为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【 TiDB 使用环境】
centos7
【概述】 场景 + 问题概述
相同的sql执行完,排序方式不一样,该从哪里排查问题
【现象】 业务和数据库现象
tidb集群1执行结果

tidb集群2执行结果

【 TiDB 版本】
v5.1.0
为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【 TiDB 使用环境】
centos7
【概述】 场景 + 问题概述
相同的sql执行完,排序方式不一样,该从哪里排查问题
【现象】 业务和数据库现象
tidb集群1执行结果
tidb集群2执行结果
【 TiDB 版本】
v5.1.0
explain sql 看看解析计划的过程是否一致…
这个计划感觉不是很准,是不是有大量的新增或者更新?
可以考虑 analyze table, 做个统计更新,在试试 (生产环境,需要考虑执行的时间段,这个操作会影响效率)
一天会生成300条左右数据
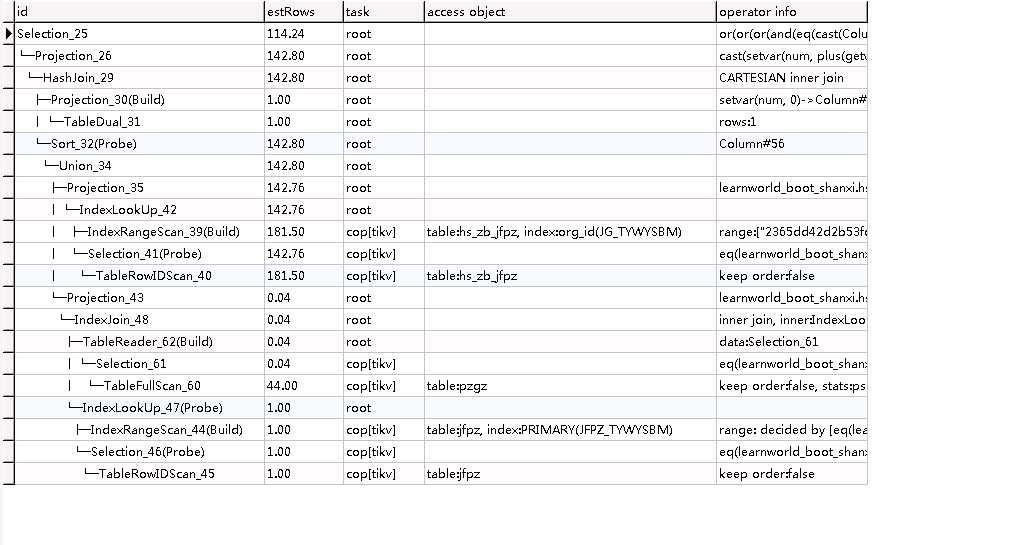
表pzgz 上面全表扫了1W行,下面全表只扫了44行,写法变了还是条件变了?
把表的统计信息刷新一下,如 @xfworld 所说analyze table,然后explain一下,对比一下结果,如果还有不一样的,发出来看看,另外,也可以执行show [global|session] bindings查看是否有绑定了执行计划。
SHOW [GLOBAL|SESSION] BINDINGS
sql语句一模一样,没有变
请问语句中是否使用了group by,如果使用了group by的话在group by后面跟个order by (字段与group by的字段一致),再试下
多谢大家,执行完analyze table后,再查询好了
什么情况下会出现这种问题,需要刷新下表信息?
两次执行间隔如何?如果间隔很长是不是需要考虑auto_analyze的影响?貌似5开始支持增量analyze了,不知道是否对这个有影响
学习了,不过,为什么更新统计信息会改变默认排序,,或者说,在tidb中,没有排序子句时,不保证任何排序
看上面的执行计划,由于统计信息的影响,两个计划在最上层的 hash join 的 build 和 probe 端是不一样的(因为统计信息影响基数估算,进而影响 join 的 inner 和 outer 选择),而sort 算子一次是出现在probe 端,一次没有,那么hash join的结果按 probe 出来的顺序是不同的。如果需要最终的结果是保序的,一般需要再加一个 order by,不过这个也会引入额外的执行开销,需要根据业务需要来判断。
1)统计信息不准确,导致选择的不同的join方式;
2)只要SQL语句里没有指定"order By",优化器选取哪一种join并不需要考虑结果集是否是按顺序返回的,它更多考虑算法代价更小的join;
3)SQL语句没有指定"order by",只有merge join会返回有序的结果集,因为merge join的输入表的连接字段是需要有序的;
请问下,统计信息不准有哪些原因导致? 对同一个表select 的不同也会导致统计不同吧? 不应该要每个表都analyze一次吧?谢谢!
1)统计信息不准确,严格意义上说是表或者索引的数据分布变动导致统计信息不准确,对表的select 不会导致统计信息不同
2)当表中的modify(dml)的数据量变动的比率超过0.5,会触发系统自动再次收集,如果想让统计信息不失真,可以调整这个值
3)默认会24H(全天候)触发后自动收集,实践中可以设置analyze的时间窗口和并发度,以此减少对线上业务影响和加快收集统计信息。
谢谢!
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。