背景信息
由于大表的原因,迁移到tidb进行测试,
TiDB 总体问题/TiDB 生态工具问题
TiDB 性能问题
TiDB-SQL 问题
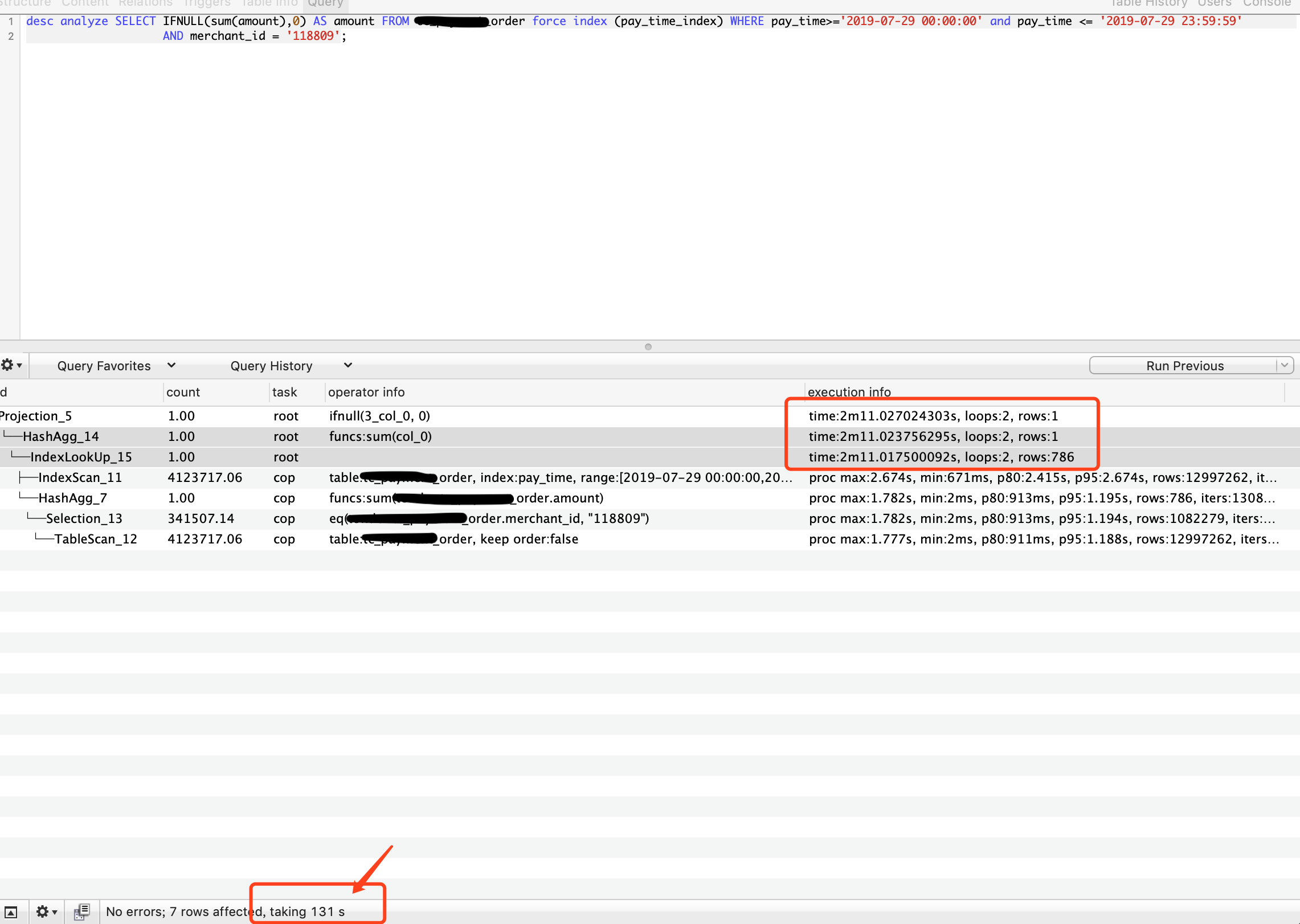
1、sql 和 plan 如图
2、表结构
CREATE TABLE
order (id bigint(20) NOT NULL AUTO_INCREMENT,payment_order_id varchar(64) NOT NULL DEFAULT ‘’ COMMENT ‘’,merchant_id varchar(255) NOT NULL DEFAULT ‘’ COMMENT ‘’,merchant_name varchar(255) NOT NULL DEFAULT ‘’ COMMENT ‘’,out_trade_no varchar(64) NOT NULL DEFAULT ‘’ COMMENT ‘’,merchant_rate int(11) NOT NULL DEFAULT ‘0’ COMMENT ‘’,merchant_fee int(11) NOT NULL DEFAULT ‘0’ COMMENT ‘’,amount bigint(20) NOT NULL DEFAULT ‘0’ COMMENT ‘’,pay_time timestamp NOT NULL DEFAULT ‘1970-01-01 08:00:01’ COMMENT ‘’,create_time timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,update_time timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,PRIMARY KEY (
id),UNIQUE KEY
payment_order_id (payment_order_id),UNIQUE KEY
mch_trade_no (merchant_id,out_trade_no),KEY
out_trade_no (out_trade_no),KEY
creat_time_index (create_time),KEY
pay_time_index (pay_time)) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin AUTO_INCREMENT=46318751 COMMENT=‘订单表’;
3、这个表数据量4000万
4、机器配置是
三台 4CPU 8G SSD500G
TiBD1 - PD,TiKV
TiBD2 - PD,TiKV,TiDB
TiBD3 - PD,TiKV,TiDB
自己从执行结果上看,主要的耗时是在sum上,请问应该怎么优化
理论/原理性问题
保证问题描述清晰。
