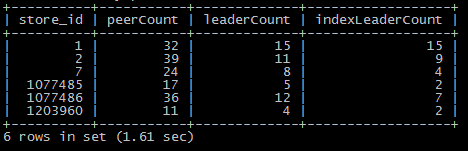
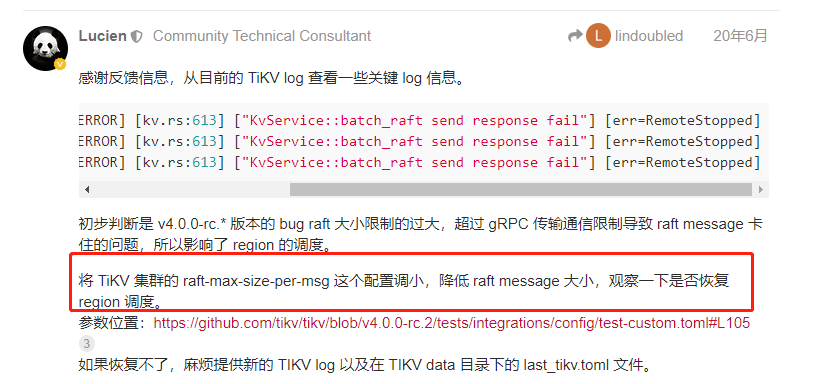
为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【 TiDB 使用环境】
生产环境
【概述】场景+问题概述
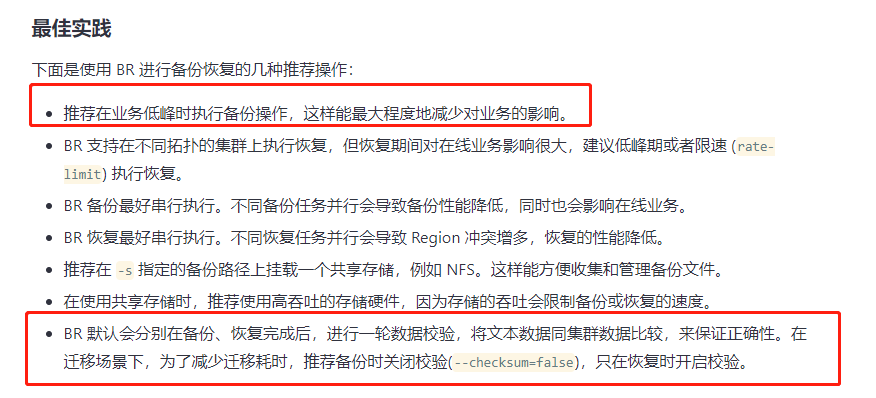
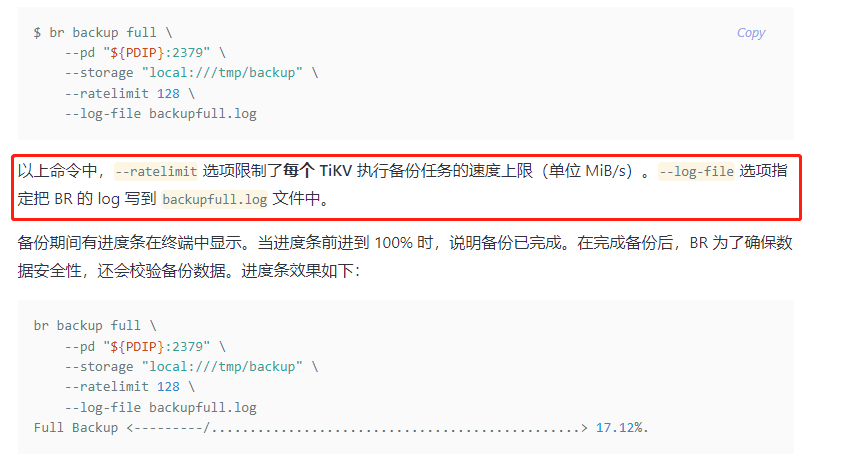
- 22:30开始使用br对整个集群进行备份,0点时强制中止
- 业务一直有写入操作,大数据也会不定期的写入大量数据(百万级别)
- 2021-12-02 23:00:00收到第一条操作tidb慢的报警
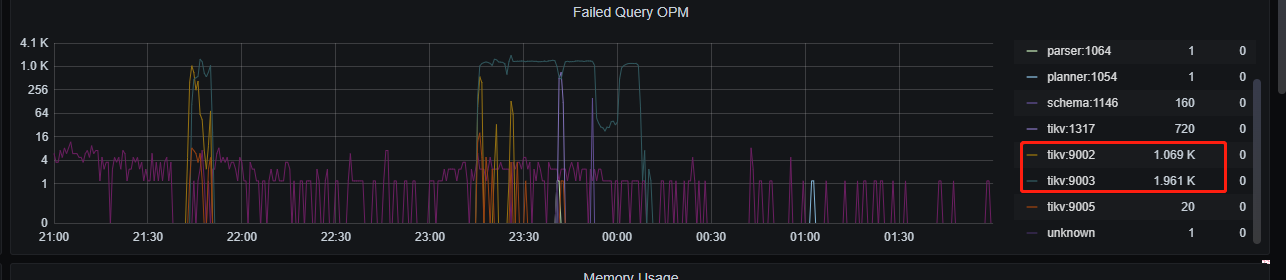
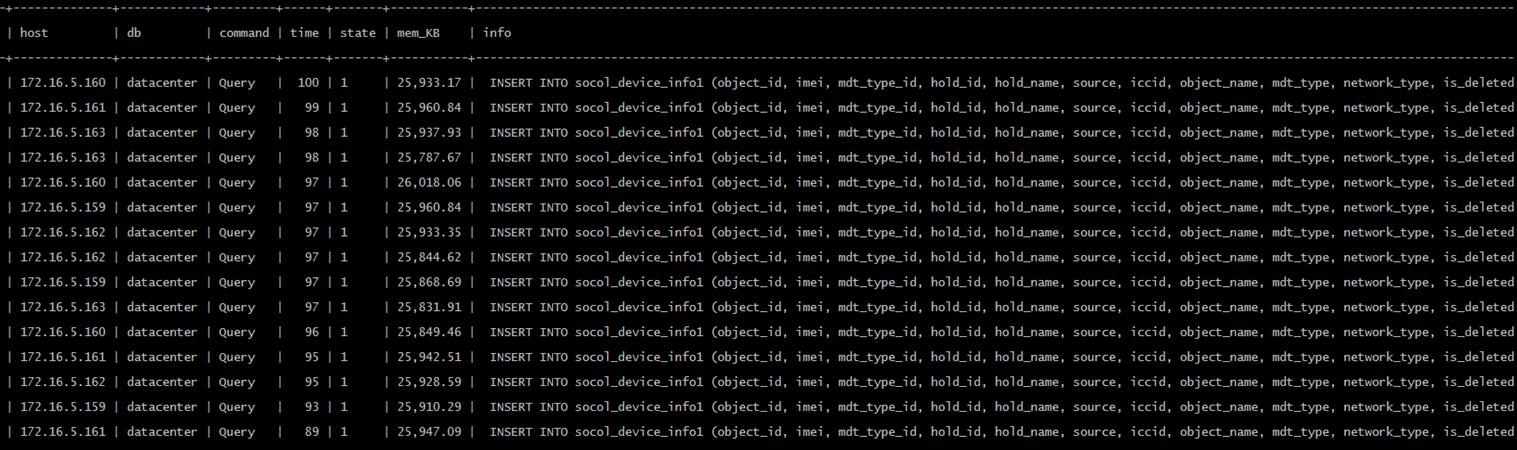
接到报警后进入tidb执行show processlist发现一个tidb-server有约500个线程在insert一个2900万的表,业务使用两个tidb-server,总共约1000个连接在执行insert一个表,但执行很慢,当时看到有四五十秒还在执行的,如下图(23:18时的截图):

另外,大数据也在写另一个tidb-server(写入300万+),下图为23:21时的状态
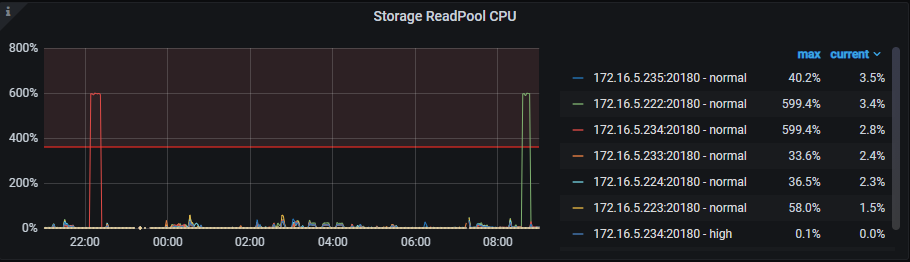
当时TiDB基本处理无响应的状态,查看监控发现TiKV的cpu很慢,其中一个tikv节点的Storage ReadPool CPU,如下图:

【背景】做过哪些操作
接到报警后:
1、停止大数据的写入
2、对业务写入的表重命名到另外一个库作为备份,业务库新建一张空表供业务写入
3、停掉mysql->TiDB的dm同步
4、停掉cdc服务
上述处理过后,tidb依然很卡!
【现象】业务和数据库现象
【业务影响】
业务无法提供服务
【TiDB 版本】
v4.0.10
【附件】
- 相关日志 和 监控
-
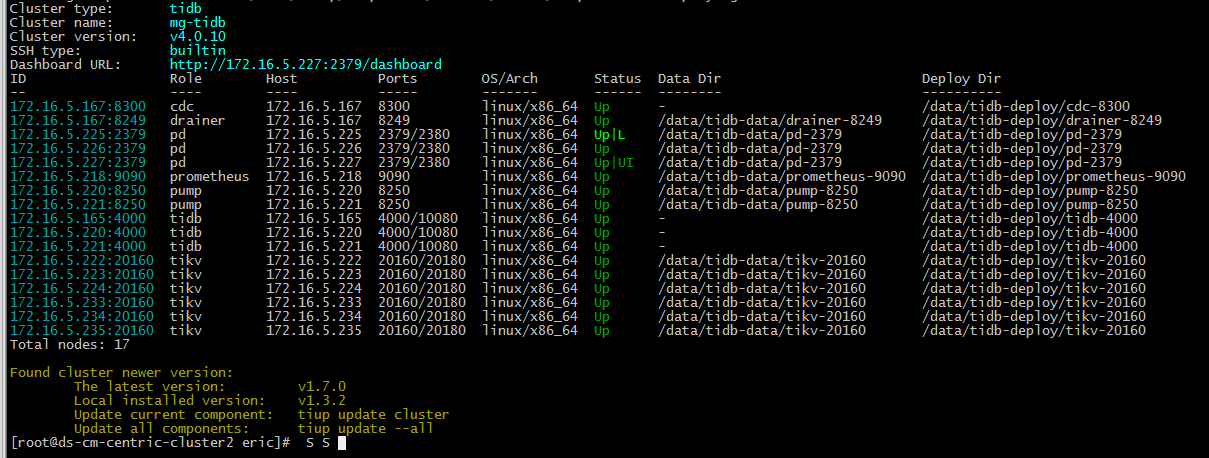
TiUP Cluster Display 信息
-
TiUP Cluster Edit Config 信息
TiUP Cluster Edit Config 信息.txt (3.9 KB) -
TiDB- Overview 监控
mg-tidb-Overview_2021-12-03T10_11_48.425Z.rar (286.4 KB)
mg-tidb-TiKV-Details_2021-12-03T10_11_25.950Z.rar (3.1 MB)
- 对应模块日志(包含问题前后1小时日志)
cpu高的tikv节点日志如下:
[root@tidb-tikv-1 log]# tail tikv.log.2021-12-03-00:00:16.126888600
[2021/12/01 19:04:59.982 +08:00] [ERROR] [store.rs:487] ["handle raft message failed"] [err_code=KV:Raftstore:Unknown] [err="Other(\"[components/raftstore/src/store/fsm/store.rs:1360]: [region 17616486] region not exist but not tombstone: region { id: 17616486 start_key: 7480000000000061FF195F728000000000FF1952C90000000000FA end_key: 7480000000000061FF195F728000000000FF23A29B0000000000FA region_epoch { conf_ver: 4112 version: 26806 } peers { id: 17616487 store_id: 2 } peers { id: 17616488 store_id: 1077486 } peers { id: 17616489 store_id: 1203960 } }\")"] [store_id=2]
[2021/12/01 22:31:59.369 +08:00] [ERROR] [endpoint.rs:160] ["backup snapshot failed"] [err_code=KV:Raftstore:NotLeader] [err="Request(message: \"peer is not leader for region 459321, leader may Some(id: 459323 store_id: 1)\" not_leader { region_id: 459321 leader { id: 459323 store_id: 1 } })"]
[2021/12/01 22:31:59.372 +08:00] [ERROR] [endpoint.rs:680] ["backup region failed"] [err_code=KV:Unknown] [err="Engine(Request(message: \"peer is not leader for region 459321, leader may Some(id: 459323 store_id: 1)\" not_leader { region_id: 459321 leader { id: 459323 store_id: 1 } }))"] [end_key=7480000000000006CB5F698000000000000001037FFFFFFFFFFFFFFF0380000000054BBDC5] [start_key=7480000000000006CB5F698000000000000001037FFFFFFFFFFFFFFF0380000000053BCE16] [region="id: 459321 start_key: 7480000000000006FFCB5F698000000000FF000001037FFFFFFFFFFFFFFFFF03800000FF00053BCE16000000FC end_key: 7480000000000006FFCB5F698000000000FF000001037FFFFFFFFFFFFFFFFF03800000FF00054BBDC5000000FC region_epoch { conf_ver: 11 version: 5806 } peers { id: 459322 store_id: 2 } peers { id: 459323 store_id: 1 } peers { id: 1232387 store_id: 1203960 }"]
[2021/12/02 06:58:23.872 +08:00] [ERROR] [router.rs:170] ["failed to send significant msg"] [msg=LeaderCallback(Callback::Read(..))]
[2021/12/02 10:05:11.735 +08:00] [ERROR] [router.rs:170] ["failed to send significant msg"] [msg=LeaderCallback(Callback::Read(..))]
[2021/12/02 11:30:07.143 +08:00] [ERROR] [<unknown>] ["ipv4:172.16.5.167:38988: Keepalive watchdog fired. Closing transport."]
[2021/12/02 17:01:05.945 +08:00] [ERROR] [router.rs:170] ["failed to send significant msg"] [msg=LeaderCallback(Callback::Read(..))]
[2021/12/02 17:04:58.249 +08:00] [ERROR] [router.rs:170] ["failed to send significant msg"] [msg="CaptureChange { cmd: RegisterObserver { observe_id: ObserveID(9679), region_id: 17706758, enabled: true }, region_epoch: conf_ver: 1454 version: 22974, callback: Callback::Read(..) }"]
[2021/12/02 17:04:58.254 +08:00] [ERROR] [router.rs:170] ["failed to send significant msg"] [msg="CaptureChange { cmd: RegisterObserver { observe_id: ObserveID(9680), region_id: 17706758, enabled: true }, region_epoch: conf_ver: 1454 version: 22974, callback: Callback::Read(..) }"]
[2021/12/03 00:00:16.119 +08:00] [ERROR] [service.rs:86] ["backup canceled"] [error=RemoteStopped]
[root@tidb-tikv-1 log]#
[root@tidb-tikv-1 log]# head tikv.log
[2021/12/03 00:00:16.128 +08:00] [ERROR] [service.rs:86] ["backup canceled"] [error=RemoteStopped]
[2021/12/03 00:00:19.728 +08:00] [ERROR] [endpoint.rs:707] ["backup failed to send response"] [err_code=KV:Unknown] [err="TrySendError { kind: Disconnected }"]
[2021/12/03 00:00:21.529 +08:00] [ERROR] [endpoint.rs:707] ["backup failed to send response"] [err_code=KV:Unknown] [err="TrySendError { kind: Disconnected }"]
[2021/12/03 02:24:20.603 +08:00] [ERROR] [<unknown>] ["ipv4:172.16.5.167:17368: Keepalive watchdog fired. Closing transport."]
[2021/12/03 02:24:32.121 +08:00] [ERROR] [<unknown>] ["ipv4:172.16.5.167:20600: Keepalive watchdog fired. Closing transport."]
[2021/12/03 02:28:58.629 +08:00] [ERROR] [router.rs:170] ["failed to send significant msg"] [msg=LeaderCallback(Callback::Read(..))]
[2021/12/03 07:11:48.250 +08:00] [ERROR] [router.rs:170] ["failed to send significant msg"] [msg=LeaderCallback(Callback::Read(..))]
[2021/12/03 07:34:13.914 +08:00] [ERROR] [router.rs:170] ["failed to send significant msg"] [msg="CaptureChange { cmd: RegisterObserver { observe_id: ObserveID(12107), region_id: 9472123, enabled: true }, region_epoch: conf_ver: 1769 version: 23196, callback: Callback::Read(..) }"]
[2021/12/03 07:34:14.260 +08:00] [ERROR] [router.rs:170] ["failed to send significant msg"] [msg=LeaderCallback(Callback::Read(..))]
[2021/12/03 07:49:42.669 +08:00] [ERROR] [router.rs:170] ["failed to send significant msg"] [msg=LeaderCallback(Callback::Read(..))]