为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】:v3.0.5
- 【问题描述】: TiKV_GC_can_not_work pingcap 文档的报警rule 和 实际环境李prometheus里面的报警rule不一致
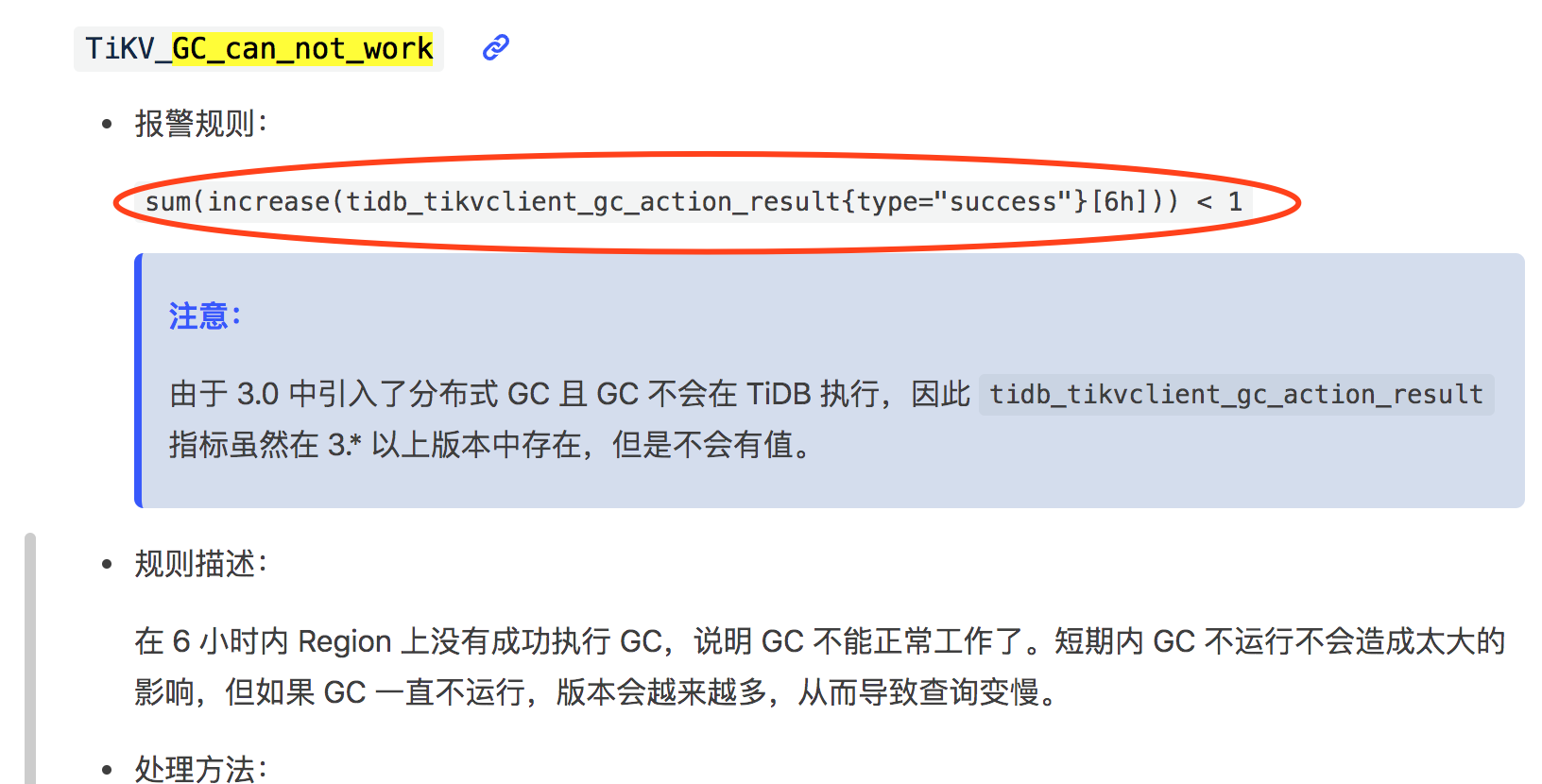
pingcap文档描述的报警rule:
实际环境prometheus的报警rule
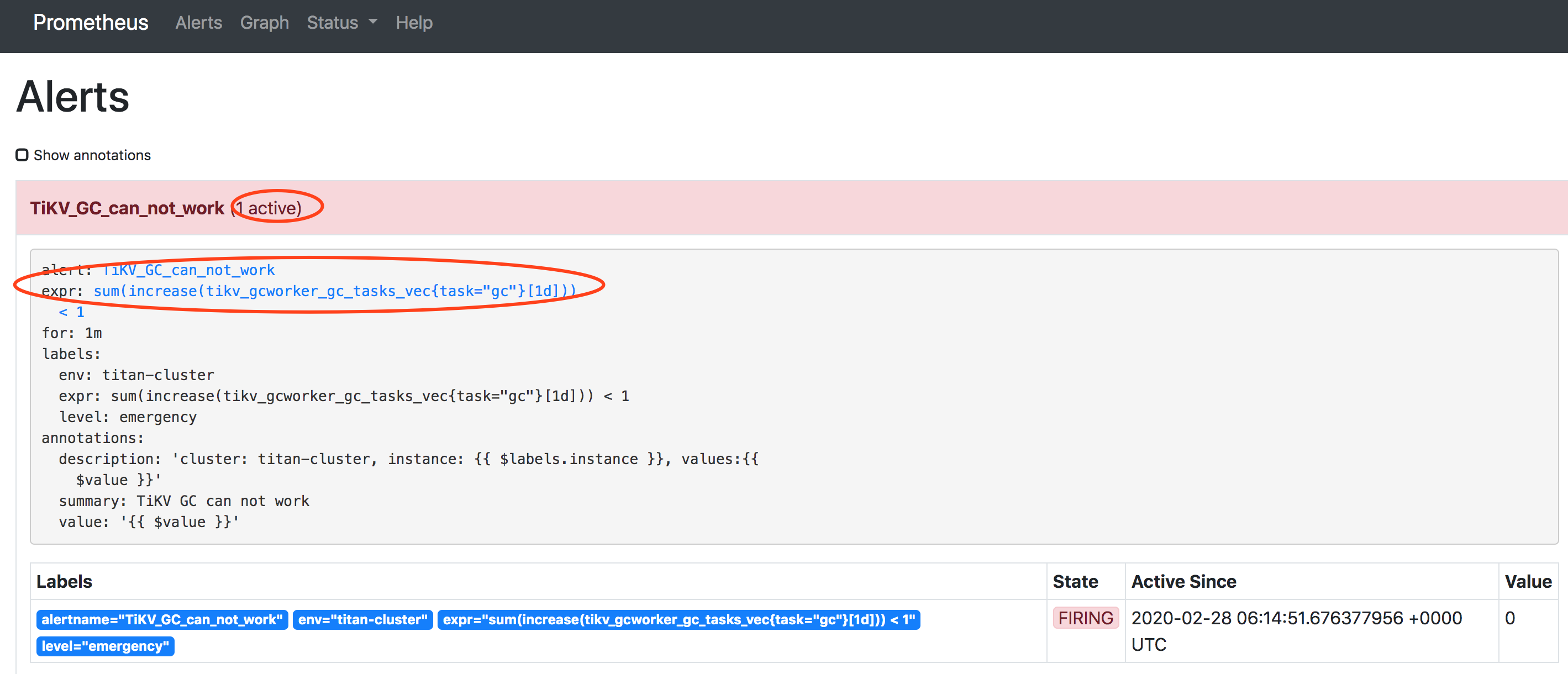
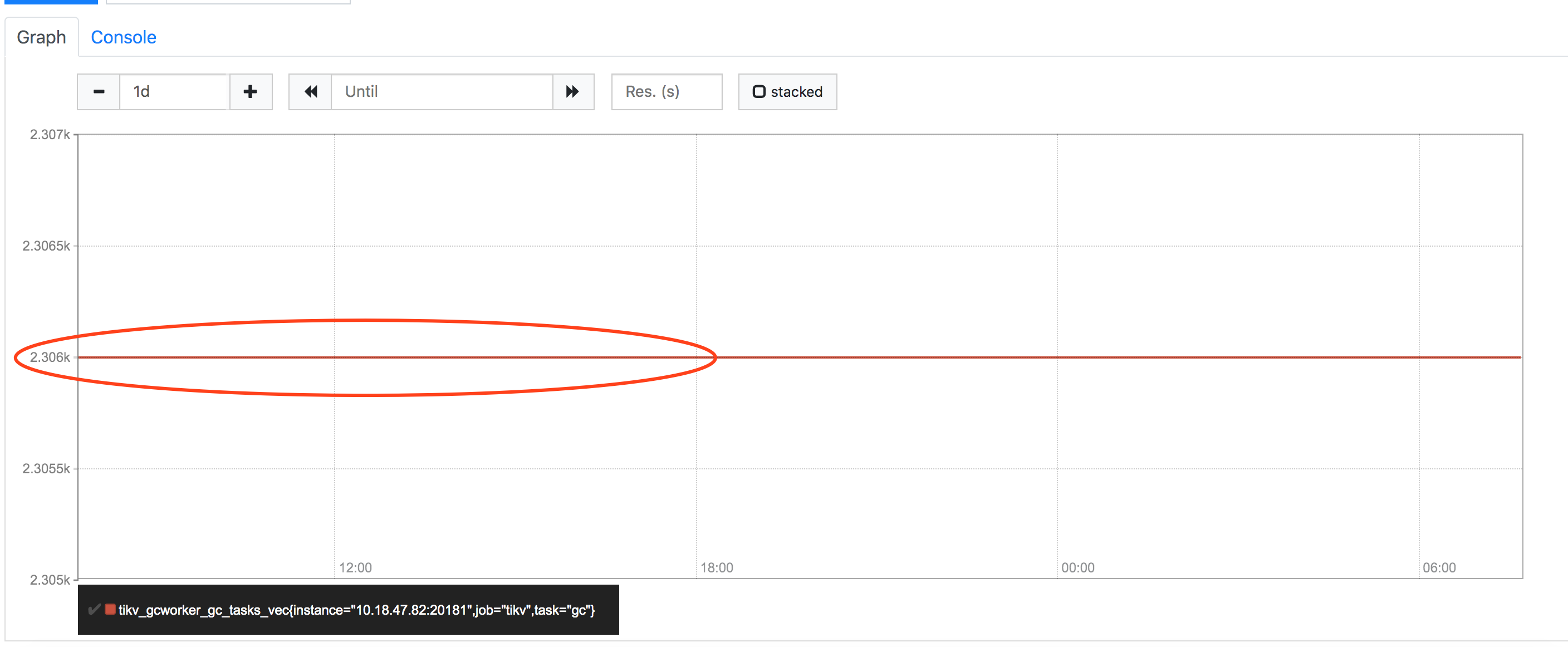
两者不一致,然后prometheus出现TiKV_GC_can_not_work的报警
为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
pingcap文档描述的报警rule:
实际环境prometheus的报警rule
两者不一致,然后prometheus出现TiKV_GC_can_not_work的报警
感谢建议,从 3.0 开始,引入了分布式 GC,TiKV_GC_can_not_work 告警的表达式变更为下述表达式,我们这里更新下官方文档,谢谢:
sum(increase(tikv_gcworker_gc_tasks_vec{task=“gc”}[1d]))
现在我这个系统,一天的tikv_gcworker_gc_tasks_vec{task=“gc”} 值都是2306,没有变化,所以导致报警。
新系统没怎么使用,可以请假下,怎么去排查这个原因吗。为什么gc 的count数量不变了?
TiDB GC 相关的内容可以看下下述文档,了解下 GC 的机制,GC 触发的时间等:
https://pingcap.com/docs-cn/stable/reference/garbage-collection/overview/#gc-机制简介
https://pingcap.com/docs-cn/stable/reference/garbage-collection/configuration/
现象
使用tidb-v3.0.5的告警规则,拉起新集群必定产生一次 [TiKV_GC_can_not_work 告警]
排查结果
https://pingcap.com/docs-cn/stable/alert-rules/#tikv_gc_can_not_work 基本确认跟文档中描述一致,GC正常
疑问
是什么原因造成这种现象的?数据采集抖动?
你好,
有问题欢迎开新帖讨论下,此贴已经很久远了。
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。