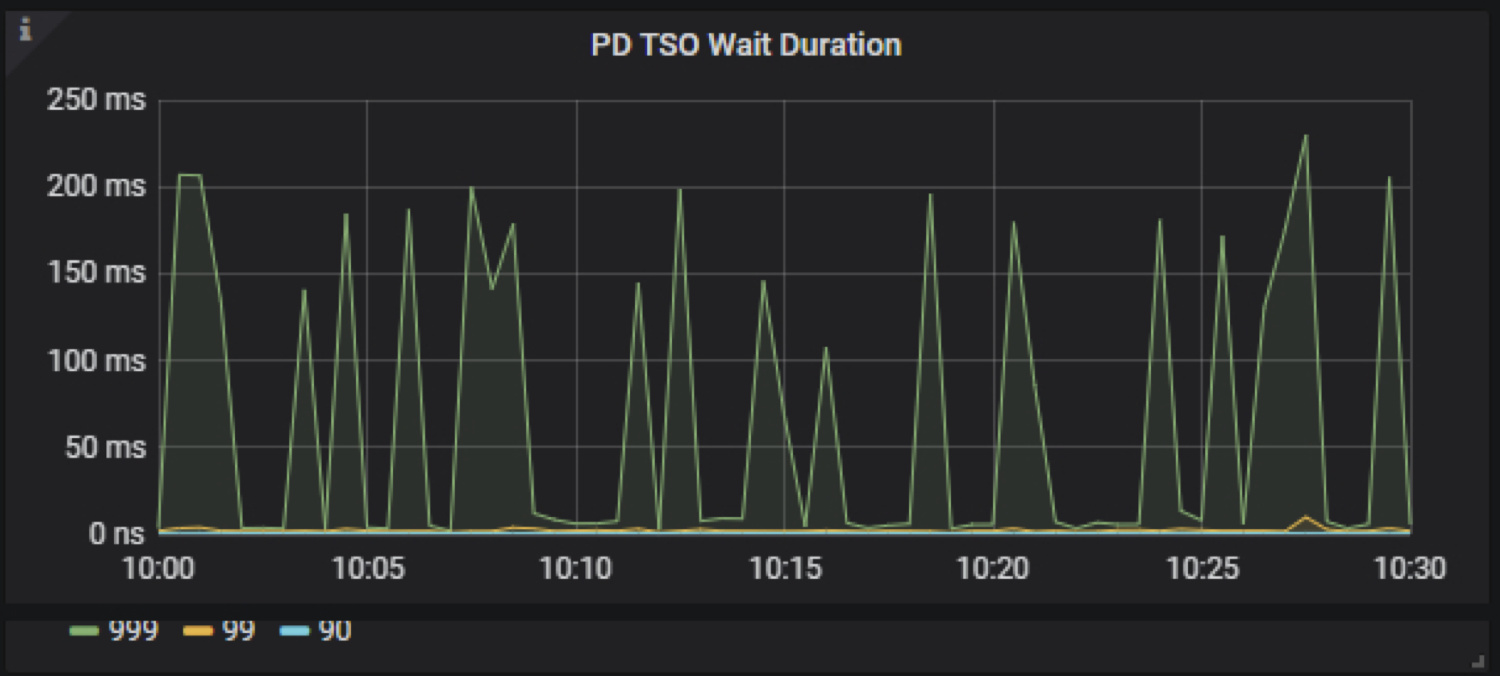
tso wait duration 比较高这个可以排查一下 pd 节点负载是否比较高
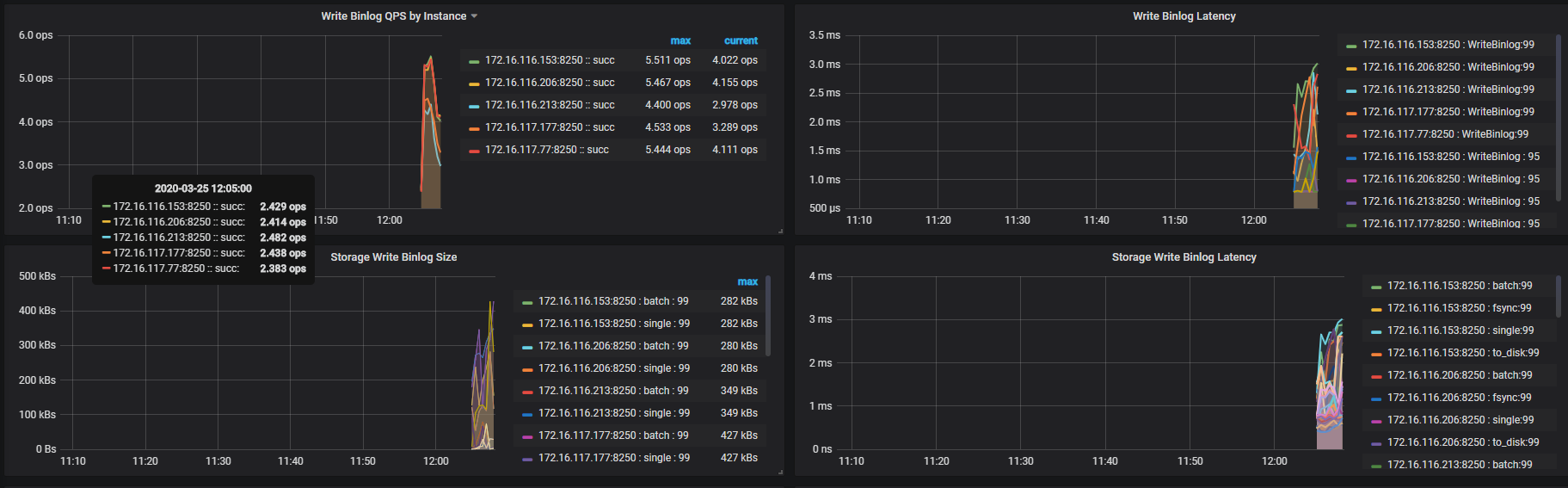
另外可以看下 Binlog 监控中 write binlog latency 的情况,判断一下 binlog 写入是否有影响
我确认一下目前的问题应该是确定写入慢的原因是吧,与 Binlog 没有关系,因为看之前的回复,一开始延迟高的时候查看配置文件中 Binlog 是没有开启的,后来开启之后集群的 Duration 也没有变化。
标题的开启 binlog 之后,tidb 写入延时变高,指的是部署 pump drainer 之后集群写入延迟才变高的吗?之前的延迟情况是怎么样的?
对,是确认写入慢的原因。这个是前几天重装的,之前用的3.0.9版本,每秒写入4000多,也没这么高的延时。
不好意思回复比较久,因为从监控中似乎没有找出明显的异常点 所以麻烦反馈一下下面两个信息:
类似这种形式,看下每个阶段的耗时
mysql> trace format='row' insert into test(name) values('sg');
+-------------------------------------------------------+-----------------+------------+
| operation | startTS | duration |
+-------------------------------------------------------+-----------------+------------+
| trace | 08:56:02.964877 | 8.041739ms |
| └─session.Execute | 08:56:02.964894 | 8.004243ms |
| ├─session.ParseSQL | 08:56:02.964911 | 37.253µs |
| ├─executor.Compile | 08:56:02.964998 | 97.466µs |
| │ └─session.getTxnFuture | 08:56:02.965004 | 3.588µs |
| └─session.runStmt | 08:56:02.965143 | 7.723137ms |
| ├─executor.handleNoDelayExecutor | 08:56:02.965159 | 411.549µs |
| │ └─*executor.InsertExec.Next | 08:56:02.965170 | 364.251µs |
| │ └─table.AllocBatchAutoIncrementValue | 08:56:02.965185 | 10.828µs |
| └─session.CommitTxn | 08:56:02.965590 | 7.22576ms |
| └─session.doCommitWitRetry | 08:56:02.965594 | 7.21476ms |
| └─tikvTxn.Commit | 08:56:02.965598 | 7.182527ms |
| ├─twoPhaseCommitter.prewriteMutations | 08:56:02.965683 | 4.152947ms |
| │ └─rpcClient.SendRequest | 08:56:02.965706 | 4.099288ms |
| ├─tikvStore.getTimestampWithRetry | 08:56:02.969850 | 298.04µs |
| └─twoPhaseCommitter.commitMutations | 08:56:02.970174 | 2.585914ms |
| └─rpcClient.SendRequest | 08:56:02.970198 | 2.526998ms |
+----------------------------
feedback-probability 参数设置为 0