【 TiDB 使用环境】
【概述】
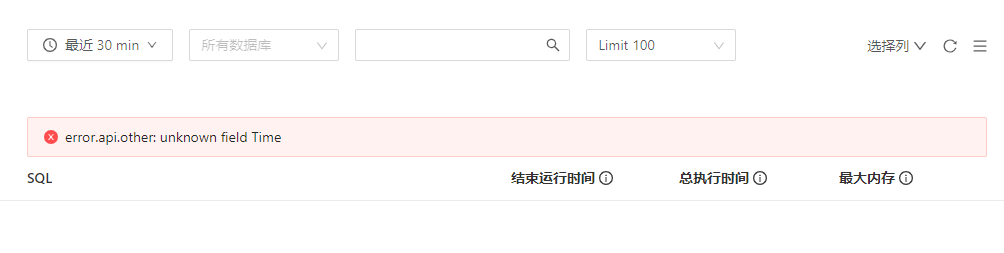
v4.0.0采用离线方式升级到v4.0.9,升级后Dashboard中慢查询报错,提示error.api.other: unknown field Time。
(使用浏览器的无痕模式可以正常打开,使用原来连接过Dashboard的电脑打开会报错)
PS:刚试了一下清空浏览器缓存,可以正常使用不报错,但这是什么原因呢?不能每次都清空缓存,毕竟清理之后日常使用的好多网站都需要重新登录
【背景】v4.0.0采用离线方式升级到v4.0.9
【现象】Dashboard中慢查询报错
【业务影响】无法监控慢语句
【TiDB 版本】v4.0.9
【附件】
dashboard 所在的 PD 的节点的日志有报错嘛?
以下是升级后的相关pd节点的错误日志,一共两个节点的日志
【PD1】
[2021/12/19 23:05:15.769 +08:00] [ERROR] [server.go:242] [“region syncer send data meet error”] [error=“rpc error: code = Unavailable desc = transport is closing”]
[2021/12/19 23:05:16.609 +08:00] [ERROR] [etcdutil.go:108] [“load from etcd meet error”] [error=“context deadline exceeded”]
[2021/12/19 23:05:18.610 +08:00] [ERROR] [etcdutil.go:108] [“load from etcd meet error”] [error=“context deadline exceeded”]
[2021/12/19 23:05:19.431 +08:00] [ERROR] [server.go:1117] [“failed to update timestamp”] [error=“save timestamp failed, maybe we lost leader”]
[2021/12/19 23:06:33.805 +08:00] [ERROR] [heartbeat_streams.go:121] [“send keepalive message fail”] [target-store-id=1] [error=EOF]
[2021/12/19 23:06:33.805 +08:00] [ERROR] [heartbeat_streams.go:121] [“send keepalive message fail”] [target-store-id=4] [error=EOF]
[2021/12/19 23:08:34.571 +08:00] [ERROR] [tidb_requests.go:65] [“fail to send schema request to TiDB”] [error=“error.tidb.client_request_failed: Failed to send TiDB API request, cause: Get http://127.0.0.1:43530/schema: EOF”]
【PD2】
[2021/12/19 22:00:35.257 +08:00] [ERROR] [grpclog.go:75] [“transport: Got too many pings from the client, closing the connection.”]
[2021/12/19 22:00:35.258 +08:00] [ERROR] [grpclog.go:75] [“transport: loopyWriter.run returning. Err: transport: Connection closing”]
[2021/12/19 23:05:07.113 +08:00] [ERROR] [middleware.go:148] [“request failed”] [error=“Get http://200.100.1.15:2379/pd/api/v1/members: context canceled”]
[2021/12/19 23:05:09.934 +08:00] [ERROR] [client.go:171] [“region sync with leader meet error”] [error=“rpc error: code = Canceled desc = context canceled”]
[2021/12/19 23:05:17.745 +08:00] [ERROR] [etcdutil.go:108] [“load from etcd meet error”] [error=“context deadline exceeded”]
[2021/12/19 23:06:43.131 +08:00] [ERROR] [client.go:171] [“region sync with leader meet error”] [error=“rpc error: code = Canceled desc = context canceled”]
[2021/12/19 23:06:54.133 +08:00] [ERROR] [server.go:1058] [“campaign leader meet error”] [error=“context deadline exceeded”]
[2021/12/19 23:17:33.833 +08:00] [ERROR] [heartbeat_streams.go:98] [“send heartbeat message fail”] [region-id=292534] [error="[PD:grpc:ErrGRPCSend]send request error"]
[2021/12/19 23:27:34.016 +08:00] [ERROR] [heartbeat_streams.go:98] [“send heartbeat message fail”] [region-id=441847] [error="[PD:grpc:ErrGRPCSend]send request error"]
这个主要是升级之后,清空浏览器缓存,重新登录就不报错了。发帖主要是想弄清楚原因,不可能每次升级都清空浏览器缓存。
PD 感觉不太稳阿,可以考虑同步跟踪下日志:
访问的之前,把 pd 的 log (tail -f ) ,然后访问dashboard 看看同步有没有什么错误出现
这样方便判断一些
![]() 现在已经清缓存正常了~ 只有升级前登陆过的浏览器,升级后再打开才会有这个报错。如果是没有登录过的浏览器或者清理缓存的浏览器登录,就正常,打开也不报错。
现在已经清缓存正常了~ 只有升级前登陆过的浏览器,升级后再打开才会有这个报错。如果是没有登录过的浏览器或者清理缓存的浏览器登录,就正常,打开也不报错。
好的。我们这边测试重现一下。
估计常量做没过期处理,或者覆盖处理,恭喜你,又找到bug了 ![]() YYDS
YYDS
1 个赞
![]()
![]()
![]()
确认了一下,这个是已知的问题。v4.0.14 以及 v5.0.3 以后的版本已经修复。
fix 的 PR: https://github.com/pingcap/tidb-dashboard/pull/930
感谢感谢~
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。