MyronWang
(Myron Wang)
1
【 TiDB 使用环境】
【概述】 场景 + 问题概述
【备份和数据迁移策略逻辑】
【背景】 做过哪些操作
【现象】 业务和数据库现象
【问题】 当前遇到的问题
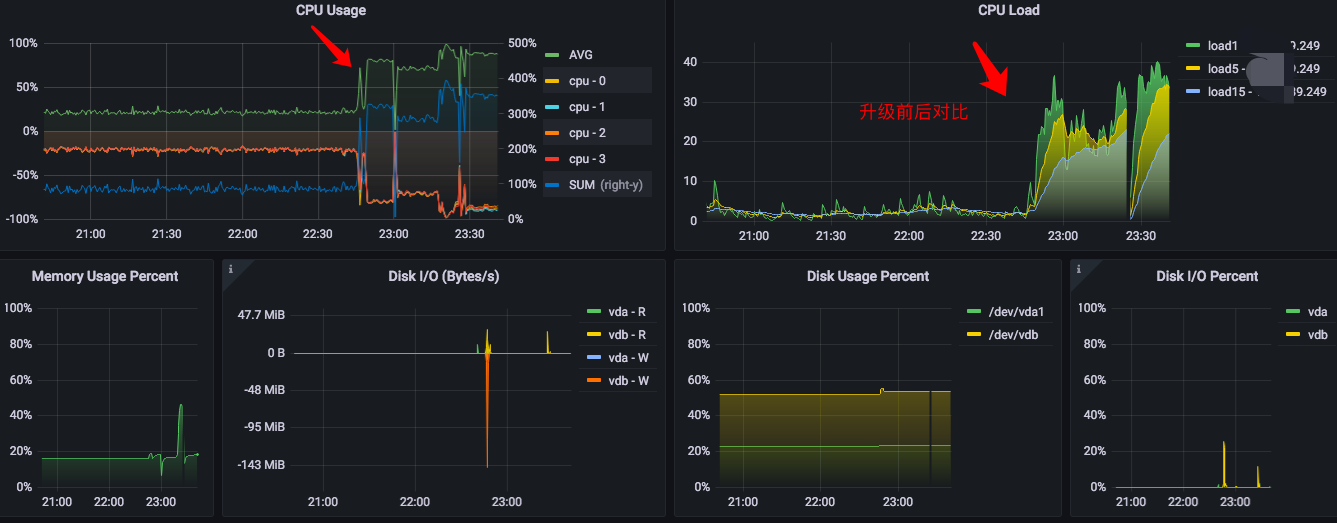
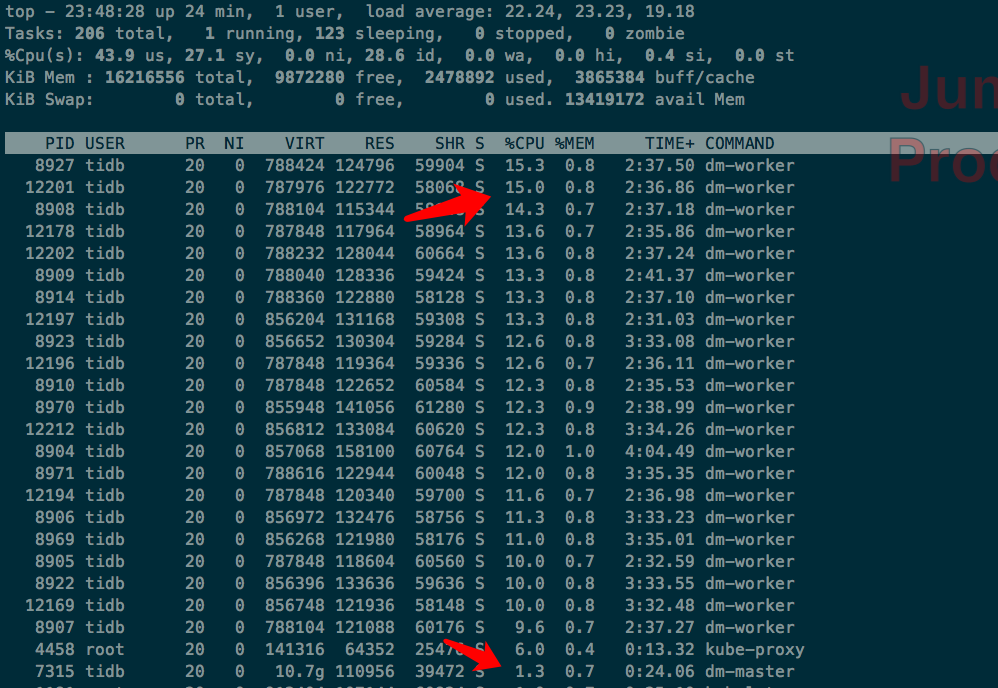
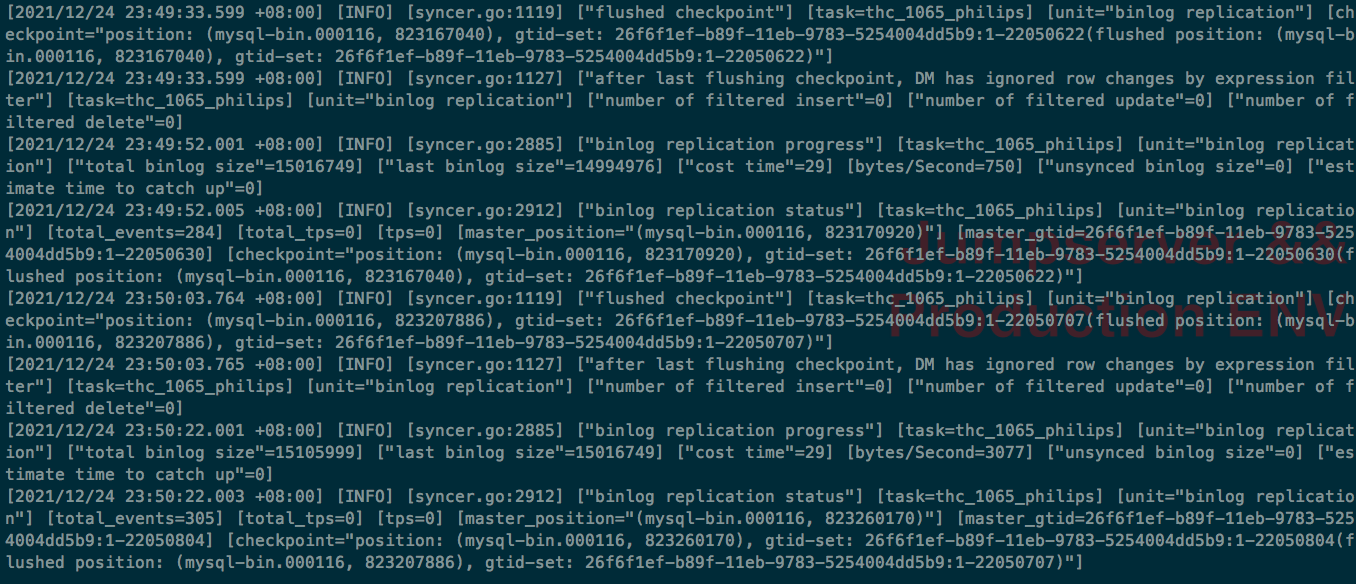
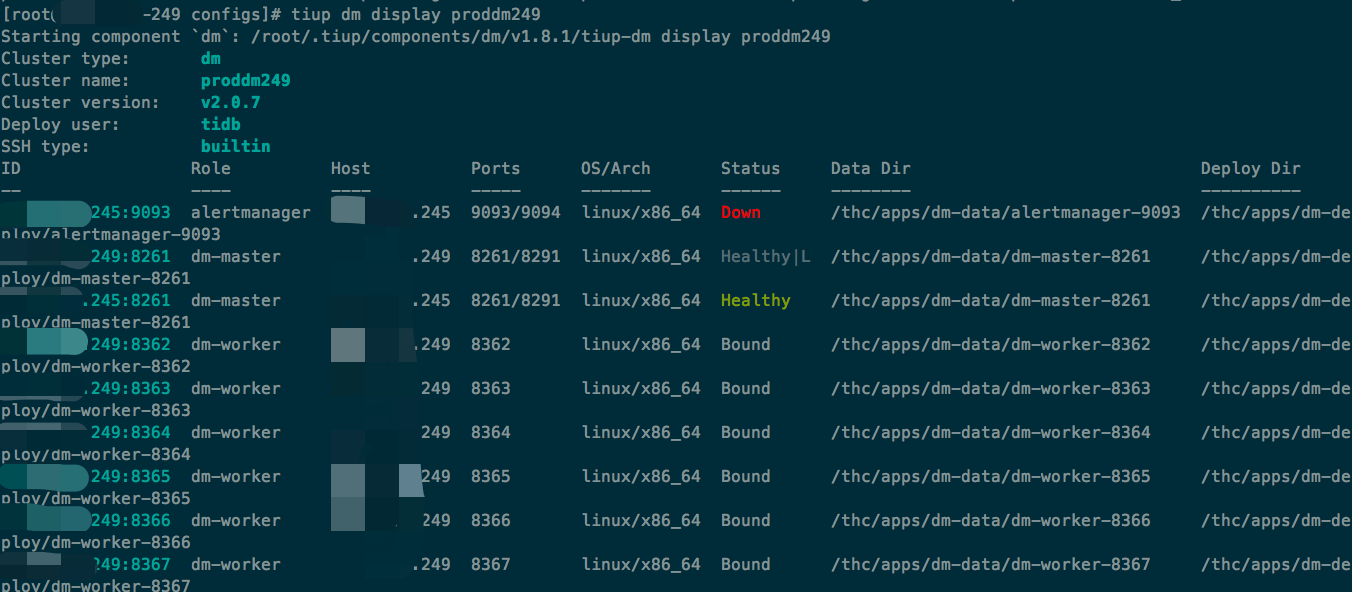
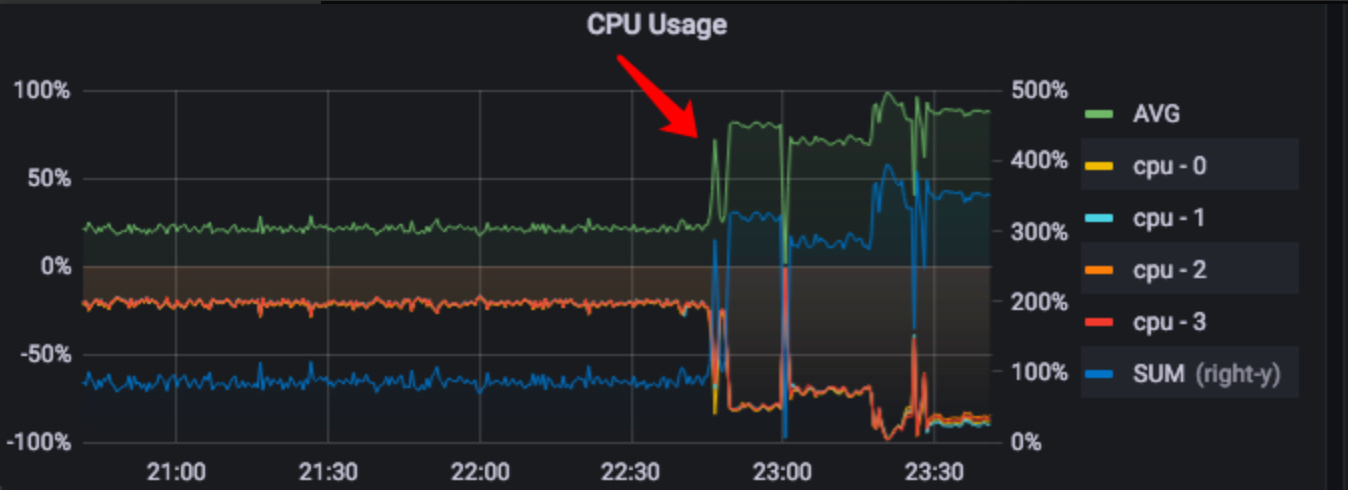
dm 集群从 v2.0.1 升级到 v2.0.7 后,发现 dm-worker CPU 占用率很高,但这个时间段根本没有任何数据在同步,看日志全部是正常的 binlog replication status 检测,这个感觉太奇怪了。
【业务影响】
【TiDB 版本】
TiDB v5.2.0
DM v 2.0.7
下面是监控图:
从这里可以看到升级时间,就是上面监控图指的地方(期间重启过集群,也没效果)
dm-worker 占用的 CPU 普遍高于 dm-master,关键是当前时间段,dm-worker 没有数据同步。
任意一个 dm-worker 都是类似日志(我们这边晚上基本没业务,而且现在这个时间段是维护期)
1 个赞
MyronWang
(Myron Wang)
2
跑了一晚上,CPU 消耗还是“很稳定:slightly_frowning_face:”
2 个赞
lance6716
(Lance6716)
3
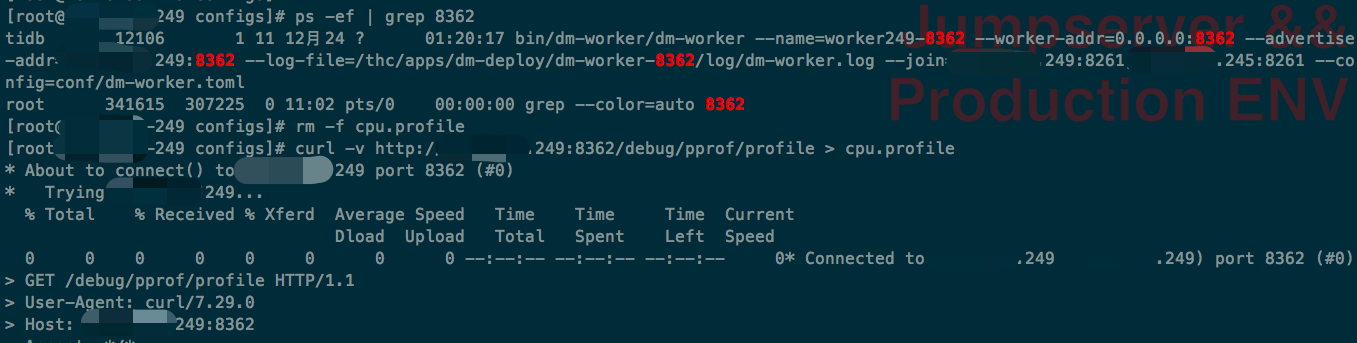
Hi,可以抓一下这个 worker 的 CPU 火焰图吗
curl -v http://<worker IP>:<worker port>/debug/pprof/profile > cpu.profile
然后在这里上传一下
2 个赞
MyronWang
(Myron Wang)
4
你好,我的场景有点特殊,一台机器上同时跑了数十个 dm-worker,我选择其中一个抓取吧。(两个物理节点,上面跑了50+个 dm-worker)
cpu.profile (4.4 KB)
2 个赞
lance6716
(Lance6716)
5
这个 worker 没什么异常的。可以看一下哪个是消耗 CPU 最高的 worker
2 个赞
MyronWang
(Myron Wang)
6
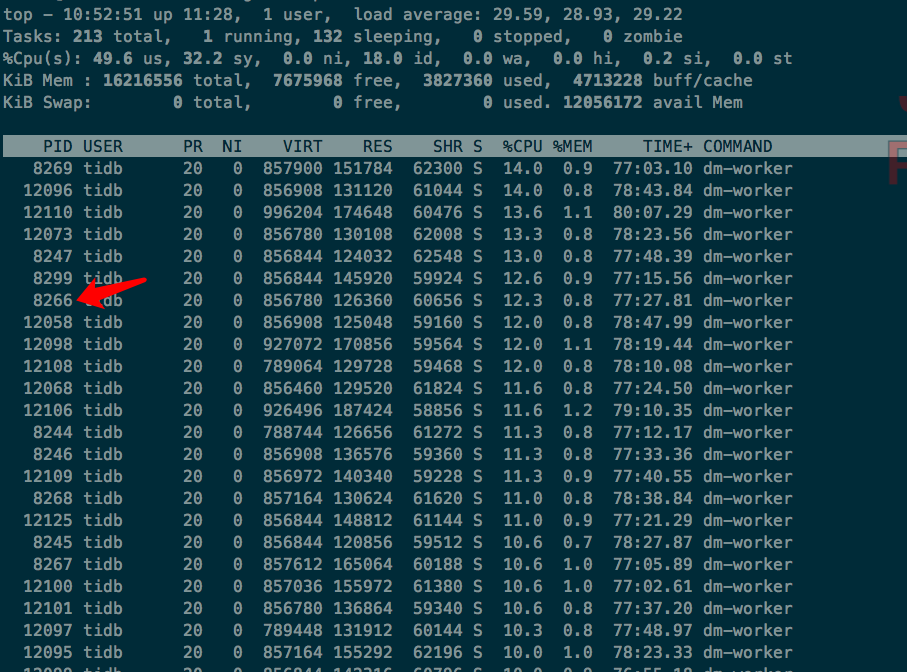
我拿的 8266 对应的 dm-worker 的,其他的也都差不多。那这是正常现象么:joy:
2 个赞
lance6716
(Lance6716)
7
火焰图看这个是 free 的 worker 吧,可以抓一下绑定了上游 source 的 worker 看看
2 个赞
lance6716
(Lance6716)
9
目前看的话,是 go 的 runtime.findrunnable 有些消耗 CPU。您这边 4 个核 50 个 go 进程的话可以试着调整一下 GOMAXPROCS 等 runtime 参数
2 个赞
MyronWang
(Myron Wang)
10
我这边是两台 4 核的机器,一边跑一半 dm-worker 的样子。
这个参数应该怎么调整,我可以查看哪里的文档?
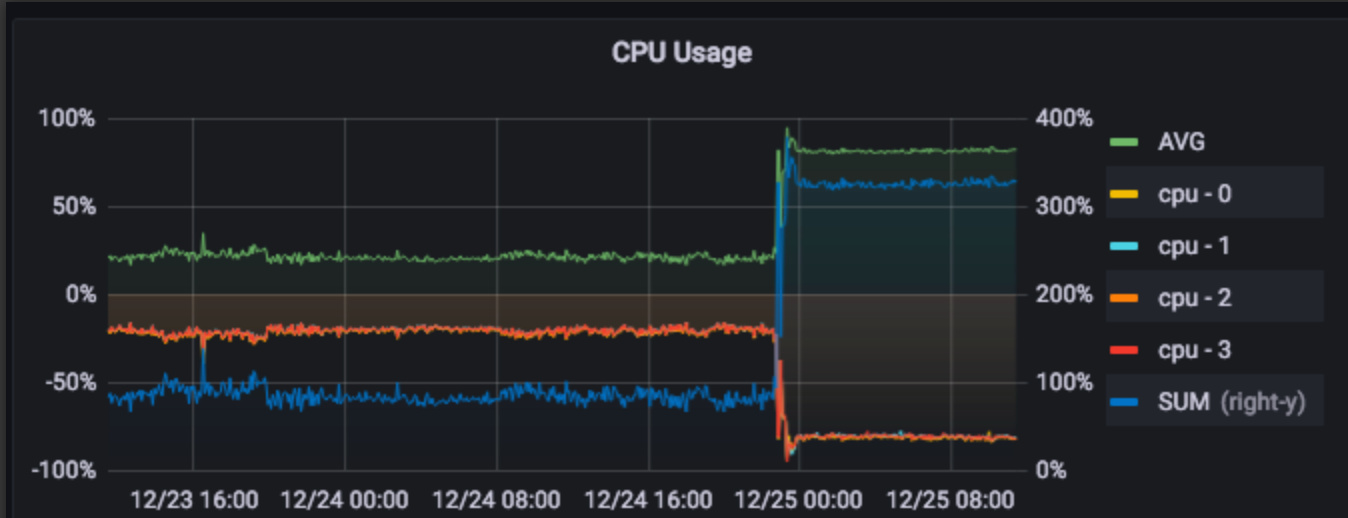
另,未升级前的 v2.0.1 我们已经跑了半年多的,完全的一样的环境和负载,没有任何问题(上面有升级前后监控图)。但是升级到 v2.0.7 就完全不一样,CPU 消耗很高。这个才是我觉得最奇怪的地方。
感谢!
2 个赞
MyronWang
(Myron Wang)
11
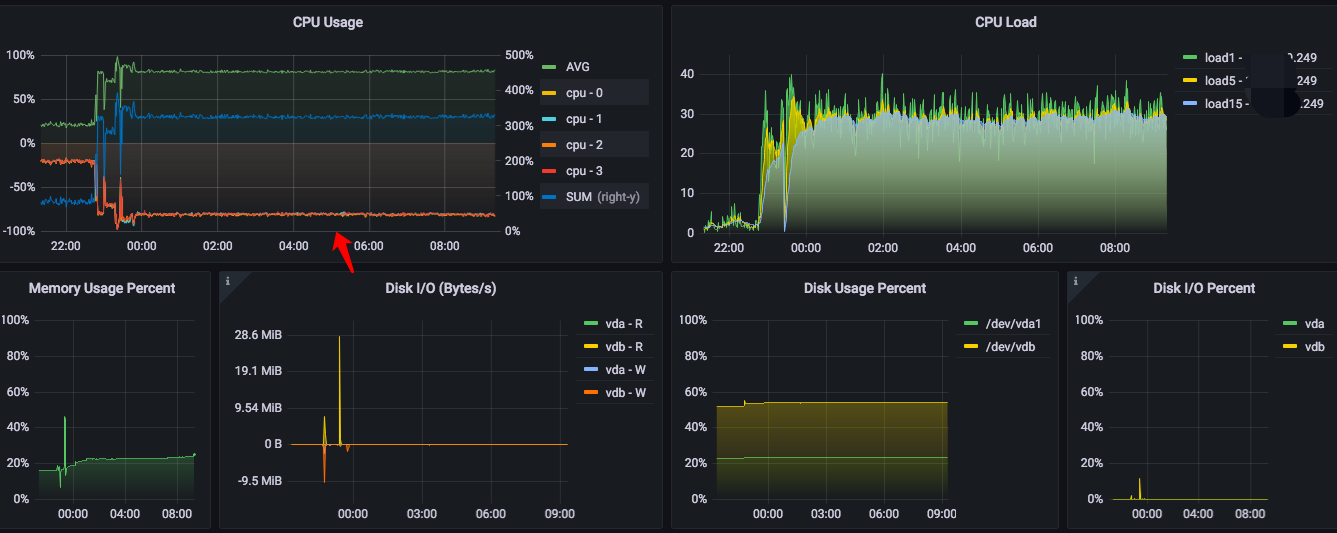
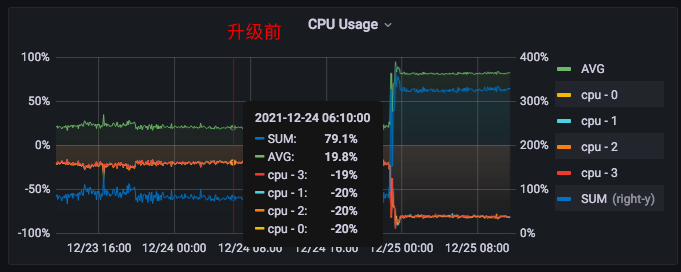
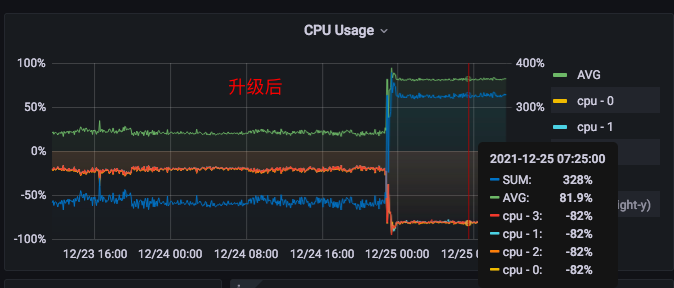
升级前后,CPU 消耗、机器负载 对比,非常明显,增长太大了。
2 个赞
MyronWang
(Myron Wang)
13
业务暂时没影响。
就是机器负载很高,CPU 占用高导致。内存、IO都跟升级前差不多,目前看来。
2 个赞
MyronWang
(Myron Wang)
15
1、TiUP 部署的;升级命令为 tiup dm upgrade proddm249 v2.0.7,一次性升级成功;升级前后配置文件没做任何变动(生产环境,没事也不会动配置,只是为了修复旧版本 rollback 那个 bug 问题,要不然不会升级)
2、负坐标是每核 CPU 的数据,正坐标是总和数据,图是我们这边自建的(这台机器是 4核)
3、集群部署在云主机上
2 个赞
MyronWang
(Myron Wang)
17
1、不是,这个节点只是加入了 k8s 集群而已,是为了统一管理,集群本质上是 DM 专用
2、可以看下前后对比,升级前每核占20%左右,升级后80%左右
3、监控指标都没变动过,我就是运维部的(没有运行在 pod 中)
4、昨天晚上 10:46 左右升的级,监控是同一套,监控我都截到23号了,这个图就是对比呀:joy:
2 个赞
yilong
(yi888long)
18
我的意思是,这个监控可以编辑吗?能够看出具体是哪些进程占用的高了?想对比下升级前后,每个 dm-worker 是否占用更高了,还是 sys 占用的更高了,想对比下具体的进程。
2 个赞