为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】:v3.0.10
- 【问题描述】:向下游tidb集群同步binlog发生了延迟,如何定位问题

若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。
为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。
你好,请收集反馈完整的 pump 和 drainer 的监控信息:
(1) chrome 安装这个插件https://chrome.google.com/webstore/detail/full-page-screen-capture/fdpohaocaechififmbbbbbknoalclacl
(2) 鼠标焦点置于 Dashboard 上,按 ?可显示所有快捷键,先按 d 再按 E 可将所有 Rows 的 Panels 打开,需等待一段时间待页面加载完成。
(3) 使用这个 full-page-screen-capture 插件进行截屏保存
1、监控 Drainer Event 看到这段时间存在批量 delete 和 update 等 DML 操作,可能是造成同步延迟高的原因,建议先调大 txn-batch 和 worker-count 参数;
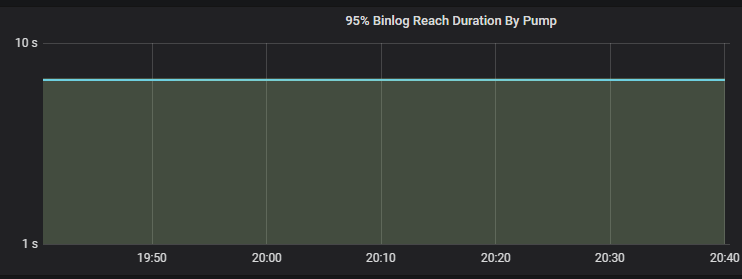
2、监控 Execution time 比较高,也可能是下游执行比较慢,检查下游 TiDB 集群的负载和慢查询日志,是否有性能问题。
调整后的参数,txn-batch:2000; worker-count:128
下游有一台机器时不时的负载会升高,既是pd,tidb也是tikv。
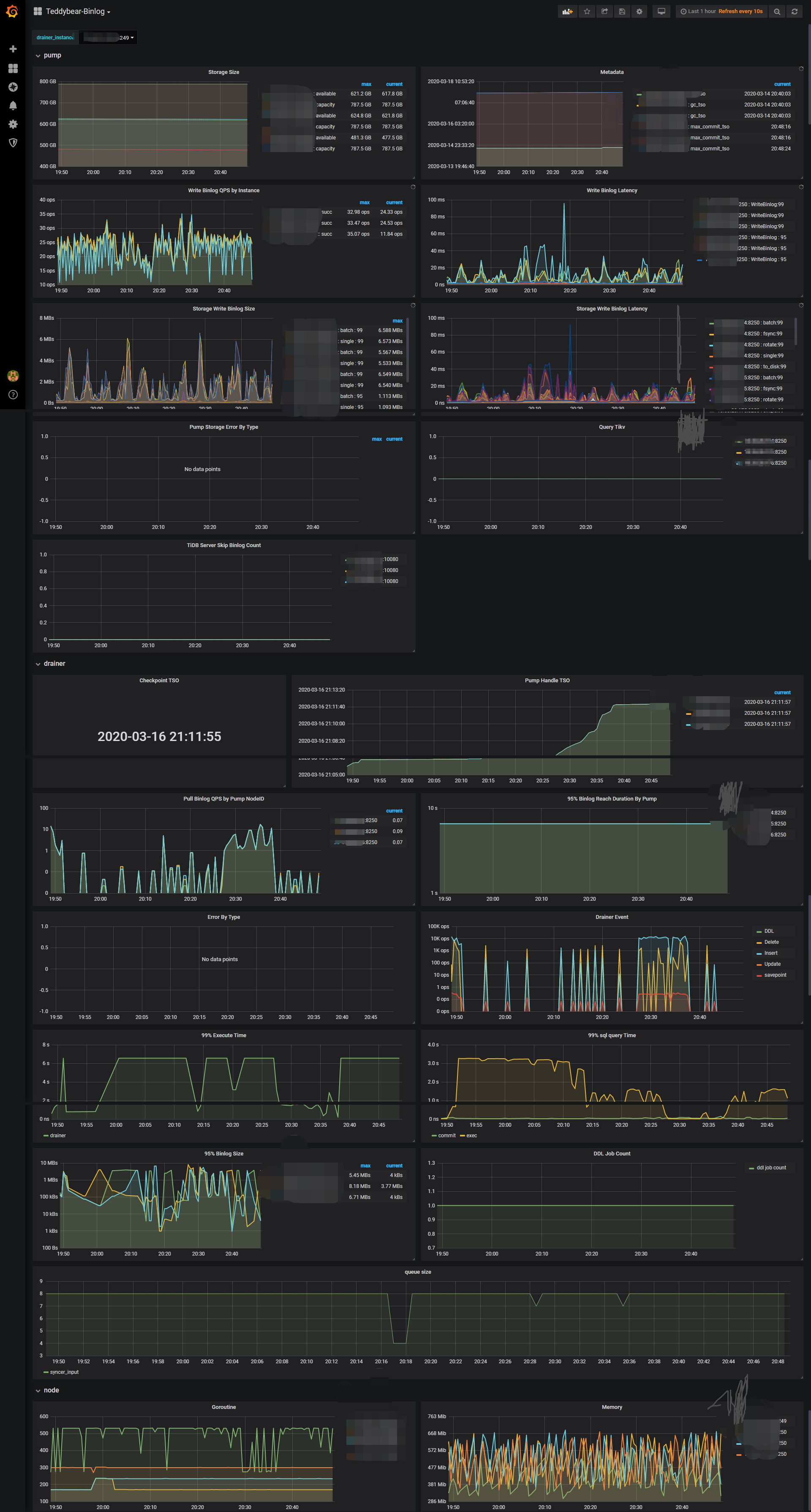
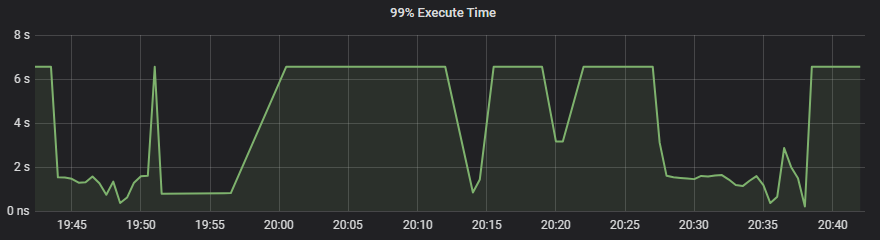
下图是根据slow_query 表按照 query_time 排序。延迟还在增大,已经超过35个小时。
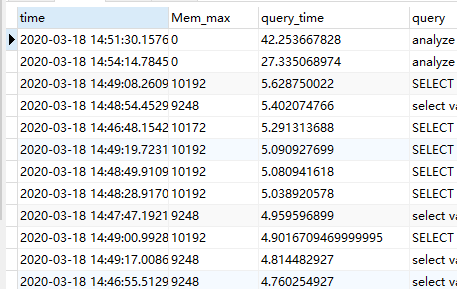
slow_query 主要是 select 查询,没有发现 drainer 同步过来的 DML,方便的话传一下修改配置后的 drainer 日志,检查其中记录的 sql 执行时间。
日志显示看到 worker-count: 128 参数已经生效,下面显示 table has no any primary key and unique index,检查同步的表是否有主键或唯一索引;如果没有,在同步时为了保证事务的顺序,无法将事务拆分到不同的线程中,不能有效利用 worker count 提高并发,同步性能会大大下降,建议为表增加主键或唯一键。