作者:傅少峰,新东方数据服务团队(数据库和大数据)负责人,TiDB User Group Ambassador
前言
我从 2016 年开始关注分布式数据库,但分布式数据库其实很早就被Google 提出来了。Google 是全球的技术标杆和技术论文产出工厂,从几年前的 BigTable 到现在的 Spanner,引领了大数据和数据库的发展趋势,随着时间的推进 Google 又拉开了 NewSQL 的大幕 。近几年,国内外出现了很多优秀的 NewSQL 产品,如:Spanner、CRDB、TiDB、OceanBase、TBase、GaussDB 等。
本文主要和大家分享三个部分的内容:
- 新东方集团的基础服务架构介绍
- 业务前台 APP 系统平滑上迁 TiDB
- TiDB 如何承载业务中台交易系统
新东方基础服务架构
我简单介绍一下新东方。新东方是国内规模最大的综合性教育集团,包括基础教育、在线教育、外语培训等。2018 年下半年集团提出三化建设。目前我们对分库分表的核心业务,例如报名、一卡通、支付等业务系统都在进行中心化建设,把全国 120 多所学校的业务数据上迁到新东方集团,由我们数据服务团队做集中式管理。
下图是新东方集团的云服务体系。我们是混合云架构,包括私有云(虚拟化和容器化)、公有云、物理机。虽然是混合云架构,但 DC、IDC、公有云已经构建成万兆环网,实现了跨机房数据库部署的基础条件。


我们对中心化建设的业务数据库有以下 4 个要求:
- 高性能
- 高可用
- 易扩展
- 易运维
近一两年业务数据大量增长和业务数据集中上迁,所以扩展性是我们首先要考虑的。于是我们就开始了 NewSQL 的调研和选型。期间调研过 OB、CRDB 、TiDB,由于 TiDB 是完全开源的分布式数据库,文档和社区比较友好,高度兼容 MySQL,并且是国产数据库,所以我们最终选择了 TiDB。
TiDB 在新东方业务前台 APP 系统的应用

TiDB 在新东方试用的第一个项目是集团的 OA 系统,该系统大概有 7W+ 用户使用。经过多年积累,系统和流程非常复杂。当时 OA 系统遇到的问题是流程办理步骤表数据量过亿并且数据分布不均,业务需要进行大表的关联查询。
初期我们想使用 HBase 分布式架构解决单表数量过大问题,因为这块业务对事务没有要求,但在 POC 时发现研发成本很高,后来我们选择了 TiDB。
在 OA 系统试用时候我们用的是 TiDB 2.0 版本,当时该 TiDB 版本在倒排序性能相对较差,无法满足我们业务对倒排序场景的要求,最终我们选择了传统的分库分表解决方案。现在 TiDB 3.0 版本的稳定性和性能都上来了,我们考虑将 OA 系统从 MySQL 迁到 TiDB。
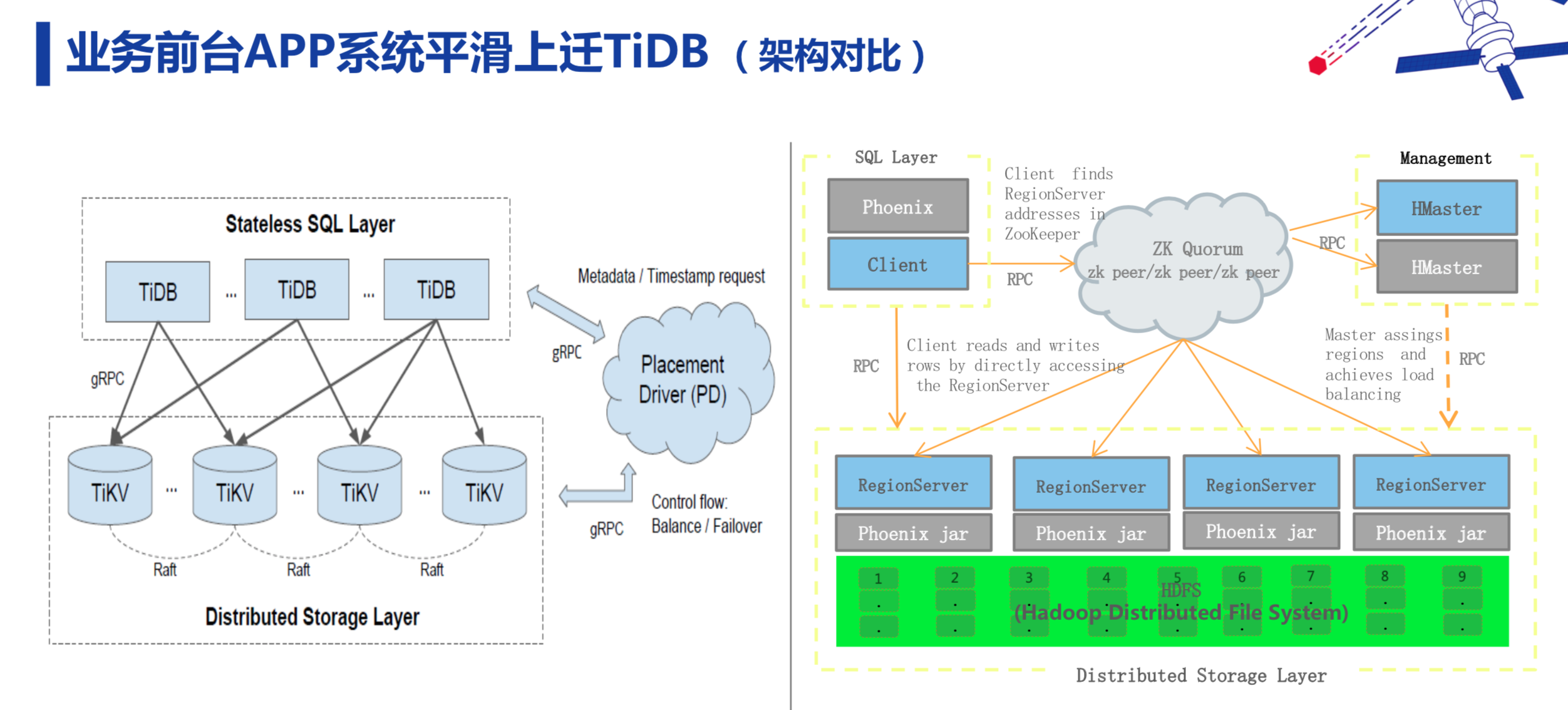
新东方 APP 系统这块没有复杂的业务逻辑,过去我们的解决方案是 MySQL+ MHA + HAProxy,现在是 TiDB + HAProxy/ Nginx。 从 MySQL 迁移到 TiDB 的过程,我们主要通过 TiDB 的生态工具 Mydumper、Loader、Syncer,把数据实时传到下游 TiDB,把 TiDB 作为 MySQL 的一个从库,然后做性能和功能验证。虽然数据可以平滑过去,但是业务不一定,所以我们迁移以后遇到了 TiDB 不支持大小写敏感、自增 ID 、外键、触发器、索引优化等问题。这里详细说一下索引优化的问题。我们从 MySQL 直接迁到 TiDB,索引也需要和 TiDB 相兼容。在 TiDB 中,A 和 B 这两个条件,A 加索引,B 也有索引,但只能走一个索引,这也是迁移过程中我们要考虑的。
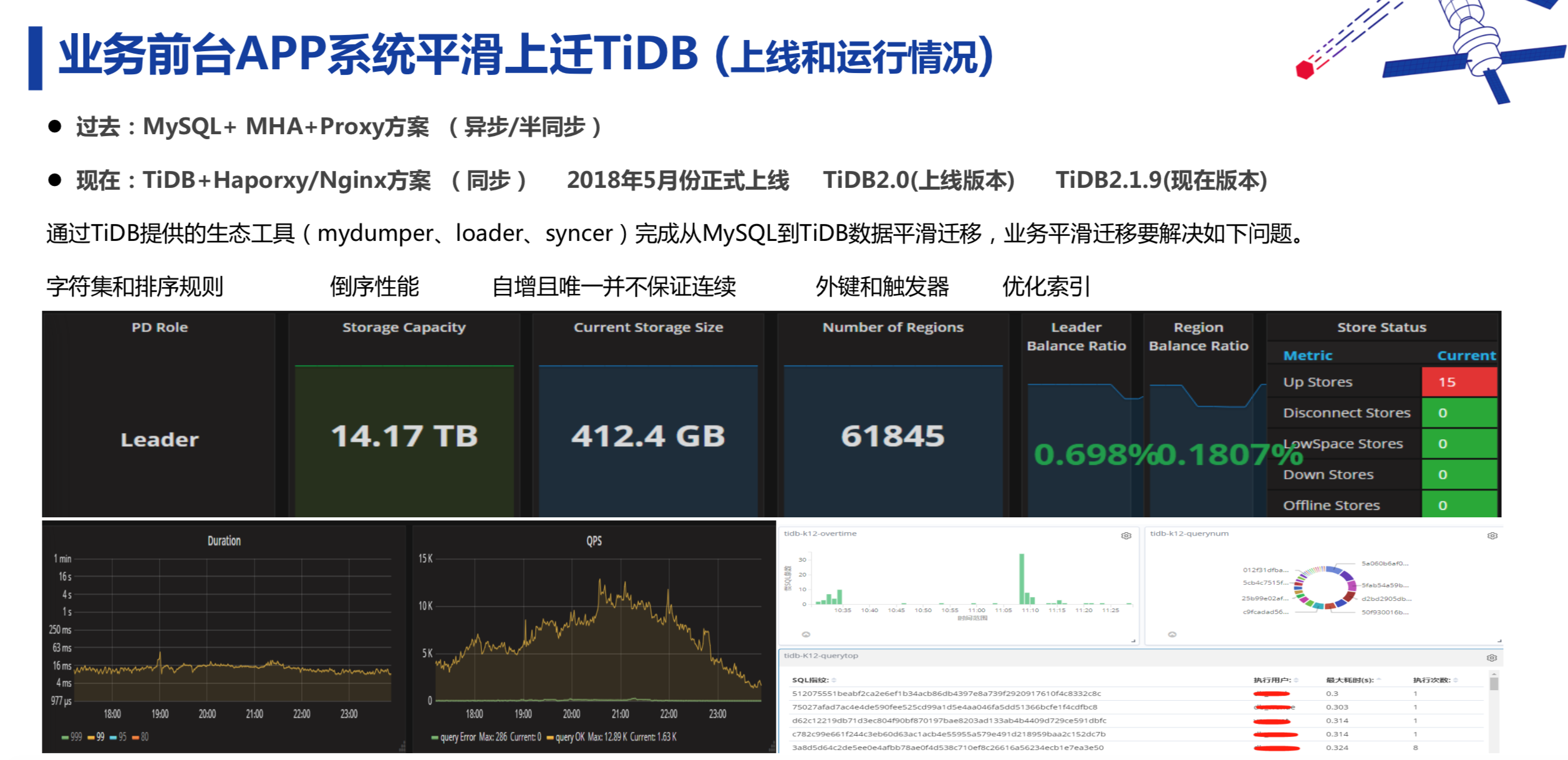
如果上述说的几个问题都解决了,业务就可以很平滑地进行迁移。我们 2018 年年初开始测试 TiDB, 2018 年 5 月份正式上线。上线后一年半以来,没有出现数据丢失和数据不一致的问题。运行期间,虽然出现过数据库负载很高导致响应变慢的情况,但没有出现数据库宕掉的问题,还是相对比较稳定的。上线时数据量在 400G +(目前 900G+),节点数 15 个,一直在线平滑滚动升级。
TiDB 在新东方业务中台系统的应用
刚才讲的是我们的一个前端业务,现在来讲讲我们的业务中台。
以前我们核心交易系统就是报名系统,它承载了新东方线上和线下所有报名交易业务,就像一个功能庞大的 ERP 系统。2018 年集团提出三化建设,我们开始对现有的核心报名系统进行重构,完成业务中台的建设。目前我们业务中台包括八大中心,其中三个中心应用了 TiDB 数据库:报名中心、行课中心、支付中心。
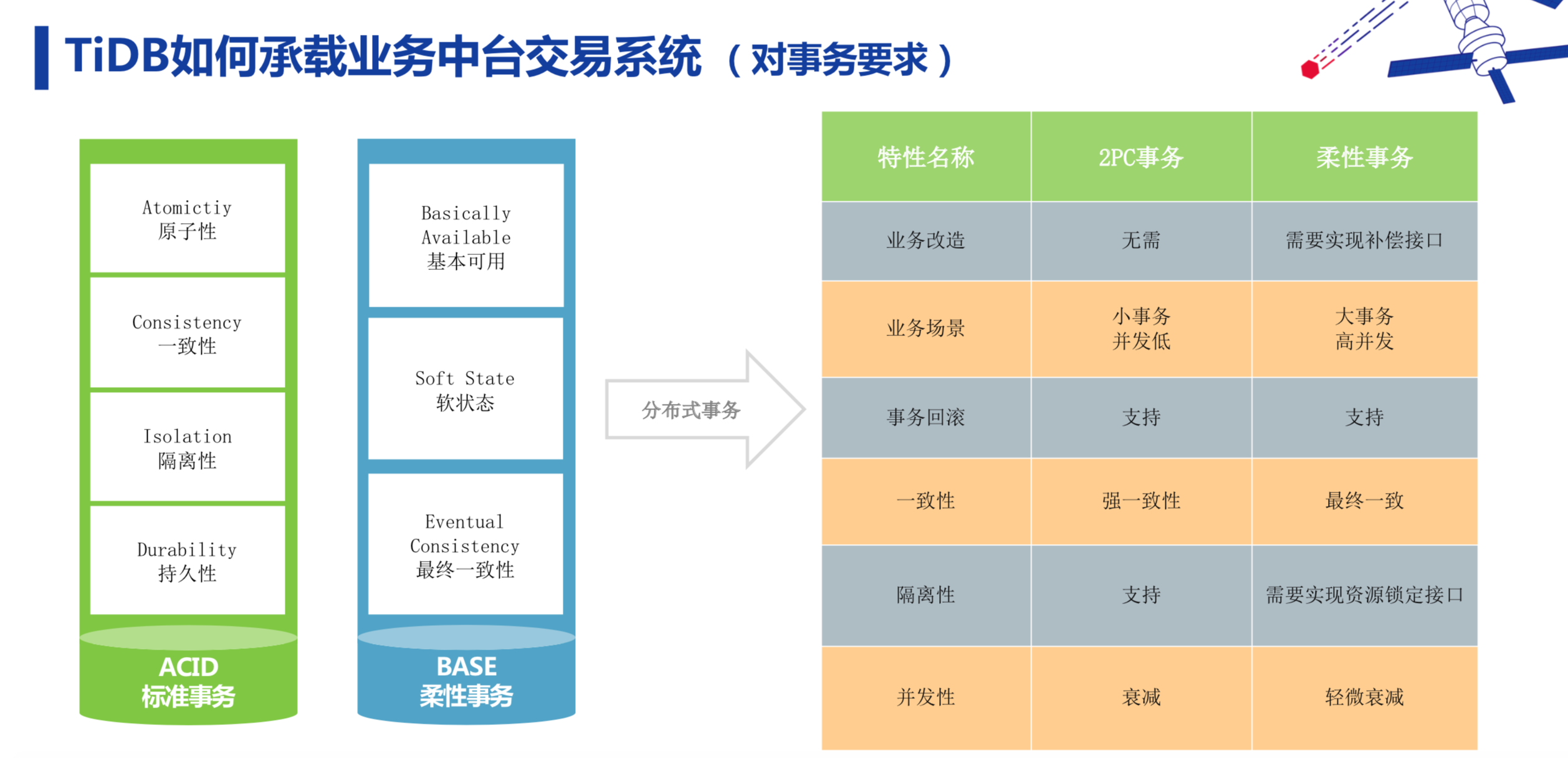
首先来看看报名中心。报名中心对事务有严格的要求。刚才的前台 APP 业务对事务没有要求,事务到底是强一致性,还是最终一致,不是很重要。但是报名场景要求学生家长报名交了钱要马上可以查到报名信息,如果只是最终一致,就不能得到实时反馈,使用体验不好。所以这块我们要求一定要保证事务的强一致性,达到 ACID 事务标准。我们老报名系统的数据库是基于 SQL Server 的,报名中心是完全重新基于分布式数据库 TiDB 开发的。
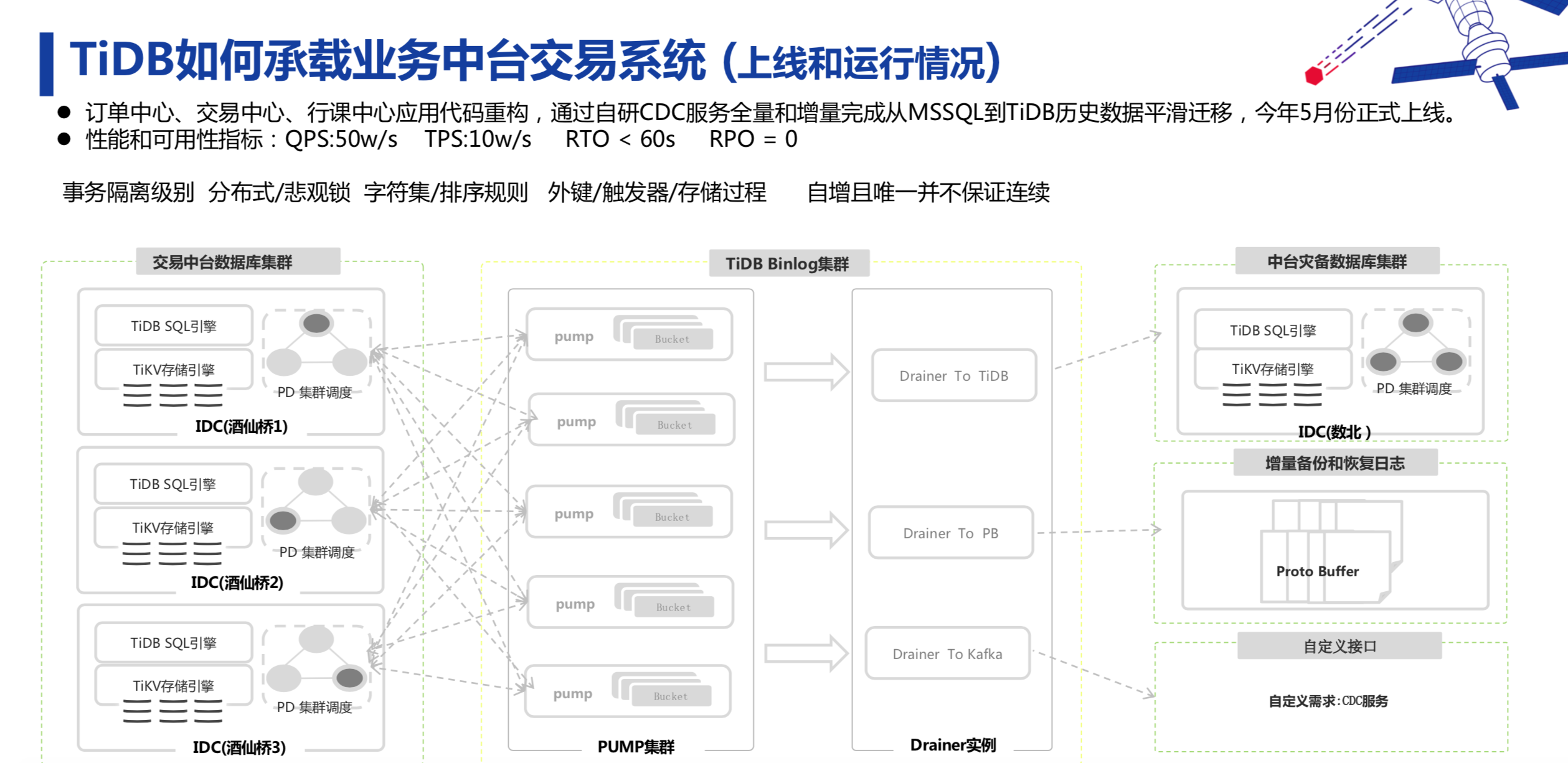
目前我们的架构是多中心部署的,但没有异地,都在北京。我们在不同的机房做了部署,即使后期需要再迁新机房,也可以按照 lable 把每个机房的 TiDB 进行动态迁移,加入新机器动态替换集群。
但也有个问题:万一机房出故障,数据怎么办?这时我们用 TiDB 的第二套集群灾备方案,同步到下游的灾备集群里,这个灾备集群也在动态提供 AP 业务查询服务。
目前报名中心还没有完全实现 TP 和 AP 业务低耦合,由于之前的 TiDB 还没有 TiFlash 列存,无法很好地实现 HTAP 业务场景资源物理隔离和互不影响。目前 TiDB 集群如果有大量的 AP 业务进行导数据或即席查询操作,会影响整体 TP 业务的 SQL 响应时间。所以我们在 TiFlash 正式 GA 前,做了一个和 MySQL 底层架构一样的 Binlog 服务,往下游的 TiDB 集群进行同步。但都在异步的情况下,MySQL 在毫秒级别就同步完了,TiDB 一般同步延时在 1~2 秒。
目前我们在报名中心开发过程中遇到了一些问题。
首先是事务的隔离级别, SQL Server 是 RC 模式,但 TiDB 是 SI 模式。
还有一个就是悲观锁,这在交易系统中是非常重要的。TiDB 不适合用于锁库存、秒杀的场景,因为它冲突率比较高。作为替代,可以使用 select for update。但事务实际是被排成队列以串行的方式执行的,性能不高。我们使用 Redis 缓存级的分布式锁解决了这个问题。Redis 缓存做到串行化处理是非常快的,并且损耗不是很大,也有着较大的性能优势。如果当时 TiDB 发布了悲观锁的功能,就可以通过高并发的形式,放到分布式里去。值得欣慰的是,TiDB 3.0 版本已经支持了悲观锁功能。另外还有字符集和排序规则、外键、触发器和存储过程,以及自增且唯一并不保证连续的问题。


总结
我们整个 TiDB 集群目前的规模不是很大,今年计划是上五到六所学校。因为原来的老数据库架构数据链路比较长经常出现数据回传集团延时问题。我们使用 TiDB 进行数据集中化管理,再不会出现学生家长报完名以后由于数据回传延时造成的不能立即进行转退班业务办理情况。
一切脱离场景谈架构都是耍流氓,要根据场景选择正确的架构才能起到降本增效。对 SQL 响应时间要求很高,但数据量很小的业务场景,就不太推荐使用 TiDB了。
对当前 2.1 版本,我们比较关心 Raft Store 单线程的问题,写入有瓶颈。我们之前吃过亏,开始没有关注这个问题,结果写入后压测上不去,CPU 也打满了。TiDB 3.0 为 Raft Store 做了线程池,也有了静默 Region 功能以及分区、视图、窗口函数这些功能,对我们来说是一个好消息。我们最近在做性能压力测试,再迭代一到两个版本,我们后续计划把所有 TiDB 版本都升级到 TiDB 3.0,充分利用 TiDB 3.0版本带给我们的新功能和高性能。