为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【 TiDB 使用环境】
v5.3.0,tikv和tiflash混合部署
【概述】 场景 + 问题概述
numa来绑定后,其中一个tikv节点频繁重启,日志除了以下报错信息外没有其他日志
[server.rs:1052] [“failed to init io snooper”] [err_code=KV:Unknown] [err=“"IO snooper is not started due to not compiling with BCC"”]
查询系统日志为进程内存溢出被kill,在解除numa绑定后恢复正常,请问这是什么原因
【背景】 做过哪些操作
【现象】 业务和数据库现象
【问题】 当前遇到的问题,参考 AskTUG 的 Troubleshooting 读性能慢-慢语句
【统计信息是否最新】
【执行计划内容】
【 SQL 文本、schema 以及 数据分布】
【业务影响】
【TiDB 版本】
v5.3.0
【附件】 相关日志及监控(https://metricstool.pingcap.com/)
logs-tikv_192_168_14_24_20171.zip (9.5 MB)
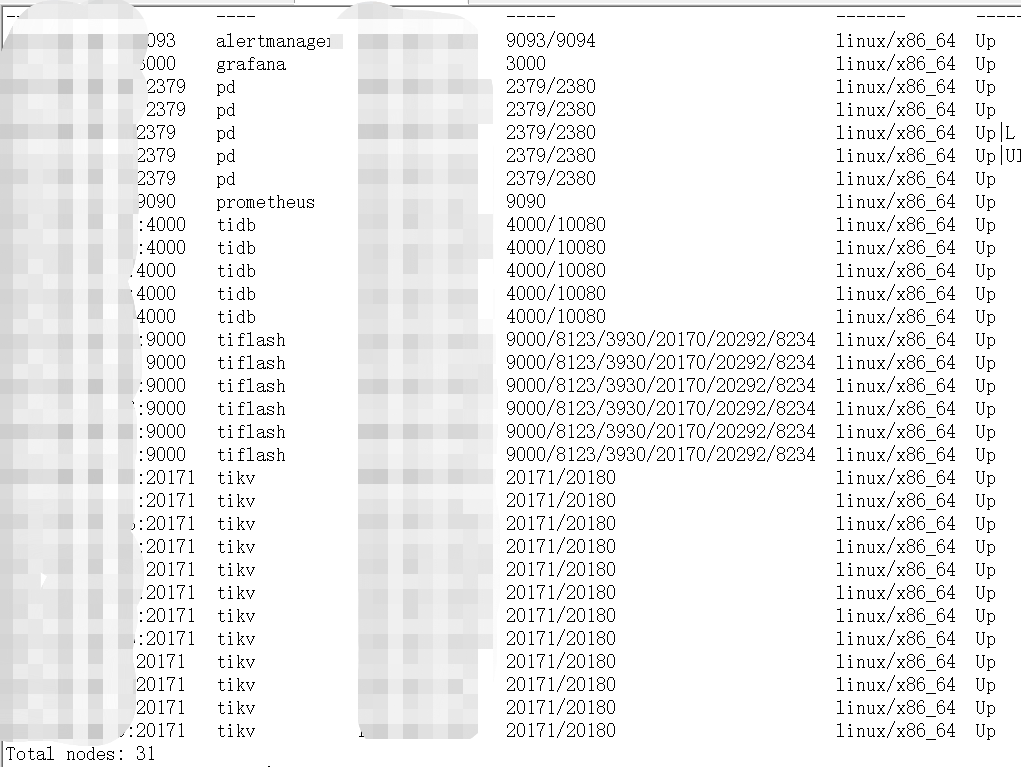
- TiUP Cluster Display 信息
- TiUP CLuster Edit config 信息
- TiDB-Overview Grafana监控
- TiDB Grafana 监控
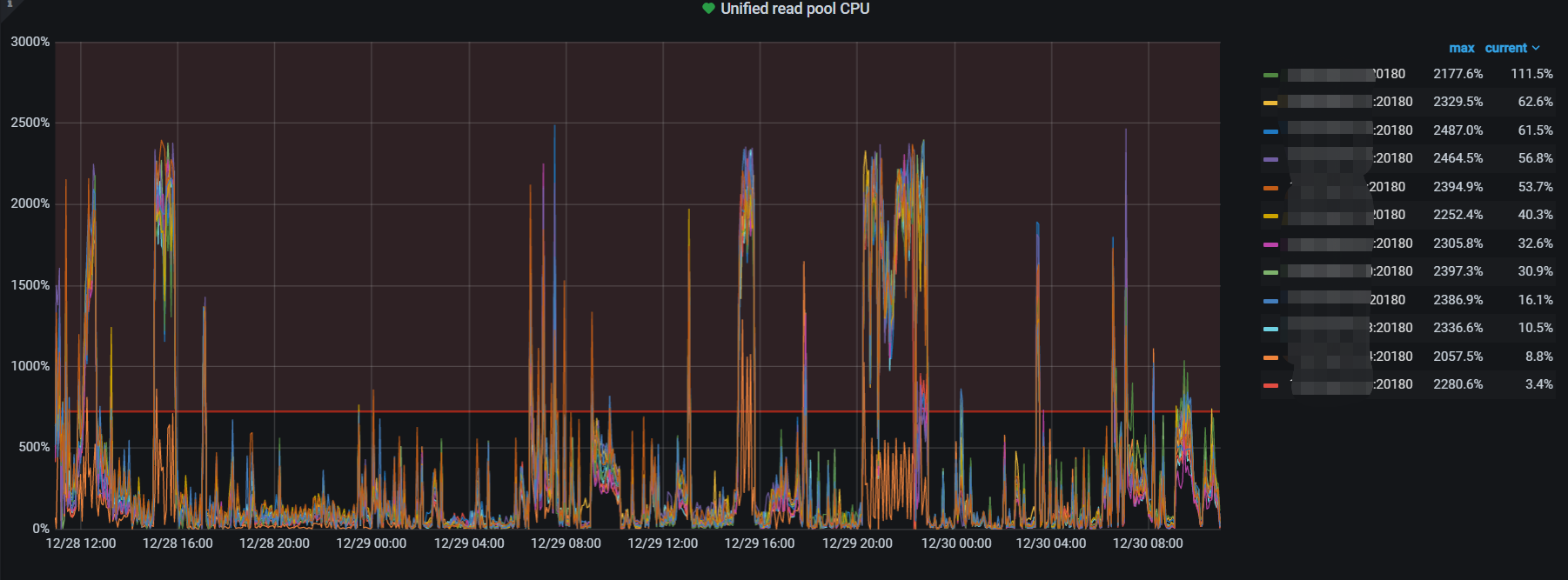
- TiKV Grafana 监控
- PD Grafana 监控
- 对应模块日志(包含问题前后 1 小时日志)
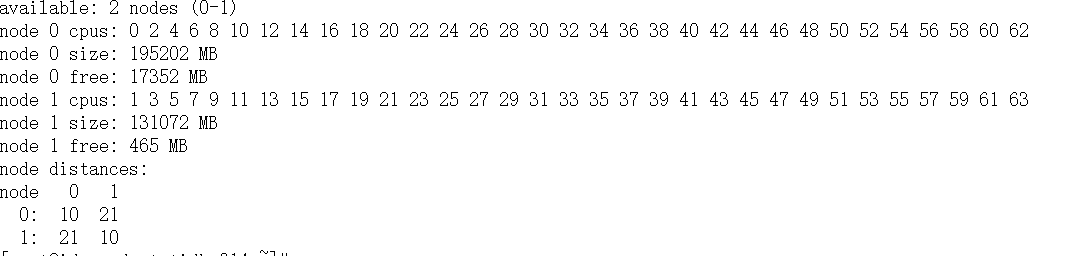


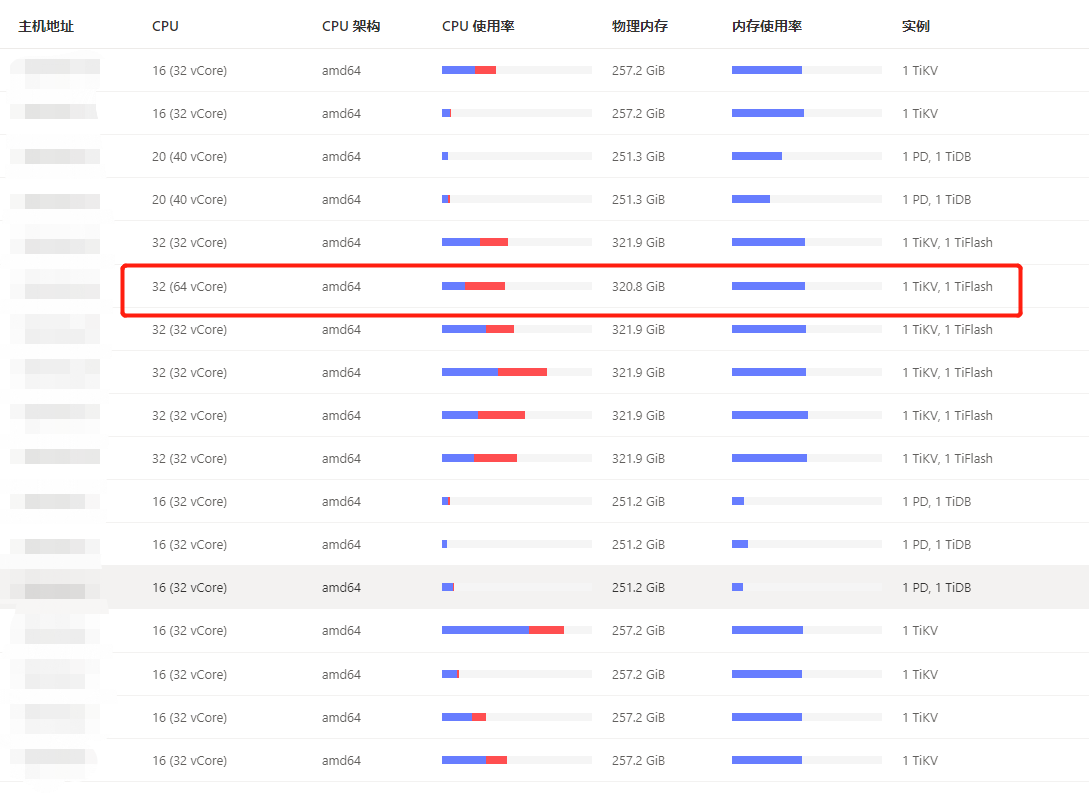
 之前绑的确实是1,现在去掉了
之前绑的确实是1,现在去掉了