为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【 TiDB 使用环境】
【概述】
我在三台物理机上部署了90个虚拟机节点,每个物理机30个虚拟机,其中有15个挂载100GB的ssd
在第四台物理机上启动pd和go-ycsb进行tikv节点的测试。
但是当go-ycsb的插入数据设置为1TB时,中途会有很多虚拟机节点挂掉。
pd和tikv是2.0版本
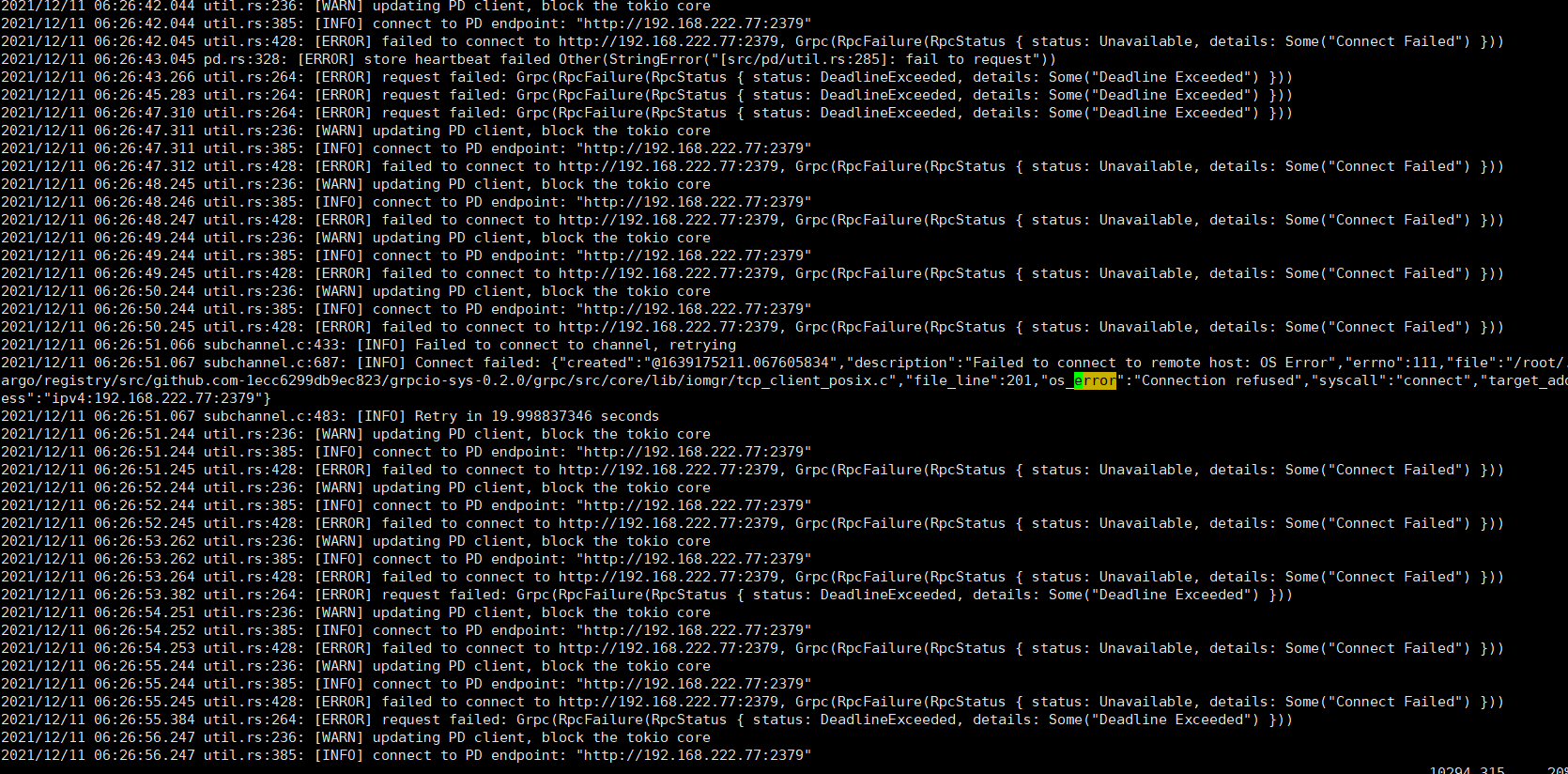
pd日志如下
挂掉的tikv日志如下 IP为192.168.222.206
挂掉的tikv日志如下 IP为192.168.222.219
挂掉的tikv日志如下 IP为192.168.222.198 挂载了ssd
我又进行了一次测试 这次我重启了挂掉的虚拟机,并查看了tikv日志 如下
我认为是否有可能是网络问题????
1 个赞
另外机器的 SSD 是 SATA 的还是 NVMe 的,主机的指标是什么样的虚拟机里的资源情况又是什么样的。可以看看是不是哪里已经成为瓶颈了。
另外为什么不用最新版本呢?2.0 已经是好些年前的版本了,也没睡会再翻出当年的代码来排查了。
ssd是NVMe的 因为代码是很多年前开发的所以 一直使用2.0版本
虚拟机都是4G的内存 100G的ssd或者HDD
宿主机的话 我在运行过程中使用iostat -x 1命令查看 hdd盘的利用率会普遍维持再百分之百左右 是否是您说的宿主机严重过载了呢? 也就是说我的宿主机的io能力跟不上?
如果是机械盘的话 100% 利用率已经挂掉了,磁盘响应时间已经没法看了。
请问下这个问题要怎么解决呢 我现在一启动go-ycsb测试tikv,物理机的hdd利用率就会达到百分百,然后很多tikv节点会挂掉,这个要怎么解决呢?
机械盘跑 TiKV 不在官方支持范围内,自己这么跑的话也需要了解到机械盘不可能支撑大流量,跑 benchmark 这种事情一定会把机器压死。
system
(system)
关闭
11
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。