KS贺大伟
2022 年1 月 10 日 06:10
1
为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
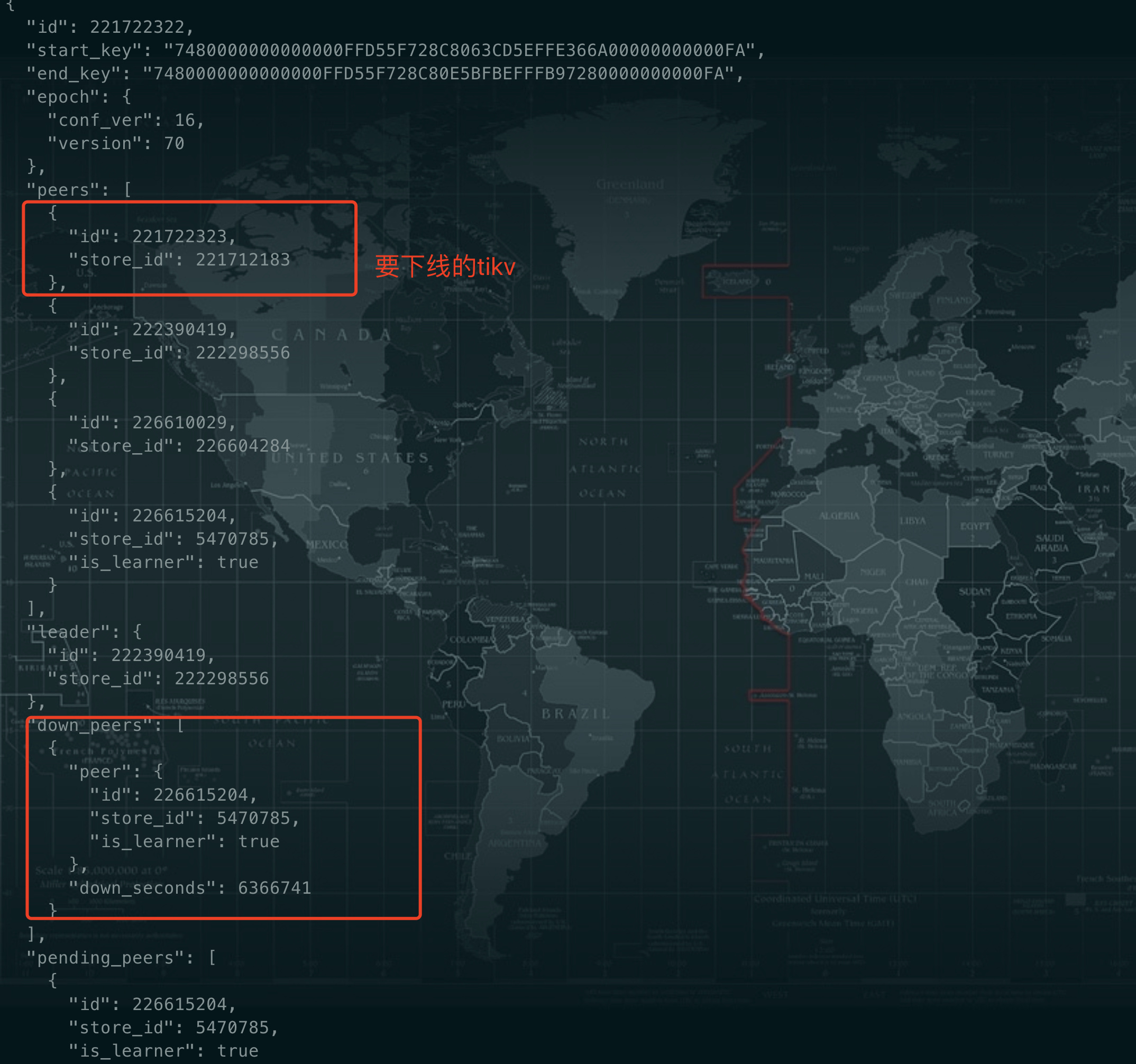
剩余一个region没有因为下线tikv而迁移,查询store的region信息和region的信息,这个region
集群二
另外一个集群(v4.0.14)下线tikv,发现剩余两个region无法完成下线
有问题的region信息如下:
对应region store以及store的region信息都进行过核对了,信息都是可以对齐的,不像https://asktug.com/t/topic/303575/28这里描述的哪些问题。
【背景】做过哪些操作
TiUP Cluster Display 信息
TiUP Cluster Edit Config 信息
TiDB- Overview 监控
2 个赞
林先森cC
2022 年1 月 10 日 06:34
2
没下线成功的region 可以根据region_id或者peer_id在 pd leader节点的日志看下 有没有啥调度失败的日志 以及tikv节点上 看到的相关报错信息也发出来下
幸苦把以上的相关信息收集下也发出来 方便大家排查 谢谢
KS贺大伟
2022 年1 月 10 日 06:58
3
集群一自己恢复了,下线完成,集群一的region信息算是正常,所以早上的时候手动remove down peer,下午刚刚成功了(发现remove一个peer,会看到N条相关的重复日志(Leader节点上),按照一定的间隔不断的打印,很久之后才会成功,不知道原因,好在可以成功)
KS贺大伟
2022 年1 月 10 日 07:15
5
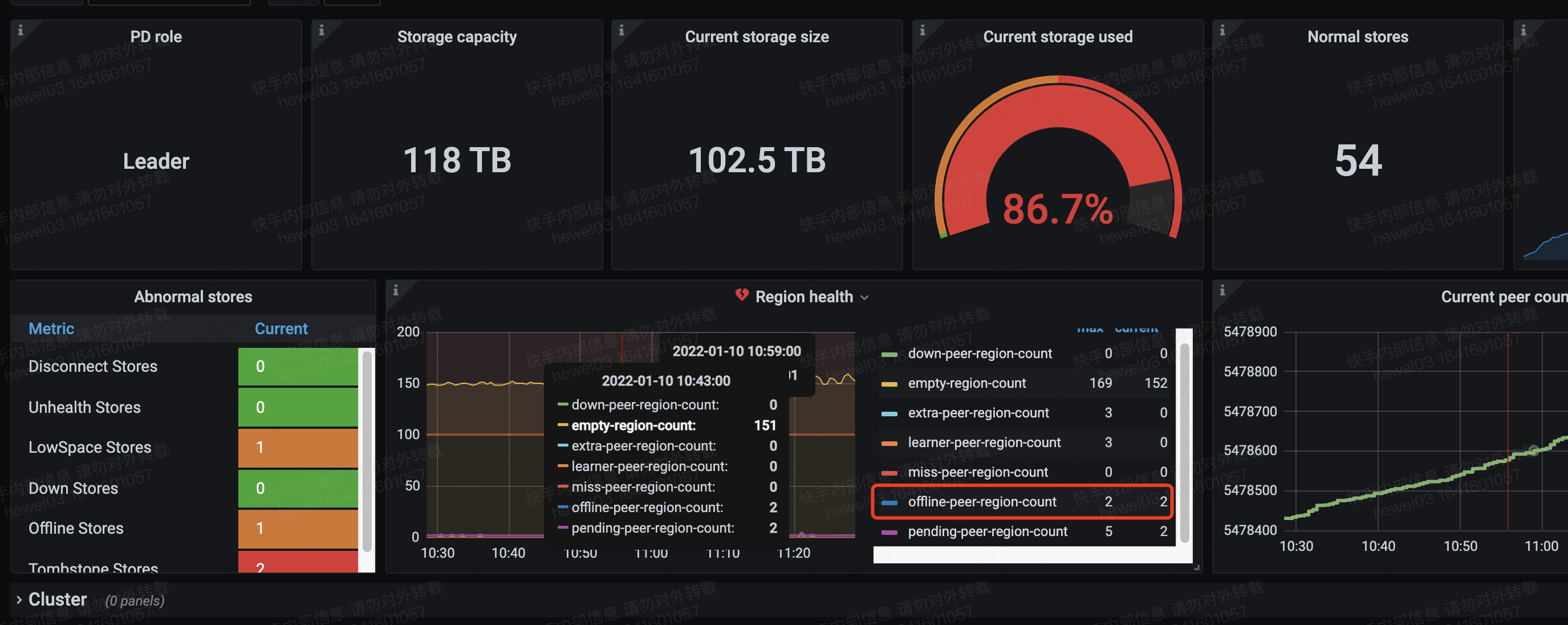
这个是集群二中的,集群一中没有low space。集群二还在先找机器扩容一把看看
KS贺大伟
2022 年1 月 11 日 03:11
6
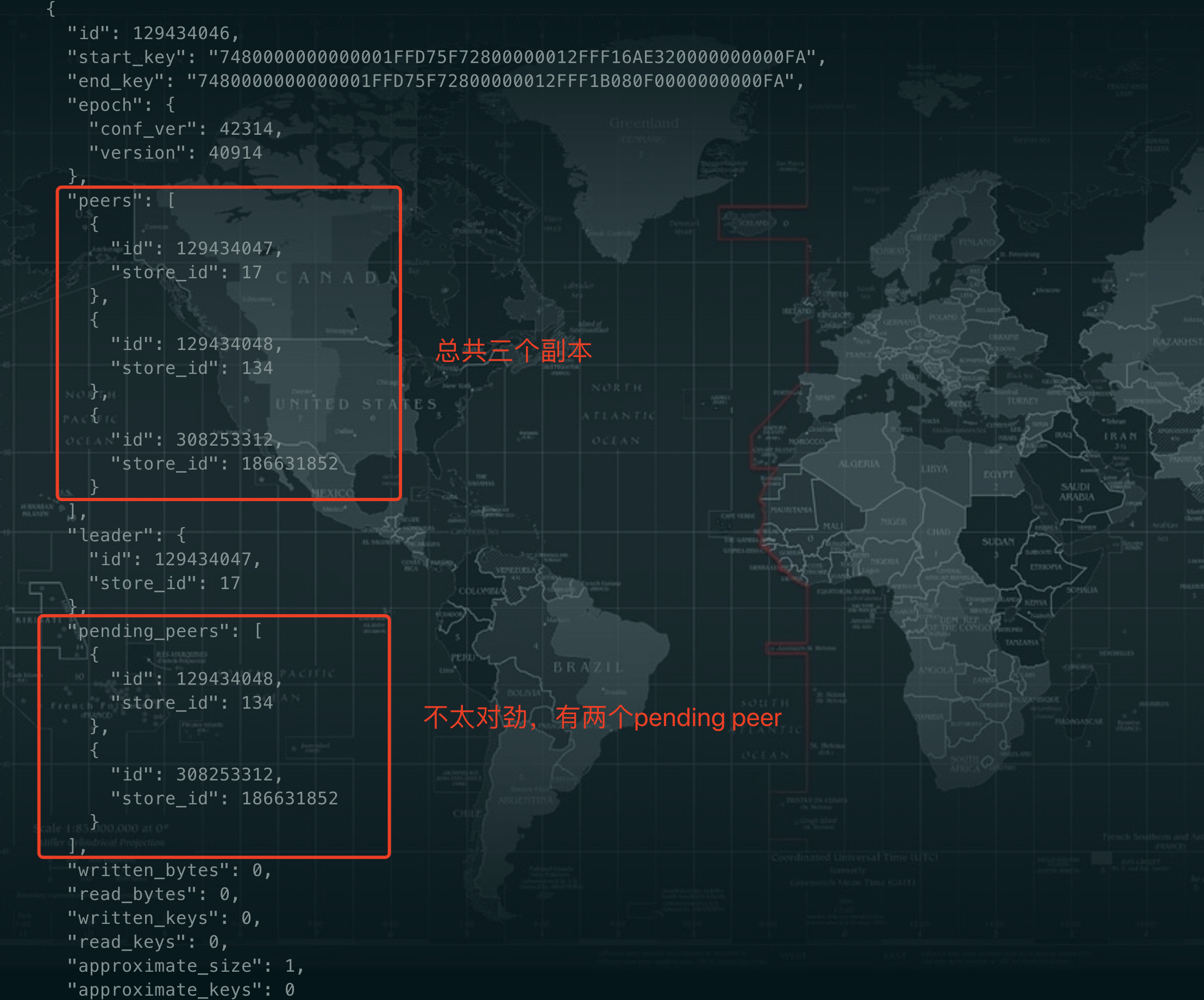
问题原因查到了,是因为这个要下线的tikv所在的磁盘故障了,这个tikv crash了,但是剩余的两个region还有副本在上面,region的信息就是上面截图中的。pending peer所在的store就是故障的tikv。目前已经没有磁盘空间不足的问题
强制设置这个tikv为Tombstone可以解决问题吗?目前看无法自我修复了
2 个赞
林先森cC
2022 年1 月 11 日 06:05
7
现在这个tikv节点还能拉起来吗 可以查下这个tikv节点上的 2个region 的三个副本对应的状态 如果其他两个副本正常 看看能不能move掉这个要下线的的kv的 peer 不行的话加 --force 强制下线吧
KS贺大伟
2022 年1 月 11 日 06:09
8
我按照tikv的日志,强制tombstone 有问题的region,现在tikv拉起来了,看看能不能搞定。
林先森cC
2022 年1 月 11 日 06:14
9
正常可以move掉上面的region的副本 然后在别的tikv节点新增一个副本
operator show // 显示所有的 operators
KS贺大伟
2022 年1 月 11 日 06:45
10
remove不掉了,leader选不出来了,所以才重启这个异常的tikv尝试恢复
KS贺大伟
2022 年1 月 13 日 07:21
12
没有,看来只能unsafe-recover remove-fail-stores 处理了
林先森cC
2022 年1 月 13 日 07:45
13
昨天我这边下线了一个节点也遇到2个region 迁移不掉
林先森cC
2022 年1 月 13 日 08:11
14
如果剩下的region 不多的话最好新建一个表把原来的数据迁移掉 然后删掉原表 把这个region变成空region先 免得操作有问题导致数据不可用unsafe-recover remove-fail-stores这一步要停所有的tikv我记得
KS贺大伟
2022 年1 月 13 日 09:48
15
集群规模太大了,只有两个region有异常,参考https://book.tidb.io/session3/chapter5/recover-quorum.html 感觉可以stop 对应的tikv,手动修复
KS贺大伟
2022 年1 月 13 日 12:19
16
/tikv-ctl --data-dir /data/deploy/tikv20171/db unsafe-recover remove-fail-stores -s 186631852,134 -r 129434046Result::unwrap() on an Err value: Os { code: 2, kind: NotFound, message: “No such file or directory” }’, cmd/tikv-ctl/src/main.rs] [":121compaction guard is disabled due to region info provider not available"]RUST_BACKTRACE=1 environment variable to display a backtrace
这是什么问题??
KS贺大伟
2022 年1 月 13 日 12:22
17
现在的情况是以上两个有问题的region,根据他们所在tikv上get到的raft信息,store 134上没有这两个region,故障的store已经故障了,所以导致无法选举。
林先森cC
2022 年1 月 14 日 01:57
18
重启了那台下线中的tikv节点 调度正常了 region移动走了