独立spark 2.3 集群集成tispark-assembly-2.3.16.jar
$SPARK_HOME/conf/spark-defaults.conf
配置
spark.tispark.pd.addresses pd…
spark.sql.extensions org.apache.spark.sql.TiExtensions
spark.tispark.write.allow_spark_sql true
启动 spark-sql
use database; show tables 显示tidb表
单个查询语句 select * from tidbdb_a.table_a 正常
执行 insert into tidbdb_b.table_b select * from tidbdb_a.table_a
报错:
2021-12-17 15:08:22 INFO HiveMetaStore:746 - 0: get_database: tidbdb_b
2021-12-17 15:08:22 INFO audit:371 - ugi=root ip=unknown-ip-addr cmd=get_database: tidbdb_b
2021-12-17 15:08:22 WARN ObjectStore:568 - Failed to get database tidbdb_b, returning NoSuchObjectException
2021-12-17 15:08:22 INFO HiveMetaStore:746 - 0: get_database: tidbdb_b
2021-12-17 15:08:22 INFO audit:371 - ugi=root ip=unknown-ip-addr cmd=get_database: tidbdb_b
2021-12-17 15:08:22 WARN ObjectStore:568 - Failed to get database tidbdb_b, returning NoSuchObjectException
2021-12-17 15:08:22 INFO HiveMetaStore:746 - 0: get_database: tidbdb_a
2021-12-17 15:08:22 INFO audit:371 - ugi=root ip=unknown-ip-addr cmd=get_database: tidbdb_a
2021-12-17 15:08:22 WARN ObjectStore:568 - Failed to get database tidbdb_a, returning NoSuchObjectException
2021-12-17 15:08:23 WARN Utils:66 - Truncated the string representation of a plan since it was too large. This behavior can be adjusted by setting ‘spark.debug.maxToStringFields’ in SparkEnv.conf.
2021-12-17 15:08:23 INFO CodeGenerator:54 - Code generated in 145.515634 ms
2021-12-17 15:08:23 ERROR SparkSQLDriver:91 - Failed in [INSERT INTO tidbdb_a.talbe_a select * FROM tidbdb_b.table_b
]
java.util.NoSuchElementException: None.get
at scala.None$.get(Option.scala:347)
at scala.None$.get(Option.scala:345)
at com.pingcap.tispark.TiDBRelation.insert(TiDBRelation.scala:143)
at org.apache.spark.sql.execution.datasources.InsertIntoDataSourceCommand.run(InsertIntoDataSourceCommand.scala:43)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult$lzycompute(commands.scala:70)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult(commands.scala:68)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.executeCollect(commands.scala:79)
at org.apache.spark.sql.Dataset$$anonfun$6.apply(Dataset.scala:190)
at org.apache.spark.sql.Dataset$$anonfun$6.apply(Dataset.scala:190)
at org.apache.spark.sql.Dataset$$anonfun$52.apply(Dataset.scala:3253)
at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:77)
at org.apache.spark.sql.Dataset.withAction(Dataset.scala:3252)
at org.apache.spark.sql.Dataset.(Dataset.scala:190)
at org.apache.spark.sql.Dataset$.ofRows(Dataset.scala:75)
at org.apache.spark.sql.SparkSession.sql(SparkSession.scala:638)
at org.apache.spark.sql.SQLContext.sql(SQLContext.scala:694)
at org.apache.spark.sql.hive.thriftserver.SparkSQLDriver.run(SparkSQLDriver.scala:62)
at org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver.processCmd(SparkSQLCLIDriver.scala:355)
at org.apache.hadoop.hive.cli.CliDriver.processLine(CliDriver.java:376)
at org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver$.main(SparkSQLCLIDriver.scala:263)
at org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver.main(SparkSQLCLIDriver.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.spark.deploy.JavaMainApplication.start(SparkApplication.scala:52)
at org.apache.spark.deploy.SparkSubmit$.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:879)
at org.apache.spark.deploy.SparkSubmit$.doRunMain$1(SparkSubmit.scala:197)
at org.apache.spark.deploy.SparkSubmit$.submit(SparkSubmit.scala:227)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:136)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
java.util.NoSuchElementException: None.get
at scala.None$.get(Option.scala:347)
at scala.None$.get(Option.scala:345)
at com.pingcap.tispark.TiDBRelation.insert(TiDBRelation.scala:143)
at org.apache.spark.sql.execution.datasources.InsertIntoDataSourceCommand.run(InsertIntoDataSourceCommand.scala:43)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult$lzycompute(commands.scala:70)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult(commands.scala:68)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.executeCollect(commands.scala:79)
at org.apache.spark.sql.Dataset$$anonfun$6.apply(Dataset.scala:190)
at org.apache.spark.sql.Dataset$$anonfun$6.apply(Dataset.scala:190)
at org.apache.spark.sql.Dataset$$anonfun$52.apply(Dataset.scala:3253)
at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:77)
at org.apache.spark.sql.Dataset.withAction(Dataset.scala:3252)
at org.apache.spark.sql.Dataset.(Dataset.scala:190)
at org.apache.spark.sql.Dataset$.ofRows(Dataset.scala:75)
at org.apache.spark.sql.SparkSession.sql(SparkSession.scala:638)
at org.apache.spark.sql.SQLContext.sql(SQLContext.scala:694)
at org.apache.spark.sql.hive.thriftserver.SparkSQLDriver.run(SparkSQLDriver.scala:62)
at org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver.processCmd(SparkSQLCLIDriver.scala:355)
at org.apache.hadoop.hive.cli.CliDriver.processLine(CliDriver.java:376)
at org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver$.main(SparkSQLCLIDriver.scala:263)
at org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver.main(SparkSQLCLIDriver.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.spark.deploy.JavaMainApplication.start(SparkApplication.scala:52)
at org.apache.spark.deploy.SparkSubmit$.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:879)
at org.apache.spark.deploy.SparkSubmit$.doRunMain$1(SparkSubmit.scala:197)
at org.apache.spark.deploy.SparkSubmit$.submit(SparkSubmit.scala:227)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:136)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
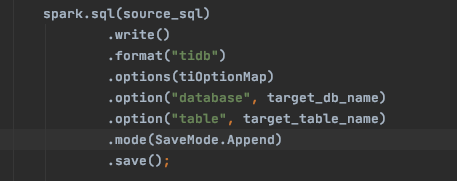
https://github.com/pingcap/tispark/blob/master/docs/datasource_api_userguide.md
文档里有 SparkSQL insert into 执行方式