为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】:3.0.3
- 【问题描述】:在数据同步的过程中上游修改的表的结构导致报错,任务以暂停
DM 在同步时会校验上下游字段的数量是否一致,上述报错是在什么情况下发生的?是上游修改表 A 的结构成功了,但是没有同步到下游 TiDB 的表 A。然后上游写数据到表 A,此时出现了 task 中的报错?
DM在同步时上游和下游的表字段是一致的,在同步的过程中上游表A修改字段成功,导致报错 上游现在23个字段,下游27个字段
1、“在同步的过程中上游表 A 修改字段成功”,这个操作具体是指什么操作?
2、上游 23 个字段,下游 27 个字段,这个现象出现,具体是做了什么操作?
DM在同步时上游和下游的表字段是一致的,同步的过程中上游表A减少了列
1、确认同步的架构,是上游单实例同步到下游 TiDB 中,而不是上游合库合表同步到下游 TiDB 的场景是吗?
2、如果是上游是单实例 MySQL 删除了某个字段,但是没有同步到下游,建议从以下步骤进行排查:
1)找到上游 DDL 操作对应的 gtid 并记录
2)从下游拉取的 relaylog 确认该 gtid 是否已成功拉取到 DM
3)查看 task 或 dm-worker log 确认下,针对 A 表的 DDL 操作没有同步到下游的原因
4)在 task 中没有配置 binlog-event-filter 选项
https://pingcap.com/docs-cn/stable/reference/tools/data-migration/features/overview/#binlog-event-filter
1:是上游是单实例 MySQL 删除了某个字段,这是dm-woker的日志 错误是列的数值不匹配,上游23列,下游27列,其他的看不太明白。
现在的问题是,我们需要确认下,为什么上游针对 A 表的 DDL 删除 column 的操作没有同步到下游的 TiDB,所以建议从下面来进行排查:
1、找到上游 MySQL binlog 中 DDL 对应的 gtid
2、检查下游 dm 拉取的 relaylog 中是否有相应的 gtid ,排除掉因为 relaylog 缺失而引起的 DDL 无法同步的情况
3、检查下 worker 日志,查看下是否有关于 A 表的 DDL 操作
4、检查下 binlog event 以及 sql-pattern 部分是否有 alter table drop column 相关设置
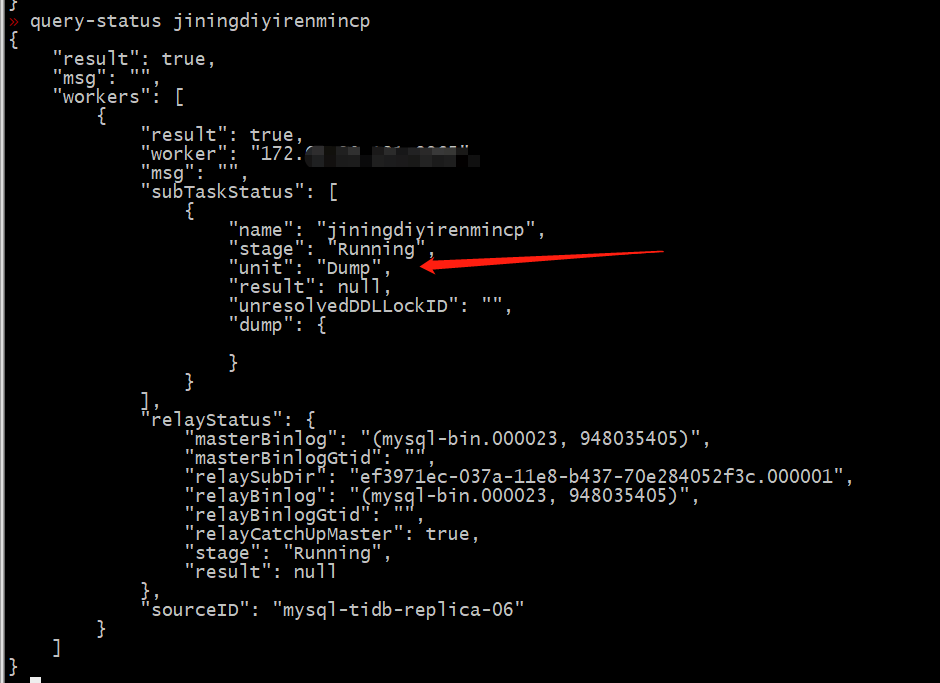
1、表示当前处于 dump 处理单元
2、建议查看下述内容,了解任务状态的相关信息:
https://pingcap.com/docs-cn/stable/reference/tools/data-migration/query-status/#任务状态
3、另外,DM 也提供了源码系列文章:
filrers 中有忽略 alter table * 的命令?因为截图不全,所以问下?
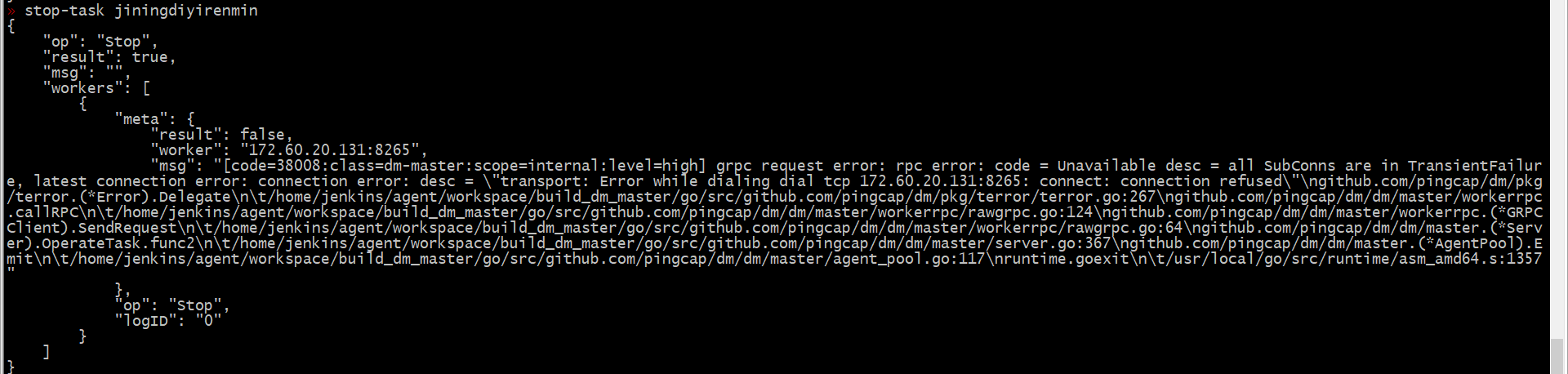
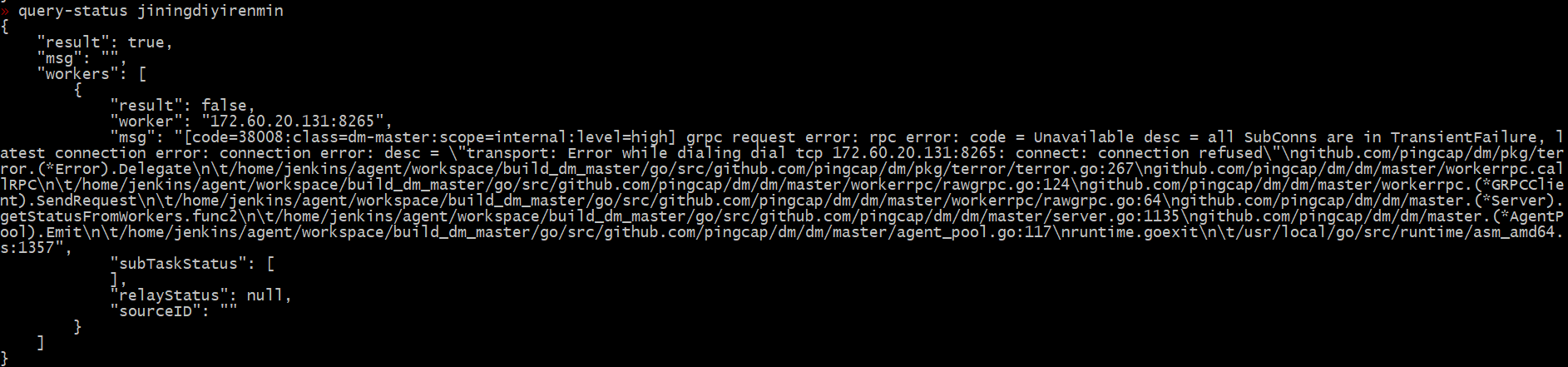
stop 任务之后,DM 服务里面已经没有了这个 task 相关信息,在监控层面能看到是正常的。因为 prometheus 里面的数据是一直在追加写,短期内是一直能看到监控信息,如果数据在一定时间之后被 GC,也就不会在显示。
prometheus 也是重启的,任务停止已经超过半个小时了,请问 :如果数据在一定时间之后被 GC,也就不会在显示。 这个是需要配置,还是手动清除,如果是手动清除,该如何操作。
元数据已经存储下来了,跟 prometheus 重启没关系。目前的默认保留策略是 30 天,除非有必要,不建议修改。https://github.com/pingcap/tidb-ansible/blob/master/roles/prometheus/defaults/main.yml
手动清除该taskname在Grafana监控中显示该如何操作
grafana 只是拿 prometheus 数据作为展示,prometheus 里面只要有数据保留,就一直可以展示,并不会影响使用。