为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【 TiDB 使用环境】
4.0.11
【概述】 场景 + 问题概述
目前有几个小表 几十万条数据,但是热点很高 想尝试做region切分,看了下官方文档 有些疑问
【背景】 做过哪些操作
11月16号 上线新业务高并发全表扫描读小表的语句
【现象】 业务和数据库现象
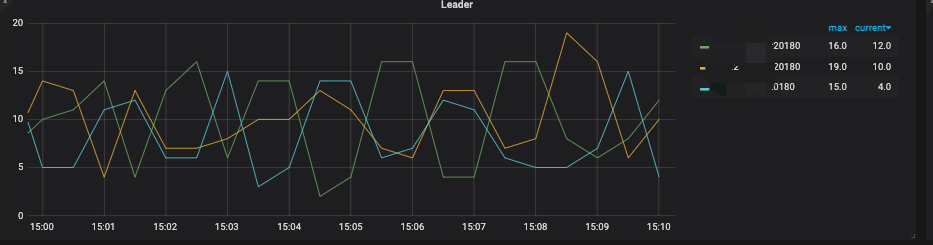
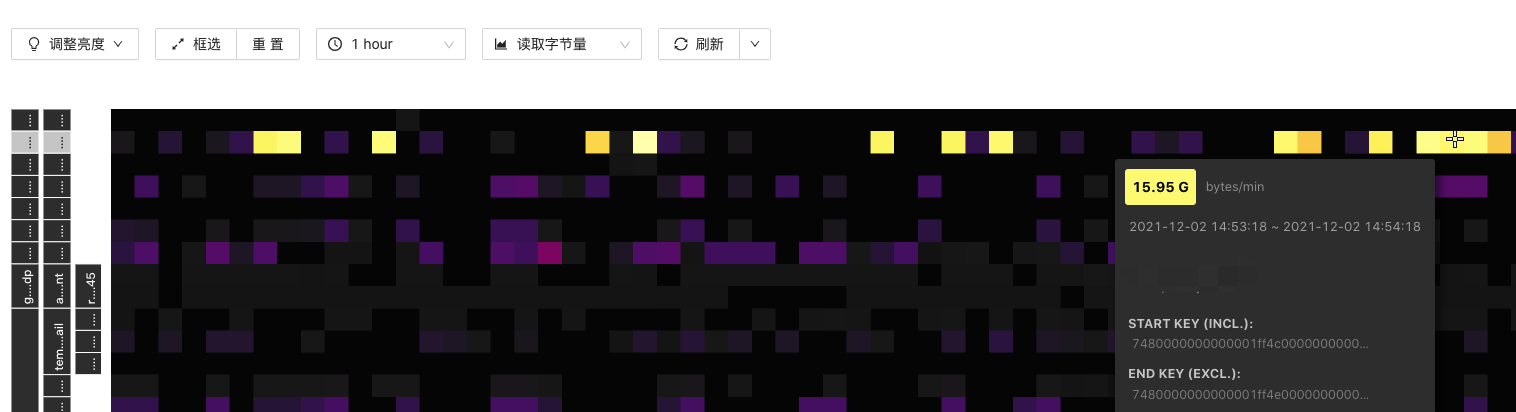
小表有读热点
【问题】 当前遇到的问题
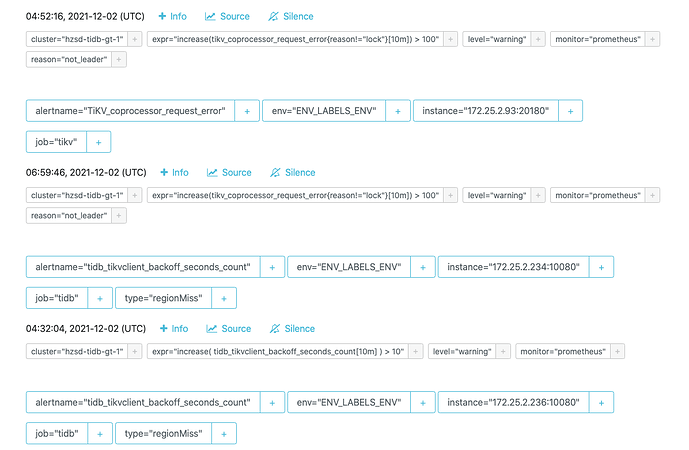
问题1:想排查频繁出现TiDB tikvclient_backoff_count error 以及TiKV coprocessor request error告警的原因
初步定位怀疑是 高并发读小表导致region leader一直在切换 出现not leader 请大佬们帮忙看下是不是这个原因 能调整什么参数优化吗

问题2:
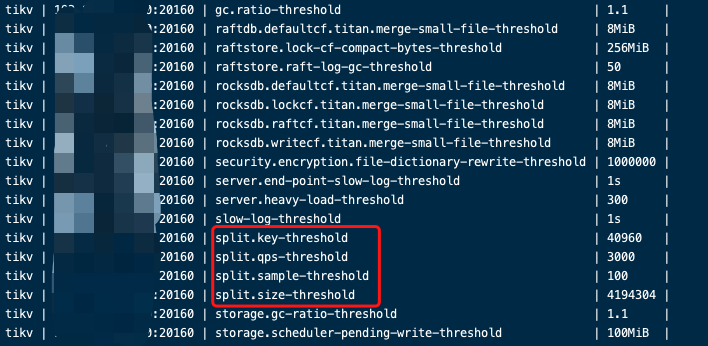
尝试合并region没解决问题,想试试region切分 分散小表r热点
查看官方文档

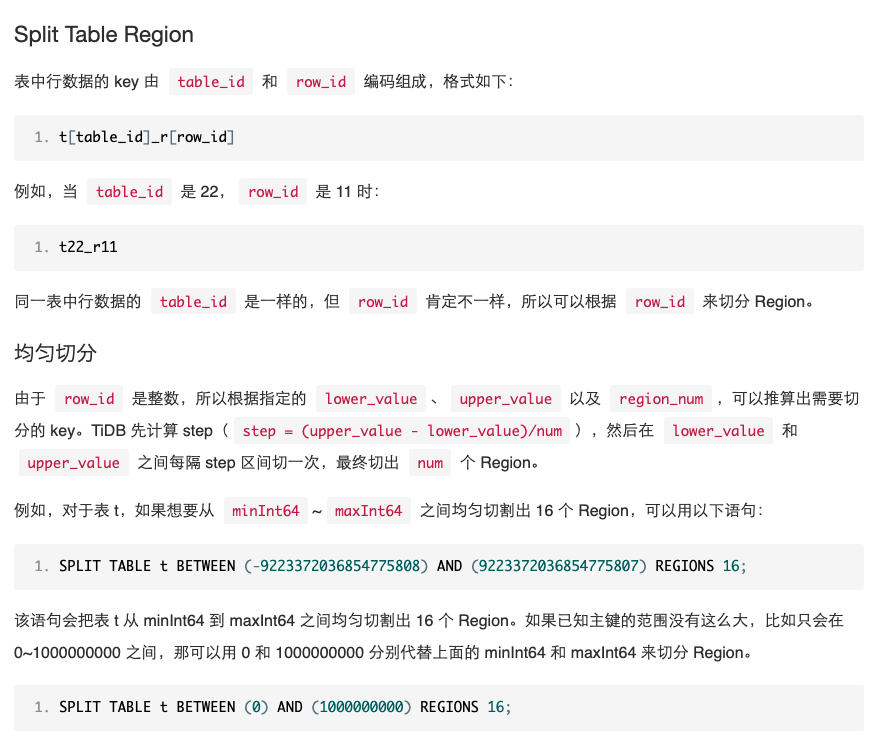
这个BETWEEN (lower_value) AND (upper_value). 这两个区间值应该如何确认呢看了下文档不懂这个是怎么计算的
我的表 region信息是这样的
mysql> show table temporary_freeze regions;
±----------±----------±--------±----------±----------------±-----------------±-----------±--------------±-----------±---------------------±-----------------+
| REGION_ID | START_KEY | END_KEY | LEADER_ID | LEADER_STORE_ID | PEERS | SCATTERING | WRITTEN_BYTES | READ_BYTES | APPROXIMATE_SIZE(MB) | APPROXIMATE_KEYS |
±----------±----------±--------±----------±----------------±-----------------±-----------±--------------±-----------±---------------------±-----------------+
| 3408 | t_332_ | t_334_ | 3409 | 1 | 3409, 3410, 3411 | 0 | 0 | 0 | 4 | 36172 |
±----------±----------±--------±----------±----------------±-----------------±-----------±--------------±-----------±---------------------±-----------------+
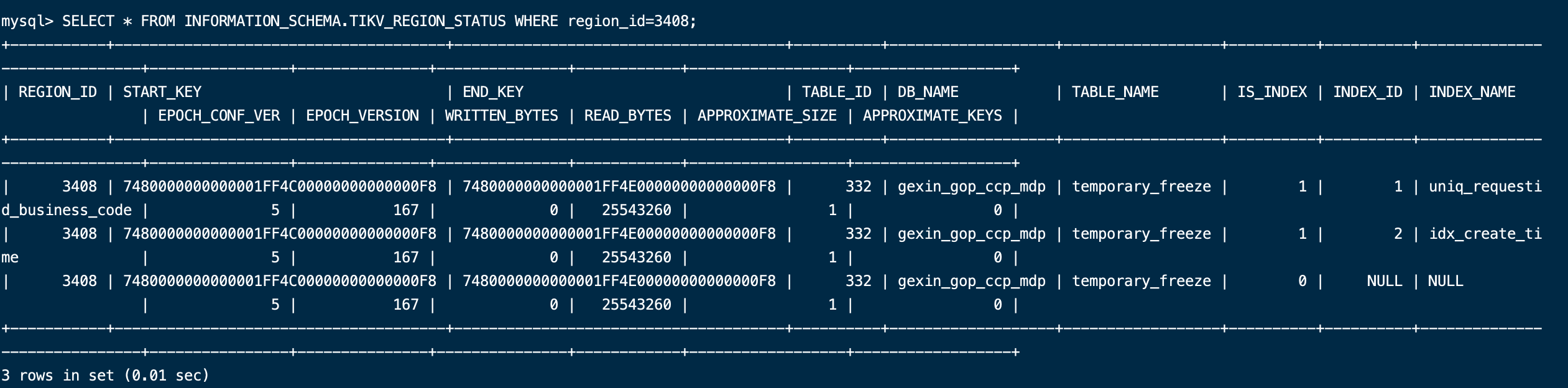
1 row in set (0.00 sec)

想请问大佬们我应该如何均匀切分
BETWEEN (lower_value) AND (upper_value)这两个值改取什么区间
【业务影响】
【TiDB 版本】
【应用软件及版本】
【附件】 相关日志及配置信息
- TiUP Cluster Display 信息
- TiUP CLuster Edit config 信息
监控(https://metricstool.pingcap.com/)
- TiDB-Overview Grafana监控
- TiDB Grafana 监控
- TiKV Grafana 监控
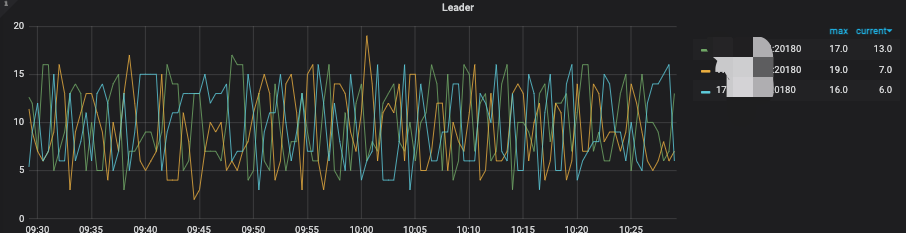
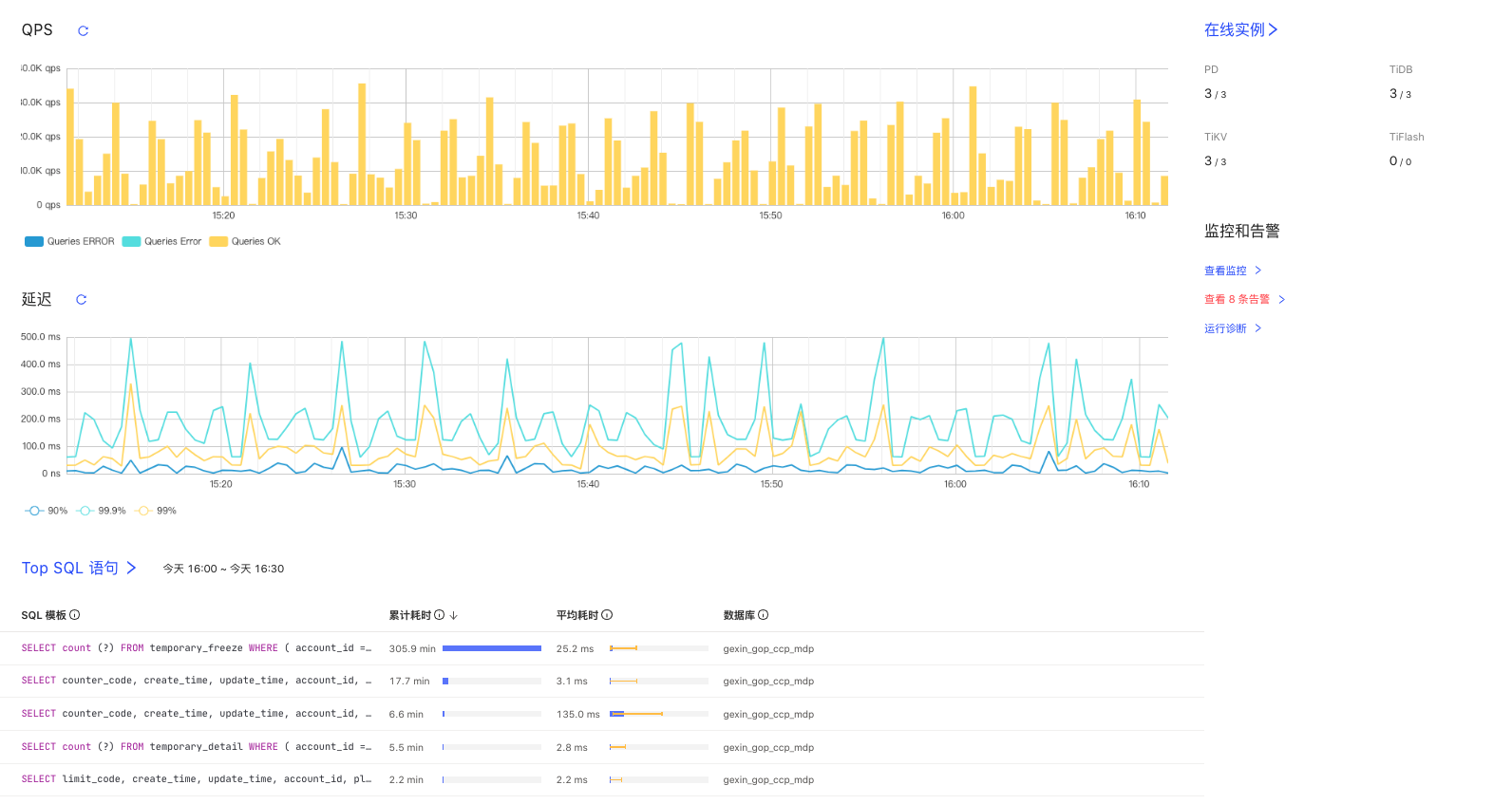
查看TIKV cpu有明显的热点现象

16号新业务上线高并发扫描几个小表 发现在空region一直有波动 尝试merge了region 把空region合并降低
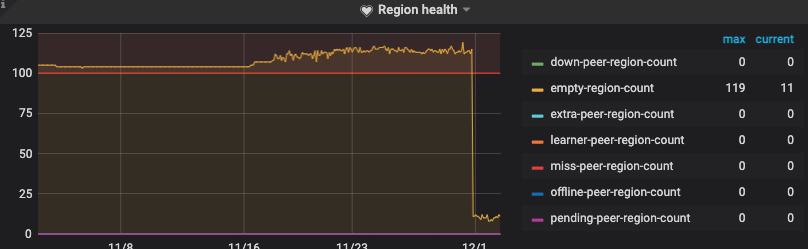
KV Backoff 有出现regionMiss 和staleCommand现象
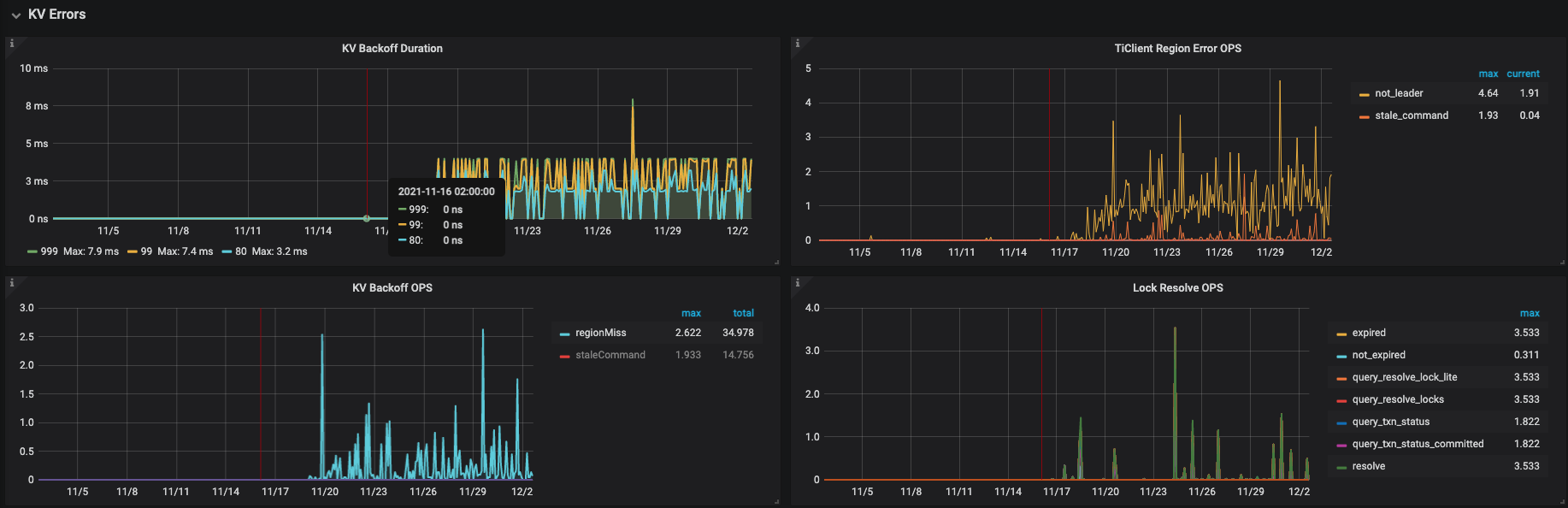
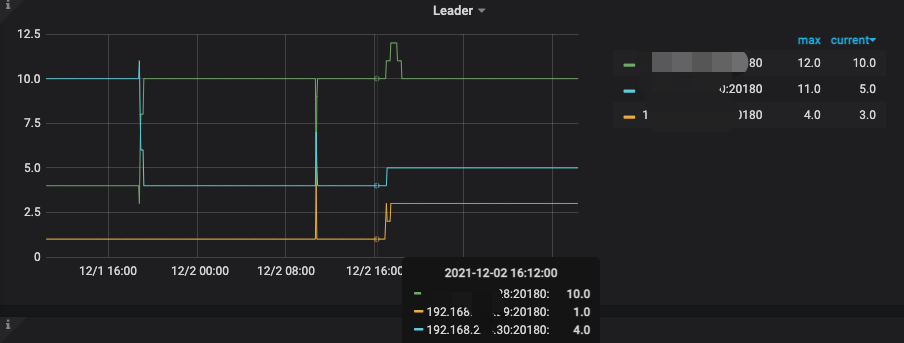
以及出现了很多not_leader的告警 怀疑是不是因为热点问题导致leader一直在2个kv节点飘来飘去
- PD Grafana 监控
- 对应模块日志(包含问题前后 1 小时日志)
tidb日志
[2021/12/02 16:23:52.622 +08:00] [INFO] [region_cache.go:840] [“switch region leader to specific leader due to kv return NotLeader”] [regionID=3432] [currIdx=0] [leaderStoreID=5]
[2021/12/02 16:23:54.538 +08:00] [INFO] [region_cache.go:840] [“switch region leader to specific leader due to kv return NotLeader”] [regionID=3232] [currIdx=0] [leaderStoreID=4]
[2021/12/02 16:23:55.828 +08:00] [INFO] [region_cache.go:840] [“switch region leader to specific leader due to kv return NotLeader”] [regionID=3400] [currIdx=0] [leaderStoreID=4]
[2021/12/02 16:23:56.817 +08:00] [INFO] [region_cache.go:840] [“switch region leader to specific leader due to kv return NotLeader”] [regionID=3396] [currIdx=0] [leaderStoreID=5]
[2021/12/02 16:23:58.142 +08:00] [INFO] [coprocessor.go:1034] [“[TIME_COP_PROCESS] resp_time:325.030949ms txnStartTS:429505495121526785 region_id:92 store_addr:172.25.2.164:20160”] [conn=5496678]
[2021/12/02 16:23:58.822 +08:00] [INFO] [region_cache.go:840] [“switch region leader to specific leader due to kv return NotLeader”] [regionID=3404] [currIdx=0] [leaderStoreID=5]
[2021/12/02 16:24:02.417 +08:00] [INFO] [region_cache.go:840] [“switch region leader to specific leader due to kv return NotLeader”] [regionID=3392] [currIdx=0] [leaderStoreID=5]
[2021/12/02 16:24:07.430 +08:00] [INFO] [region_cache.go:840] [“switch region leader to specific leader due to kv return NotLeader”] [regionID=92] [currIdx=0] [leaderStoreID=5]
[2021/12/02 16:24:12.999 +08:00] [INFO] [coprocessor.go:1034] [“[TIME_COP_PROCESS] resp_time:438.811324ms txnStartTS:429505498975043597 region_id:104 store_addr:172.25.2.165:20160 kv_process_ms:229 scan_total_write:100923 scan_processed_write:100922 scan_total_data:0 scan_processed_data:0 scan_total_lock:1 scan_processed_lock:0”] [conn=6321738]
[2021/12/02 16:24:29.167 +08:00] [INFO] [region_cache.go:840] [“switch region leader to specific leader due to kv return NotLeader”] [regionID=3376] [currIdx=2] [leaderStoreID=4]
[2021/12/02 16:24:38.866 +08:00] [INFO] [region_cache.go:840] [“switch region leader to specific leader due to kv return NotLeader”] [regionID=100] [currIdx=1] [leaderStoreID=1]
上传了其中一天的tikv日志
tikv.log.2021-11-19-19:10:28.754589497 (32.4 MB)

[2021/12/01 21:52:20.601 +08:00] [INFO] [process.rs:136] [“get snapshot failed”] [err=“Request(message: "peer is not leader for region 3380, leader may Some(id: 3383 store_id:
5)" not_leader { region_id: 3380 leader { id: 3383 store_id: 5 } })”] [cid=146419]
[2021/12/01 21:52:20.601 +08:00] [INFO] [process.rs:136] [“get snapshot failed”] [err=“Request(message: "peer is not leader for region 2840, leader may Some(id: 2843 store_id:
5)" not_leader { region_id: 2840 leader { id: 2843 store_id: 5 } })”] [cid=146420]
[2021/12/01 21:52:25.128 +08:00] [WARN] [endpoint.rs:537] [error-response] [err=“Key is locked (will clean up) primary_lock: 7480000000000000315F69800000000000000101323032313131
3136FF3232333130656237FF3034303135633932FF3234643933316632FF3030303230323930FF3461623700000000FB lock_version: 429488012004163987 key: 74800000000000014C5F728001400000744A0C loc
k_ttl: 20073 txn_size: 1 lock_for_update_ts: 429488012017270878”]
[2021/12/01 21:52:25.133 +08:00] [WARN] [endpoint.rs:537] [error-response] [err=“Key is locked (will clean up) primary_lock: 7480000000000000315F69800000000000000101323032313131
3136FF3232333130656237FF3034303135633932FF3234643933316632FF3030303230323930FF3461623700000000FB lock_version: 429488012004163987 key: 74800000000000014C5F728001400000744A0C loc
k_ttl: 20073 txn_size: 1 lock_for_update_ts: 429488012017270878”]
通过region key 命令找到 region
tiup ctl pd -u http://{pdip:port} -i
region key 7480000000000000315F698000000000000001013230323131313136FF3232333130656237FF3034303135633932FF3234643933316632FF3030303230323930FF3461623700000000FB
{
“id”: 6,
“start_key”: “”,
“end_key”: “7480000000000000FF0500000000000000F8”,
“epoch”: {
“conf_ver”: 5,
“version”: 2
},
“peers”: [
{
“id”: 7,
“store_id”: 1
},
{
“id”: 46,
“store_id”: 4
},
{
“id”: 67,
“store_id”: 5
}
],
“leader”: {
“id”: 7,
“store_id”: 1
},
“written_bytes”: 0,
“read_bytes”: 476,
“written_keys”: 0,
“read_keys”: 7,
“approximate_size”: 1,
“approximate_keys”: 1
}
查看一下 region 元数据信息,显示这是个空region
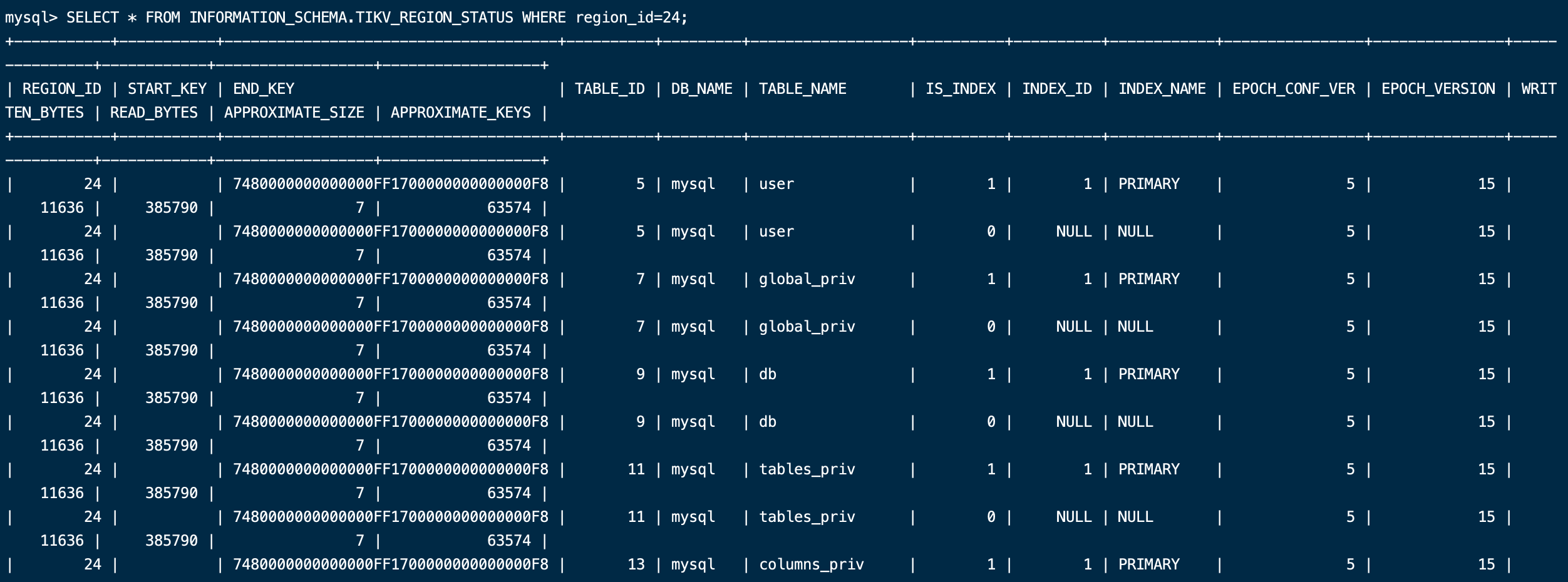
SELECT * FROM INFORMATION_SCHEMA.TIKV_REGION_STATUS WHERE region_id=6;
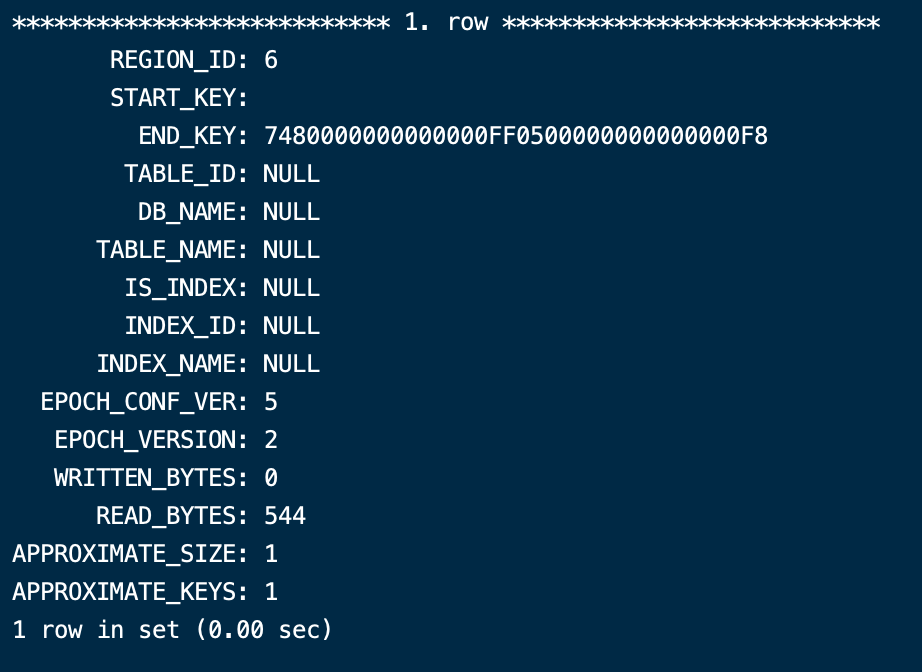
尝试进行合并region后
再次查询id 变成 了24 已经不是空region了
查看tikv日志报错还是挺多的
[2021/12/01 20:58:09.448 +08:00] [WARN] [endpoint.rs:537] [error-response] [err=“Key is locked (will clean up) primary_lock: 74800000000000014C5F72800140000074492A lock_version: 429487158555051004 key: 74800000000000014C5F72800140000074492A lock_ttl: 3001 txn_size: 1”]
[2021/12/01 20:58:09.451 +08:00] [WARN] [endpoint.rs:537] [error-response] [err=“Key is locked (will clean up) primary_lock: 74800000000000014C5F72800140000074492A lock_version: 429487158555051004 key: 74800000000000014C5F72800140000074492A lock_ttl: 3001 txn_size: 1”]
[2021/12/01 20:58:09.460 +08:00] [WARN] [endpoint.rs:537] [error-response] [err=“Key is locked (will clean up) primary_lock: 74800000000000014C5F72800140000074492A lock_version: 429487158555051004 key: 74800000000000014C5F72800140000074492A lock_ttl: 3001 txn_size: 1”]
[2021/12/01 20:58:09.463 +08:00] [WARN] [endpoint.rs:537] [error-response] [err=“Key is locked (will clean up) primary_lock: 74800000000000014C5F72800140000074492A lock_version: 429487158555051004 key: 74800000000000014C5F72800140000074492A lock_ttl: 3001 txn_size: 1”]
[2021/12/01 20:58:09.468 +08:00] [WARN] [endpoint.rs:537] [error-response] [err=“Key is locked (will clean up) primary_lock: 74800000000000014C5F72800140000074492A lock_version: 429487158555051004 key: 74800000000000014C5F72800140000074492A lock_ttl: 3001 txn_size: 1”]
[2021/12/01 20:58:13.961 +08:00] [WARN] [endpoint.rs:537] [error-response] [err=“Region error (will back off and retry) message: "peer is not leader for region 3380, leader may Some(id: 3382 store_id: 4)" not_leader { region_id: 3380 leader { id: 3382 store_id: 4 } }”]
[2021/12/01 20:58:13.961 +08:00] [WARN] [endpoint.rs:537] [error-response] [err=“Region error (will back off and retry) message: "peer is not leader for region 3380, leader may Some(id: 3382 store_id: 4)" not_leader { region_id: 3380 leader { id: 3382 store_id: 4 } }”]
[2021/12/01 20:58:13.967 +08:00] [WARN] [endpoint.rs:537] [error-response] [err=“Region error (will back off and retry) message: "peer is not leader for region 3380, leader may Some(id: 3382 store_id: 4)" not_leader { region_id: 3380 leader { id: 3382 store_id: 4 } }”]
[2021/12/01 20:58:13.968 +08:00] [WARN] [endpoint.rs:537] [error-response] [err=“Region error (will back off and retry) message: "peer is not leader for region 3380, leader may Some(id: 3382 store_id: 4)" not_leader { region_id: 3380 leader { id: 3382 store_id: 4 } }”]
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。