rw12306
(Rw12306)
1
为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【 TiDB 使用环境】
【概述】 场景 + 问题概述
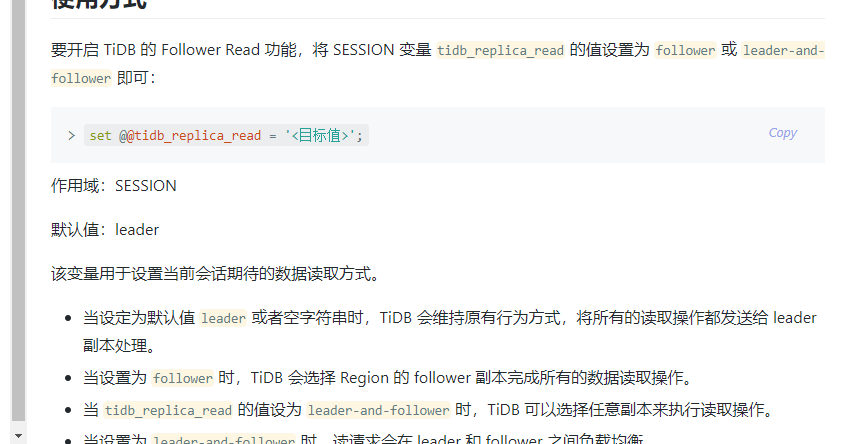
这个变量是一个SESSION变量,我用navicat 设置后,我这个会话是起作用了,但是其他人用navicat 看到的还是之前的那个值,如果我现在是java 程序用线程池调用,这个设置会起作用吗?
【背景】 做过哪些操作
【现象】 业务和数据库现象
【问题】 当前遇到的问题,参考 AskTUG 的 Troubleshooting 读性能慢-慢语句
【统计信息是否最新】
【执行计划内容】
【 SQL 文本、schema 以及 数据分布】
【业务影响】
【TiDB 版本】
【附件】 相关日志及监控(https://metricstool.pingcap.com/)
- TiUP Cluster Display 信息
- TiUP CLuster Edit config 信息
- TiDB-Overview Grafana监控
- TiDB Grafana 监控
- TiKV Grafana 监控
- PD Grafana 监控
- 对应模块日志(包含问题前后 1 小时日志)
Kongdom
(Kongdom)
2
我理解的是,在每一个数据库请求里都加上一句set会保险一点
这就是个变量作用域的问题, tidb_replica_read是个session级别的变量,只会在当前会话生效。Navicat新开窗口就是新的会话了,同理如果程序调用的话每次都要加上这个set。
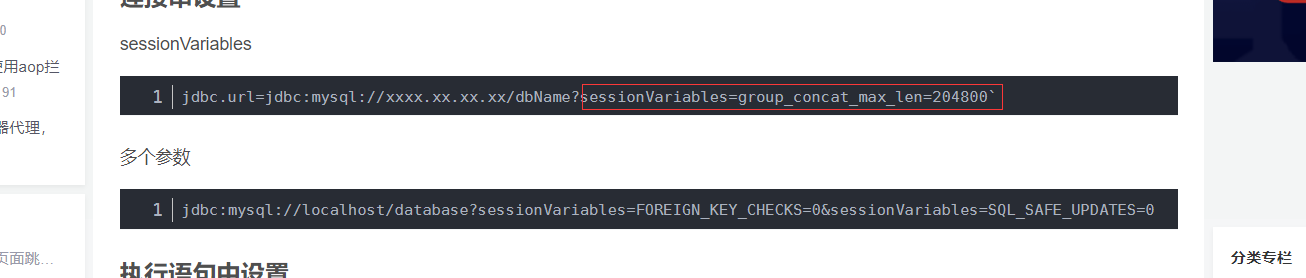
像这样放在jdbc后面也可以,但是控制粒度不够细,所有使用了这个jdbc的SQL都会用follower read
Kongdom
(Kongdom)
6
执行语句中设置吧,连接串加有点太强制了,可能不适用于某些场景
rw12306
(Rw12306)
7
执行语句中的话只是说明对某个sql 使用,我放到jdbc连接后面报错。
Kongdom
(Kongdom)
8
是的,此类变量建议放到执行语句中使用。注意变量的应用场景
注意:
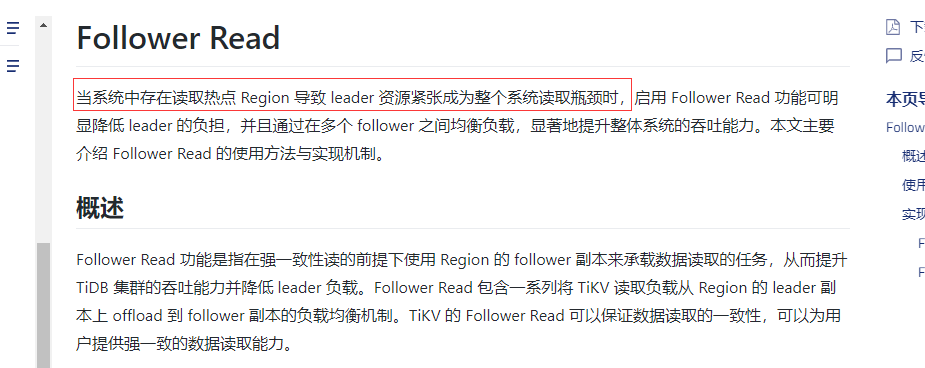
为了获得强一致读取的能力,在当前的实现中,follower 节点需要向 leader 节点询问当前的执行进度(即 ReadIndex ),这会产生一次额外的网络请求开销,因此目前 Follower Read 的主要优势是处理隔离集群的读写请求以及提升整体读取吞吐。
rw12306
(Rw12306)
9
就像这样

还有这个当系统中存在读取热点 Region 导致 leader 资源紧张成为整个系统读取瓶颈时,这个瓶颈怎么看呢?
Kongdom
(Kongdom)
10
应该是Grafana的PD视图中Statistics - hot read下的图表吧
system
(system)
关闭
11
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。