为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】:3.0.9
- 【问题描述】: TiDB-Server有64GB GC有10分钟的限制; mem-quota-query=5GB 同时只有一个查询,TiDB-Server能占用到50GB,提示超过内存限制; 然后还没有进行GC前,再查询一次,TiDB就OOM被linux kill掉重启了
如何防止重启
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。
为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
如何防止重启
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。
恩,这个设置成为cancel,但连续执行sql,第一次会触发cancel,第二次tidb就整体oom了
如果等待10分钟下次GC之后,再执行就行
![]()
![]()
所以这个问题怎么解决呀: 10分钟内,连续执行sql,即使有cancel配置,也会让tidb-server OOM被kill掉
请问下,是什么样的 sql ,可以根据执行计划看下是否还有可优化空间
另外这个问题,猜测是可能存在多个同样的大 SQL,其他的 SQL 还在做运算,数据还没有全部到内存里面,导致内存逐渐涨到内存撑满。可以从业务层面排查下是否有其他 sql 并发执行导致 OOM。
是OLAP场景的sql语句,十亿级别表的group order,在没有用tispark和tiflash前,先用tidb-server查询的
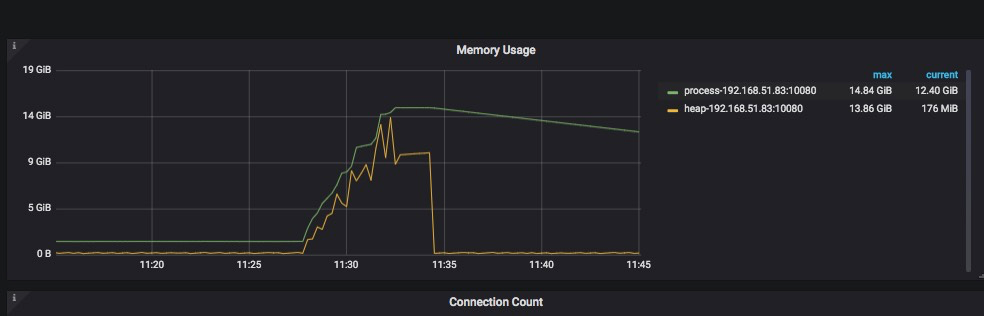
我们测试后的时候确认同一时刻只有一个人在操作,一个sql在运行,现象是: 一次gc内(十分钟内)执行两次,第一次提示cancel,第二次就会OOM被kill 如果间隔10分钟执行两次,就不会OOM
目的是: 在保证同一时刻只有一个sql运行的情况下,如何保证tidb-server不重启
场景:
语句参考: select jra.entity_type, jra.entity_value, count(distinct jra.xzqh) as xzqh_count, count(distinct jra.jq_id) as jq_id_count, MIN(jra.jq_id) as jqbh FROM jingqing_related_all jra group by jra.entity_type,jra.entity_value order by xzqh_count desc,jq_id_count desc limit 1000
这个和 TiDB 中的 GC 没有关系,可能和 Go 的 GC 有关系,但是 Go 的 GC 是很快的,如果操作完成,应该会在秒级别释放空间。所以要明确执行间隔,第一次 cancel 以后,第二次什么时间执行的。
这个是在互联网我们的测试环境,执行了一个sql
select bjsj, SUBSTR(JQBH, 1, 3), count(distinct JQBH) from delta_jingqing_billion.jingqing_table group by bjsj, SUBSTR(JQBH, 1, 3);
OK,最好将完整的测试情况反馈出来,比如操作时间点,现象和返回的结果,监控的 memory 完整的内存。
您好:
我这边测试了一下,看到同一个session里,同一条sql是可以连续被cancel的,请问您这边可以复现问题吗?
mysql> select a.id,b.id,count(*) from sbtest1 a, sbtest1 b group by a.id,b.id order by a.id limit 10; ERROR 1105 (HY000): Out Of Memory Quota![conn_id=5]
mysql> select a.id,b.id,count(*) from sbtest1 a, sbtest1 b group by a.id,b.id order by a.id limit 10; ERROR 1105 (HY000): Out Of Memory Quota![conn_id=5]
mysql> select a.id,b.id,count(*) from sbtest1 a, sbtest1 b group by a.id,b.id order by a.id limit 10; ERROR 1105 (HY000): Out Of Memory Quota![conn_id=5]
是在中控机/conf/tidb.yml 修改了 oom-action = “cancel” 和 mem-quota-query ,并且滚动重启了tidb吗?