INFORMATION_SCHEMA
手动清理异常的region在store 5上的down peer之后,store 5终于tombstone
region store 5这个信息不准确,造成干扰【吐槽一下】
1 个赞
哈哈哈 有时候 会这鸭子 清理前最好先查下这些没被清理的region_id的副本状态
select * from TIKV_REGION_PEERS where region_id in(select region_id from TIKV_REGION_PEERS where store_id = 5);
可以看到region STATUS是不是在pending 是否是三副本 是否都有leader 防止只有两副本的被你直接清理掉造成region不可用
这个集群应该是历史上有过非正常下线操作吧,否则一般 region 和 region store 数据应该是一致的。
是的,这个集群曾经出过问题
之前遇到过,先给集群扩容下存储,存储不平衡会影响下线速度。 你那集群存在REGION 副本数丢失 或者REGION 没有LEADR
要彻底修复集群异常:估计整个集群TIKV都得重新上线下线
借这个帖子继续咨询,发现集群(V4.0.14)下线遇到两个问题:
-
问题一
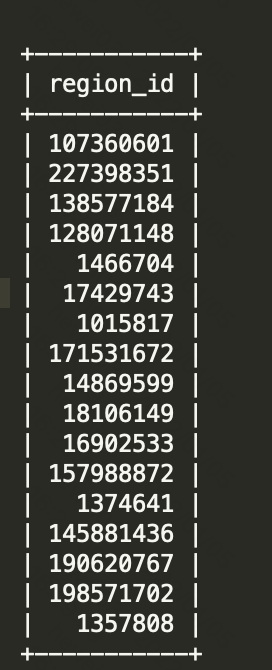
剩余一个region没有因为下线tikv而迁移,查询store的region信息和region的信息,这个region
有一个down peer,然后我主动remove peer,发现没有生效,去region的leader所在的tikv上查看日志,发现检索三天的日志都没有发现这个region的任何信息,其他副本所在的store的日志中也没有什么任何信息
-
问题二
另外一个集群(v4.0.14)下线tikv,发现剩余两个region无法完成下线
有问题的region信息如下:

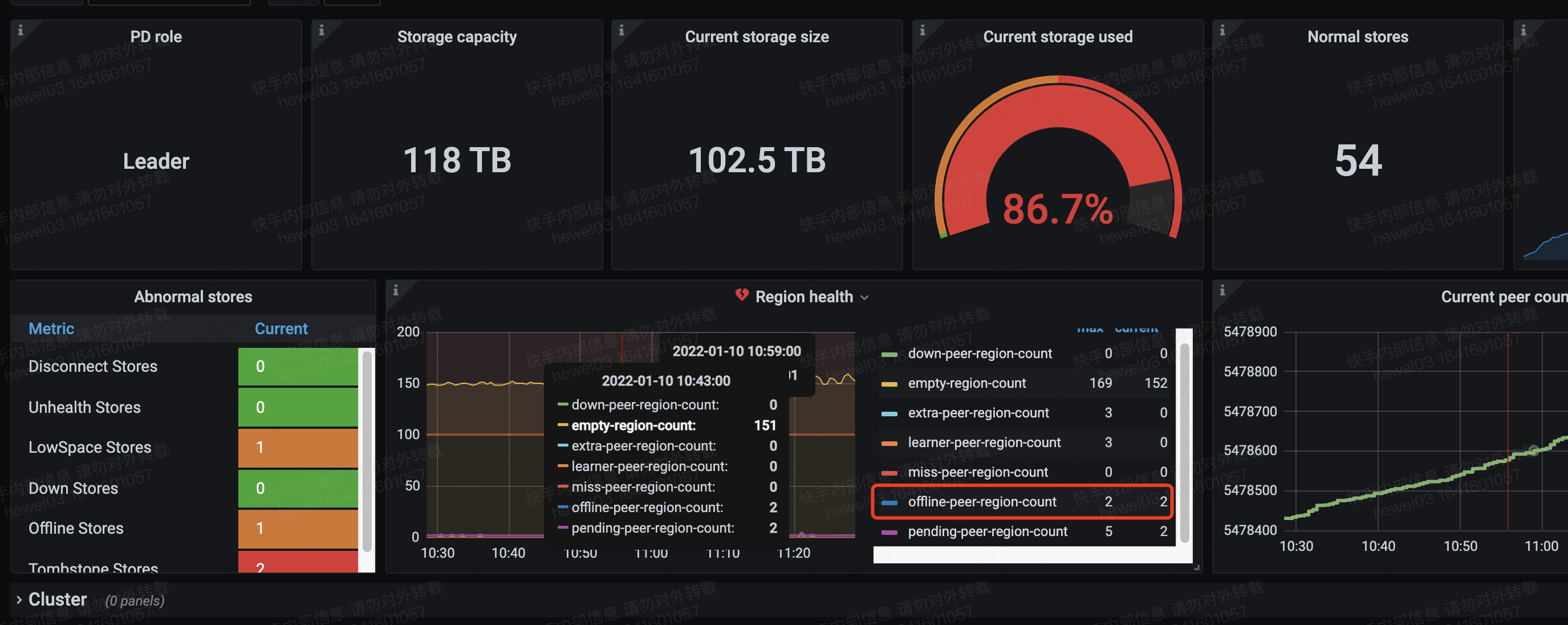
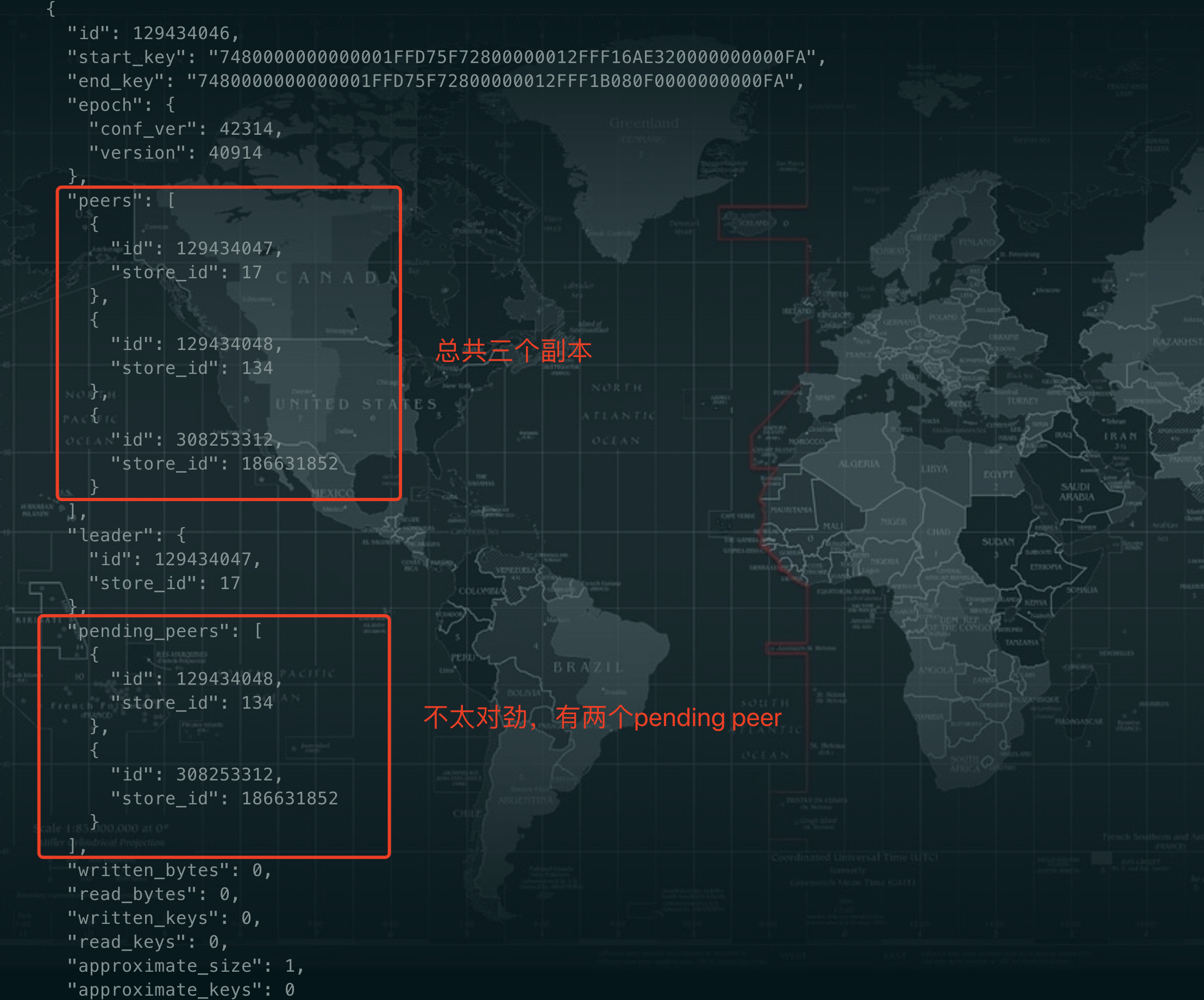

不知道如何处理
建议你 新开个帖子 关注度较高 没下线成功的region 可以根据region_id在 pd leader节点的日志看下 有没有啥调度失败的日志
或者看下tiup ctl pd -u http://pd_ip:pd_port -i
» operator show
看下正在调度的信息有没有这个region
顺便看下库里TIKV_REGION_PEERS和TIKV_REGION_STATUS表里 没下线成功的region_id的相关信息
好的,谢谢
新帖子:store offline异常
建议扩下存储,或者把存储容忍度调整下
不认为是扩容可以解决问题,因为我查看了tikv的日志,已经不能正确的执行删除和添加peer的操作了,从日志中看leader已经选不出来了。
调整存储容忍度是什么意思?
问题2应该要调整下tolerant-size-ratio 这个参数值,LOWSPACE先去掉,还是认为你存储不够导致的
问题1应该是你当时集群异常引起的,数据分裂引起的,之前他们给处理,找到节点后对应的删除CACHE的,这个建议你跟官方确认下,对于无法下线的,我是那么操作(之前出过异常就是各种操作:重启TIKV/删除region的缓存,转移LEADER等等)
仅供参考:https://blog.csdn.net/weixin_36135773/article/details/116274916
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。