simo
(Simo)
1
为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】:v3.0.8
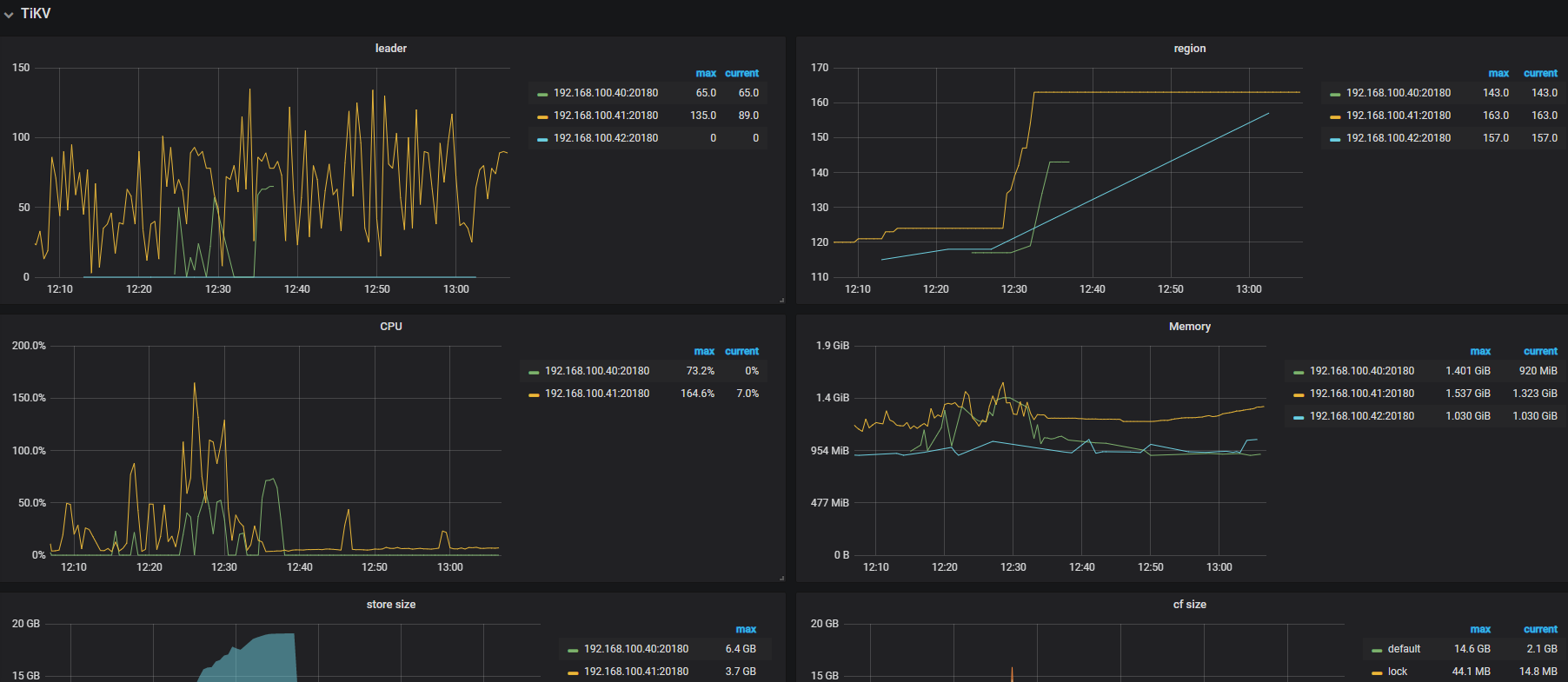
- 【问题描述】:tidb_lightning导入数过程中,服务器宕机重启后,tikv节点无法恢复正常工作 region信息丢失
重新启动 tikv 节点没有问题 但是监控看到tikv节点 down 有时候一个 有时候两个
tikv.log (3.0 MB) tikv_importer_stderr.log (72 字节)
tidb_lightning.log (65.1 KB)
tikv_importer.log 没有错误信息
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。
目前集群总共几个 tikv 节点?
麻烦检查一下每个节点的 tikv.log 日志,grep -i “welcome” 看下 tikv 节点有没有重启的情况
目前报 FATAL 错误的 tikv 节点有几个?
simo
(Simo)
5
三个tikv节点 每个都有报错 [ERROR] [transport.rs:318] [“send raft msg err”] [err=“Other(”[src/server/raft_client.rs:216]: RaftClient send fail")"] 但是 监控看到的掉线两台 会出现 [sst_importer.rs:62] [“ingest failed”] [err=“Engine RocksDb(“read metadata from /home/poitech/work/deploy/data/import/515372e2-27f0-4373-8e60-0e9cf7bc3052_180_5_44.sst: Os { code: 2, kind: NotFound, message: \“No such file or directory\” }”)”] [meta=“uuid: 515372E227F043738E600E9CF7BC3052 range { start: 7480000000000000FF315F728000000004FF08E48A0000000000FAFFFFFFFFA1A1CF1A end: 7480000000000000FF315F728000000004FF08E4C60000000000FAFFFFFFFFA1A1CF1A } crc32: 2382796013 length: 2605 cf_name: “default” region_id: 180 region_epoch { conf_ver: 5 version: 44 }”]
这种提示
simo
(Simo)
8
tikv_log.zip (765.6 KB)
raftstore:
sync-log: false
[2020/03/04 14:48:14.675 +08:00] [FATAL] [lib.rs:499] ["[region 180] 183 ingest uuid: 515372E227F043738E600E9CF7BC3052
range { start: 7480000000000000FF315F728000000004FF08E48A0000000000FAFFFFFFFFA1A1CF1A end: 7480000000000000FF315F7280
00000004FF08E4C60000000000FAFFFFFFFFA1A1CF1A } crc32: 2382796013 length: 2605 cf_name: \"default\" region_id: 180 regi
on_epoch { conf_ver: 5 version: 44 }: Engine(RocksDb(\"read metadata from /home/poitech/work/deploy/data/import/515372
e2-27f0-4373-8e60-0e9cf7bc3052_180_5_44.sst: Os { code: 2, kind: NotFound, message: \\\"No such file or directory\\\"
}\"))"]
看日志是有 SST 文件丢失了,重启前后是否有清理过 /home/poitech/work/deploy/data/import/ 这个目录呢?能否确认一下 515372 e2-27f0-4373-8e60-0e9cf7bc3052_180_5_44.sst 这个文件是否存在?
simo
(Simo)
10
没有啊 今早机器重启后我就直接启动了 三个tikv 节点 (昨天只有三个tikv 节点挂了 tidb 与pd 的都是好的)
simo
(Simo)
11
我刚问了下 服务器是公司自己搭建的 然后磁盘是伸缩的 然后昨天磁盘满了 会不会是一部分在内存中 然后挂了 数据丢失了 会不会是这种现象 如果是 怎么解决
simo
(Simo)
13
这种情况 有救么 怎么处理 清理错误region么
是只有一个 tikv 会 panic 吗?如果是的话,可以先用 tikv-ctl size 命令查看 region 是否为空,如果为空的话说明可以安全恢复,用 tikv-ctl 把问题 tikv 上 180 这个 region 设置为 tombstone 就好了,如果不为空强制恢复的话有丢数据的风险。
simo
(Simo)
17
tikv-ctl --db /path/to/tikv/db tombstone -p 127.0.0.1:2379 -r <region_id> 第二步卡死 ,
第一步成功了( ```
pd-ctl>> operator add remove-peer <region_id> <store_id>
可能被 rocksdb 的文件锁卡住了,需要先停掉 tikv 才能进行操作
simo
(Simo)
19
使用的时候 我把集群都停了 不过现在把数据清理了 只能说暂时跳过这个问题 再遇到就废了