Dwana
2020 年3 月 5 日 10:58
1
为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
【TiDB 版本】:3.0.9
【问题描述】:
若提问为性能优化、故障排查 类问题,请下载脚本 运行。终端输出打印结果,请务必全选 并复制粘贴上传。
qizheng
2020 年3 月 6 日 03:13
4
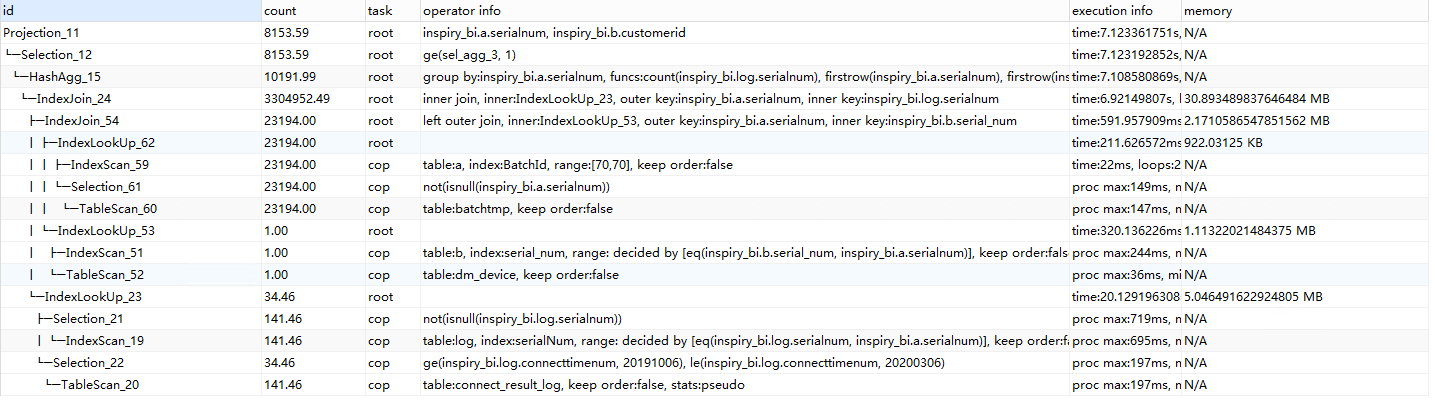
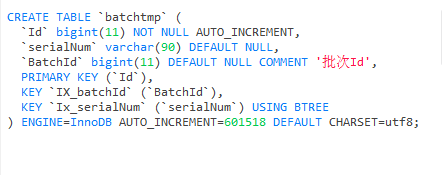
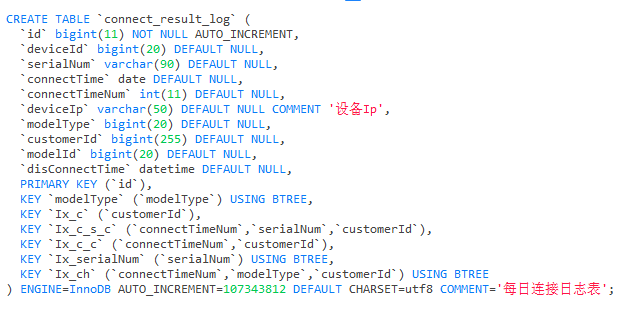
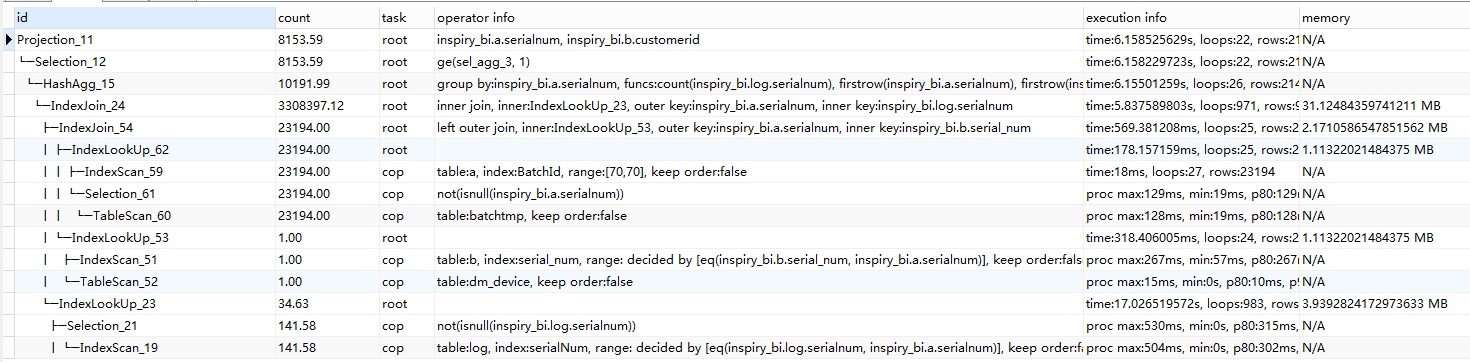
1、可以先确认下统计信息是否准确,关于查看和收集统计信息详见https://pingcap.com/docs-cn/stable/reference/performance/statistics/
2、如果执行计划未发生改变,explain analyze 确认下哪个算子耗时比较长,
Table/Index Scan 相关参数
tidb_index_lookup_size
tidb_index_lookup_concurrency
tidb_index_serial_scan_concurrency
tidb_distsql_scan_concurrency
算子相关参数
tidb_index_join_batch_size
tidb_index_lookup_join_concurrency
tidb_hash_join_concurrency
tidb_projection_concurrency
tidb_hashagg_partial_concurrency
tidb_hashagg_final_concurrency
qizheng
2020 年3 月 6 日 06:26
6
batch size 没必要调这么大,调大 tidb_index_lookup_join_concurrency ,调整参数在 session 级别设置就好,另外问下这个 SQL 预期的执行时间是多少。
qizheng
2020 年3 月 6 日 08:46
8
Dwana
2020 年3 月 9 日 03:03
9
sorry,拖了这么长时间才回复,
我的意思是没有下线这前,整个机器的内存使用情况如何?有没有 swap?有没有内存占用比较多的情况
Dwana
2020 年3 月 9 日 05:40
13
没有,目前还在测试阶段,没有任何流量,只有我一个人在测试,@IDENTITY 怎么在TIDB中实现呢?
请确认一下楼上提到的信息,因为将 DM 下线了性有就上去了,可能资源占用有关,特别是内存、CPU 相关
可以用 select last_insert_id(); 完成相同的功能
system
2022 年10 月 31 日 19:11
18
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。