手动执行 不使用index_join 试试呢
Hint吗 如何改写?
没找到 忽略index_join的写法,忽略index_join之外还需要指定用其他的方法吗?
用 HASH_JOIN(t1) 试试
是其他的算法,不是忽略
1 个赞
hint hash_join 20秒以内出来了
EXPLAIN ANALYZE SELECT
/*+ HASH_JOIN(ags) */
count( 1 )
FROM
t1 ags
LEFT JOIN t2 ar ON ags.t2_id = ar.t2_id
WHERE
ags.STATUS IN ( 0, 1, 2, 4 )
AND ags.merchant_id = 'dwj'
AND ags.create_time >= date_format( '2021-10-22 00:00:00', '%Y-%m-%d' )
AND ags.create_time < date_format( '2021-12-22 00:00:00', '%Y-%m-%d' );
HashAgg_8 1.00 1 root time:18.1s, loops:2, partial_worker:{wall_time:18.067033898s, concurrency:5, task_num:277171, tot_wait:1m29.30845363s, tot_exec:967.379391ms, tot_time:1m30.334946956s, max:18.067007335s, p95:18.067007335s}, final_worker:{wall_time:18.0670587s, concurrency:5, task_num:5, tot_wait:1m30.335122281s, tot_exec:32.009μs, tot_time:1m30.335158795s, max:18.067037805s, p95:18.067037805s} funcs:count(1)->Column#46 5.55 KB N/A
└─HashJoin_21 8321563.15 8869395 root time:17.7s, loops:277172, build_hash_table:{total:11.9s, fetch:4.79s, build:7.15s}, probe:{concurrency:5, total:1m30.1s, max:18s, probe:27.7s, fetch:1m2.4s} left outer join, equal:[eq(dbdbdb.t1.t2_id, dbdbdb.t2.t2_id)] 808.8 MB 0 Bytes
├─IndexLookUp_28(Build) 8303070.48 8869395 root time:3.1s, loops:277170, index_task: {total_time: 10.8s, fetch_handle: 1.43s, build: 1.54ms, wait: 9.32s}, table_task: {total_time: 53.8s, num: 454, concurrency: 5} 151.7 MB N/A
│ ├─IndexRangeScan_25(Build) 8884171.27 9116010 cop[tikv] table:ags, index:idx_t1_3(create_time, phone) time:330.1ms, loops:8949, cop_task: {num: 10, max: 582.5ms, min: 318.4ms, avg: 451.4ms, p95: 582.5ms, max_proc_keys: 1073274, p95_proc_keys: 1073274, tot_proc: 4.13s, tot_wait: 3ms, rpc_num: 10, rpc_time: 4.51s, copr_cache_hit_ratio: 0.00}, tikv_task:{proc max:494ms, min:292ms, p80:442ms, p95:494ms, iters:8947, tasks:10}, scan_detail: {total_process_keys: 9116010, total_keys: 9116020, rocksdb: {delete_skipped_count: 0, key_skipped_count: 9116010, block: {cache_hit_count: 7976, read_count: 4, read_byte: 255.9 KB}}} range:[2021-10-22 00:00:00,2021-12-22 00:00:00), keep order:false N/A N/A
│ └─Selection_27(Probe) 8303070.48 8869395 cop[tikv] time:18.2s, loops:12020, cop_task: {num: 590, max: 113.9ms, min: 227.5μs, avg: 32.3ms, p95: 59.5ms, max_proc_keys: 20992, p95_proc_keys: 20480, tot_proc: 16.5s, tot_wait: 68ms, rpc_num: 590, rpc_time: 19.1s, copr_cache_hit_ratio: 0.03}, tikv_task:{proc max:73ms, min:0s, p80:37ms, p95:49ms, iters:11577, tasks:590}, scan_detail: {total_process_keys: 8886363, total_keys: 9325576, rocksdb: {delete_skipped_count: 290615, key_skipped_count: 18718093, block: {cache_hit_count: 1849333, read_count: 1, read_byte: 64.0 KB}}} eq(dbdbdb.t1.merchant_id, "dwj"), in(dbdbdb.t1.status, 0, 1, 2, 4) N/A N/A
│ └─TableRowIDScan_26 8884171.27 9116010 cop[tikv] table:ags tikv_task:{proc max:72ms, min:0s, p80:35ms, p95:46ms, iters:11577, tasks:590} keep order:false N/A N/A
└─IndexReader_32(Probe) 34675971.00 34677075 root time:695.3ms, loops:34080, cop_task: {num: 47, max: 814ms, min: 132.5ms, avg: 493.5ms, p95: 774.7ms, max_proc_keys: 1115215, p95_proc_keys: 1015004, tot_proc: 18.4s, tot_wait: 11ms, rpc_num: 47, rpc_time: 23.2s, copr_cache_hit_ratio: 0.00} index:IndexFullScan_31 456.8 MB N/A
└─IndexFullScan_31 34675971.00 34677075 cop[tikv] table:ar, index:PRIMARY(t2_id) tikv_task:{proc max:466ms, min:84ms, p80:394ms, p95:439ms, iters:34079, tasks:47}, scan_detail: {total_process_keys: 34677075, total_keys: 34677127, rocksdb: {delete_skipped_count: 56, key_skipped_count: 34688002, block: {cache_hit_count: 50088, read_count: 2, read_byte: 127.9 KB}}} keep order:false N/A N/A
2 个赞
IndexJoin_13 8848173 time:17h35m52.3s, loops:276507
IndexReader_12 3563472 time:66h25m17.9s, loops:553011
show variables like ‘tidb_index%’; 看看相关变量值多少
1 个赞
tikv 层面的 cop request 堆积跟 explain 结果中的 rpc_num (这里有两次回表, 一次build side ags 和 probe side ar) 数量是有一定关联的. 如果 rpc 请求太多反而不如 full scan 效果来的直接.
你的最新的结果 ar 端的 rpc_num 从 rpc_num: 97533 --> rpc_num: 47
1 个赞
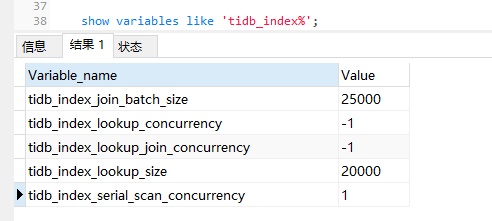
1 个赞
@dockerfile 目前看比较像是这里提到的这个原因,
方便的话,可以看一下
select
count(distinct activity_record_id)
from
activity_gift_status ags where ags.status IN (0, 1, 2, 4)
AND ags.merchant_id = 'dwj'
AND ags.create_time >= date_format('2021-10-22 00:00:00', '%Y-%m-%d')
AND ags.create_time < date_format('2021-12-22 00:00:00', '%Y-%m-%d');
1 个赞
3398249
1 个赞
请问这边集群里有其他的 tidb 吗,所有的 tidb 都会遇到这个问题吗
1 个赞
别瞎折腾了, 我发现把tidb_analyze_version 改回 1,各种灵异事件都好了。
1 个赞
有一点怀疑,辛苦看下tikv-details的thread cpu中的各个cpu改前和改后的值,怀疑是analyze是版本和gc的双重作用导致io占用极大,正常查询没法下推,也需要看看iowait的情况
1 个赞
是怎么想到这参数的
1 个赞
gc没啥问题,唯一gc不更新就是因为这种长时间的SQL把GC占住了,查看全局进程,把这种SQL kill,GC就正常。
磁盘IO没啥异常的,因为监控和日常的SQL我都能感受,大部分SQL还是很快的,出问题就是这种极端情况。
举个例子:
某SQL join了三张表,explain analyze 发现索引是对的,但是est rows 却扫描了10亿行,要知道这张表总共就10亿行,然后明确提示走了索引,但是indexfullscan est和act rows都是10亿,这能不慢?
同样我也是把analyze version改了 重新analyze 表 ,然后执行速度就起来了。
经过一夜观察,目前现状是有些恢复正常了,有些还是explain 出来的SQL走了索引但是却扫了全表,如上面举例所说。
2 个赞
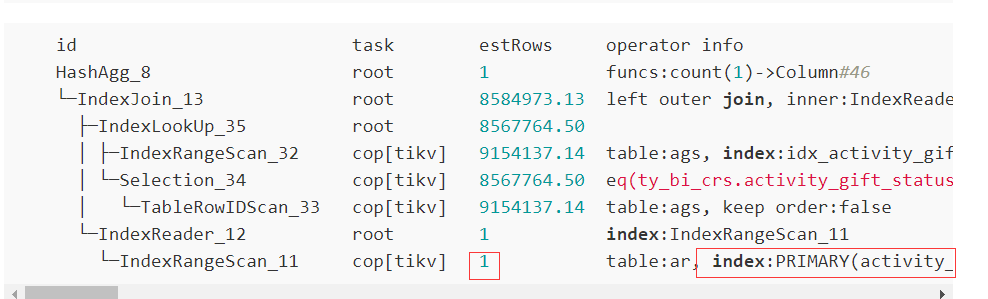
我讲的不是这个SQL。总是奇奇怪怪的,我还在探索中,有总结再进一步反馈。
这个SQL似乎无解?
1 个赞
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。