Tidb2.1.7升级tidb3.0.11报错
手动delete调evict后,再次执行升级命令,excessive_rolling_update.yml后,再次报错

Tidb2.1.7升级tidb3.0.11报错
手动delete调evict后,再次执行升级命令,excessive_rolling_update.yml后,再次报错
您好:
1. 请在中控机inventory.ini文件中检查下process_supervision参数值
2. 升级时添加-vvv参数,打印下详细错误
3. 上传中控机<deploy>/log目录下的ansible.log文件您好:
1. 从ansible日志里查看,获取health失败
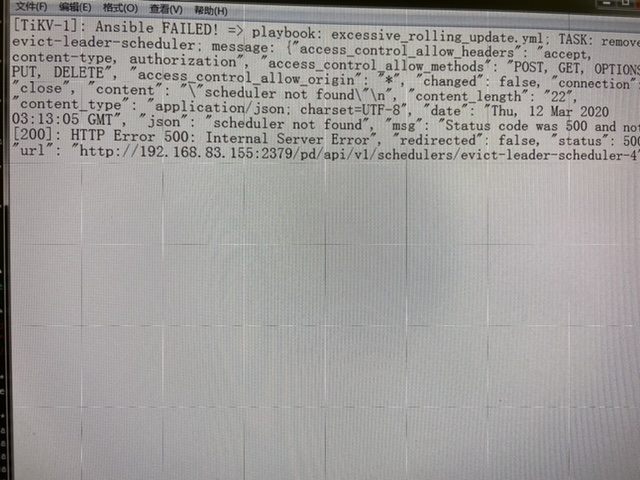
2020-03-12 14:30:15,127 p=12941 u=tidb | ERROR MESSAGE SUMMARY ******************************************************************************************************************************************************************************************************************************************************** 2020-03-12 14:30:15,127 p=12941 u=tidb | [PD-1]: Ansible FAILED! => playbook: excessive_rolling_update.yml; TASK: Check pd cluster status; message: {“changed”: false, “content”: “”, “msg”: “Status code was -1 and not [200]: Request failed: <urlopen error [Errno 111] Connection refused>”, “redirected”: false, “status”: -1, “url”: “http://192.168.83.155:2379/pd/health”}
2. 请使用curl -G http://192.168.83.155:2379/pd/health 检查pd是否正常
3. 如果异常,尝试先修复pd,多谢
4. 之前说的delete evict是怎么操作的使用curl delete ip:2379/pd/api/v1/schedulers/evict-leader-scheduler-4删除的。 我重启tidb后,pd好了,我再次执行升级命令,还是升级失败。提示让检查pd状态,我在浏览器里查看3个pd的health都是true,怀疑是不是我执行的delete导致了后续问题
看了下pd stores 我3个store,1个是3.0.11,2个是2.1.6
你好:
1. 升级过程中要滚动升级pd,如果正好leader在store 4上,你把evict leader删掉了,他没法把leader转移出去了。
2. 尝试增加一个调度器,看看能否成功
https://pingcap.com/docs-cn/stable/reference/best-practices/pd-scheduling/#leaderregion-分布不均衡