将阿里云的tidb一张表的部分数据筛选之后同步到本地的tidb中,用什么方法好,哪位大佬可以告知一下,小白一枚,谢谢
- 如果是需要一次性筛选符合条件的数据导出然后导入,可以选择
mydumper -T {table_list} -w {where 条件}然后再通过 loader 进行导入,另外如果是使用 v3.0.5 以上的版本,可以使用 lightning backend = tidb 的模式进行导入。 - 如果需要持续把数据变更的输出到下游的 TiDB 的话,建议可以通过 TiDB-binlog 输出到 kafka ,然后自己再实现消费段的逻辑来实现。TiDB-binlog 的介绍可以参考这里:https://pingcap.com/docs-cn/stable/reference/tidb-binlog/overview/#tidb-binlog-简介
阿里云的数据量比较多,有30亿,差不多筛选4亿左右的数据,版本现在应该是3.0.1,是不是用mydumper 比较好点,还有我想问下mydumper 是不是安装在tidb的中控机就行
Mydumper 不一定要安装在 TiDB 的中控机上,只要网络能够连通就可以了。另外要注意,在筛选的 4亿的数据的过程 -w 涉及的条件有没有走中索引(可以通过 explain 确定),以及导出的时候建议加上 -F 或者 -r 对备份的数据进行切分。还有建议避开业务高峰期操作。
好的,另外我想问下从30亿数据筛选4亿然后导出再导入本地的tidb,这个时间会不会很久,没有操作过,有点慌
导入速度受到多方面的因素影响,如:硬件的配置, 导入时使用的并发参数,导入时集群的负载等。这边可以参考一下 DM load 处理单元导入的时候的速度:
https://pingcap.com/docs-cn/stable/benchmark/dm-v1.0-ga/#在-load-处理单元使用不同-pool-size-的性能测试对比
问一下,是mydumper 好点呢还是TiDB-binlog 好点
TiDB-binlog 只会把开启 Binlog 后的数据变化输出到你所配置好的目标,存量的全量数据还是得用 Mydumper 来做备份。
我刚才用mydumper 试了一下少量数据的,导出的是一个.sql文件,如果是30亿的话,这个.sql文件能不能hold住
Mydumper 可以通过 -r 或者 -F 来对一个表进行并发的备份并且会生成多个 .sql 文件。具体可以看看 Mydumper 的官方文档。
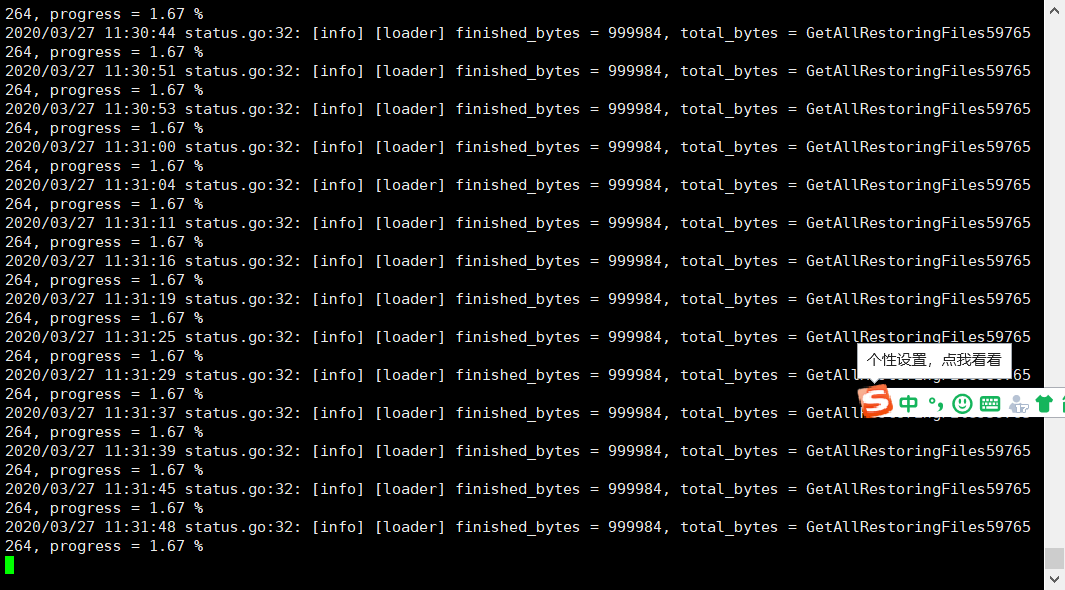
导入的数据也不多,才几十万,就一直这样,数据少的就直接导进去了,这是什么原因。
loader语句:./bin/loader -h 192.168.141.10 -u root -p ‘879445’ -P 4000 -t 32 -d ./value
-
可以看下下游 TiDB 集群监控,看下集群负载高不高
-
查看下游 tidb.log 日志,确认 tidb server 正常工作
-
可以检查一下 loader 所在服务器 CPU 使用情况
-
因为日志打印的是 loader 的进度,请问 progress 是否会改变,还是 loader 一启动就是 1.67%,然后一直卡住不动
-
可以尝试将减少并发 -t 设置为 4 看是否可以导入
一启动就是1.67,很多时候是0.00,导3000条数据很快,导几十万就不行了,试了好几次都是这样,而且tidb卡住了,数据库也打不开,就跟死机了一样
可能是 tidb 负载太高
- 方便的话提供一下 tidb.log 日志
- 可以降低并发,调整 -t 为4 ,降低 tidb 的压力看下数据能否导入,不卡住 tidb

从日志看是 tidb 连接 tikv 时没有响应,判断是并发写入量大导致 tikv 繁忙
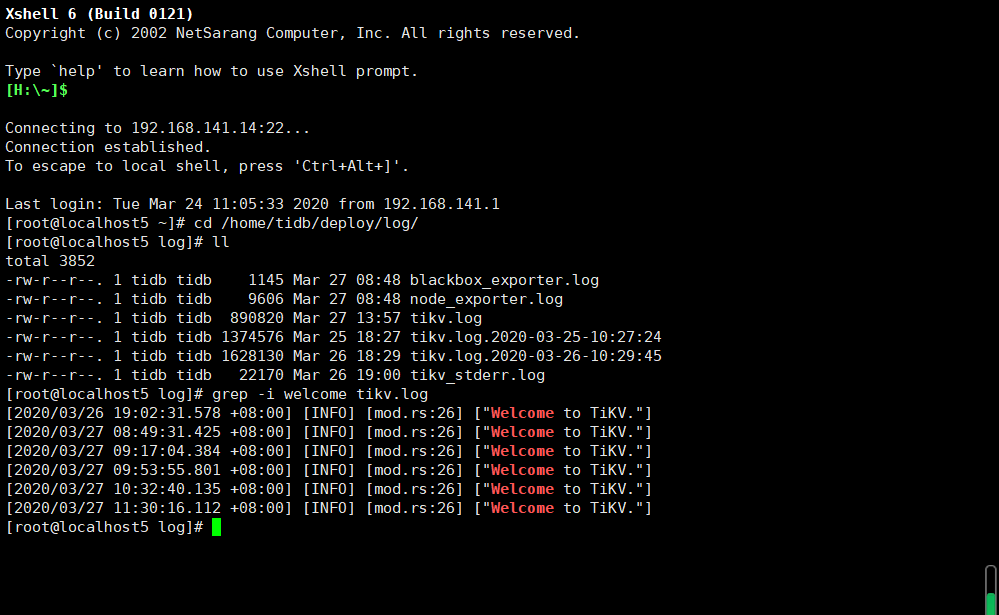
- 可以 grep -i welcome tikv.log 确认一下 tikv 是否有重启的情况
- 可以降低并发,调整 -t 为4 ,降低 tidb 的压力看下数据能否导入,不卡住 tidb
- 线上环境导入数据,主要看服务器配置,如果服务器配置足够,那导入一般不会有问题
好的,谢谢啊,我自己的电脑配置不是很高,所以很卡,我一会修改并发试一下,有问题我及时请教
嗯嗯,有问题可以反馈给我们![]()