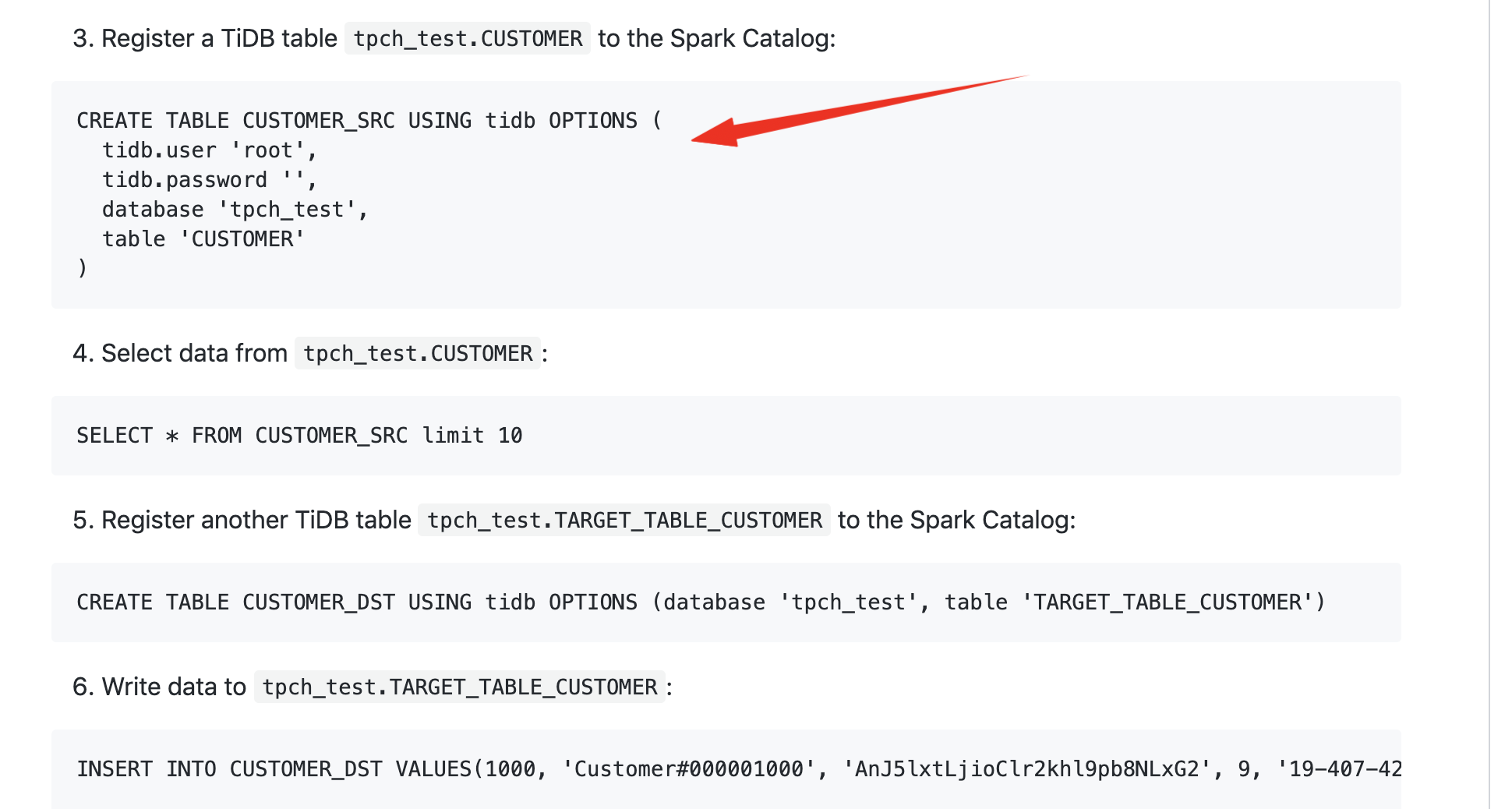
【问题描述】:beeline连接Tispark thriftserver时执行: insert into CUSTOMER_2 select * from CUSTOMER;
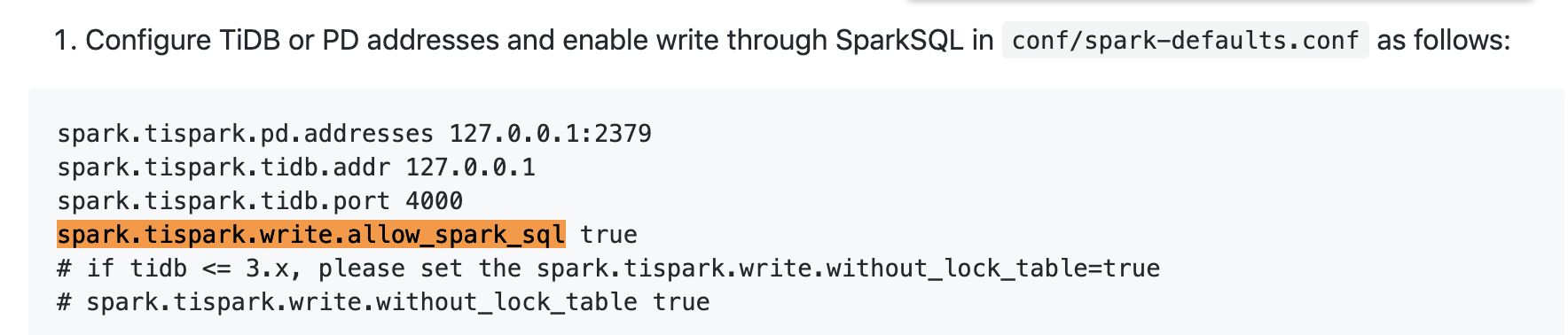
报Error: com.pingcap.tikv.exception.TiBatchWriteException: SparkSQL entry for tispark write is disabled. Set spark.tispark.write.allow_spark_sql to enable. (state=,code=0)
Set spark.tispark.write.allow_spark_sql=enable;
±-------------------------------------±--------±-+
| key | value |
±-------------------------------------±--------±-+
| spark.tispark.write.allow_spark_sql | enable |
±-------------------------------------±--------±-+
0: jdbc:hive2://localhost:10000> insert into CUSTOMER_2 select * from CUSTOMER;
Error: com.pingcap.tikv.exception.TiBatchWriteException: SparkSQL entry for tispark write is disabled. Set spark.tispark.write.allow_spark_sql to enable. (state=,code=0)